This article is more than 1 year old
OpenAI uses cunning code to speed up GPU machine learning
Sparse is more
Researchers at OpenAI have launched a library of tools that can help researchers build faster, more efficient neural networks that take up less memory on GPUs.
Neural networks are made up of layers of connected nodes. The architecture for these networks are highly variable depending on the data and application, but all models are limited by the way they run on GPUs.
One way to train larger models for less computation is to introduce sparse matrices. A matrix is considered sparse if it is filled with mostly zeroes. The blank elements in the arrays can be compressed and skipped in matrix multiplications and takes up less memory on the GPU.
The computational cost of carrying out operations is proportional to the amount of non-zero entries in the matrices, Durk Kingma, a research scientist at OpenAI, explained to The Register.
By having sparse matrices, it means that the extra computation saved can be used to build wider, or deeper networks that can be trained more efficiently and perform inference up to ten times faster.
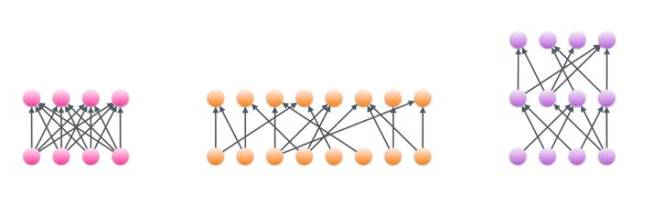
Dense network (left) can be made wider (center) or deeper (right) by adding sparsity. (Image credit: OpenAI)

Nvidia doesn’t really support block sparsity models, Kingma said. So a team at OpenAI decided to develop kernels - tiny programmes that compile software to run on hardware - optimised to build block sparse networks for the wider research community.
The researchers at Elon Musk’s AI research arm have used it internally to train long short-term memory networks to perform sentiment analysis on the text written for reviews for Amazon and IMDB.
“Our sparse model improves the state of the art on the document level IMDB dataset from 5.91 per cent error to 5.01 per cent. This is a promising improvement over our previous results which performed best only on shorter sentence level datasets,” they wrote in a blog post.
The kernels are written in CUDA and OpenAI have currently only developed a TensorFlow wrapper, so other researchers working across different frameworks will have to write their own wrappers. It also supports Nvidia GPUs only.
Scott Gray, a member of technical staff at Open AI, told The Register that “this can indeed be extended to other architectures that support smallish blockwise matrix multiplication. This includes most architectures I’m aware of, but Google’s TPU2 isn’t one of them.”
Although the results are promising, “since the kernels are still so new we do not have definitive view yet on when and where they help [neural network architectures]. In experiments, we provide some situations where it helps to add sparsity to the model. We encourage the community help explore this space further,” Kingma said.
Nvidia are aware of the work and is waiting for the code release so they can support it more generally, Gray added.
OpenAI’s work is similar to Taco, a piece of software created by researchers at the Massachusetts Institute of Technology that generates the code needed to process sparse matrices automatically.
You can play around with the block sparse GPU kernels here. ®
