This article is more than 1 year old
You've feasted for days but the courses keep on coming: Let's talk storage turkey
And finally sir, a wafer-thin mint... it is but wafer-thin
Tasty storage dishes for your Thanksgiving table include starter from Hazelcast, entree from HPE, a side from Qubole and dessert from Rubrik. Place your napkins in your lap and start dining.
Hazelcast Jet
In-memory data gridder Hazelcast has been working on its Jet product. Jet is a low latency, directed acyclic graph engine for big data processing and uses Hazelcast's in-memory data grid (IMDG).
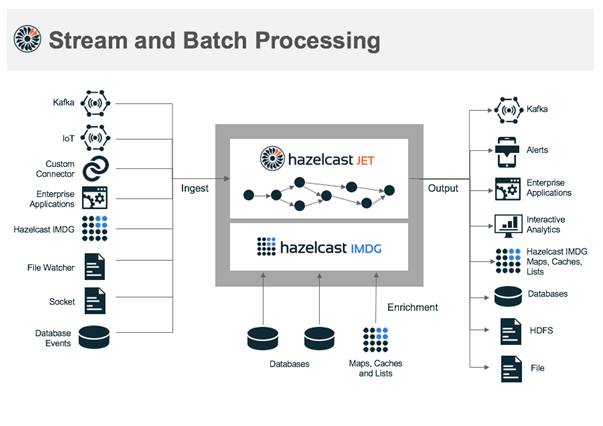
Jet is a single library with no dependencies, making it embeddable and deployed, removing the need for multiple systems. Hazelcast says typical use cases include online trades, sensor updates in IoT architectures, real-time fraud detection, system log events, in-store e-commerce systems and social media platforms.
Jet v0.5 features a Pipeline API for general purpose programming of batch and stream processing, and fault tolerance using distributed in-memory snapshots. They are distributed across the cluster and held in multiple replicas to provide redundancy.
If there is a node failure, it claimed, Jet uses the latest state snapshot and automatically restarts all jobs that contain the failed node as a job participant. No additional infrastructure, such as distributed file system or external snapshot storage, is apparently necessary.
Hazelcast claims that using data already held in IMDG versus external sources gives a 5 times performance enhancement. It expect its millions of IMDG users to start leveraging Jet’s capabilities to process the data they already hold in IMDG.
Jet benchmark comparisons with Apache Spark and Flink are reference-able here.
Cloud Bank Storage GA from HPE
This was originally announced as StoreOnce CloudBank in May this year and available through an Early Access program, which is now finished.
StoreOnce is HPE's single and multi-node, on-premises, deduplicating backup target arrays.
Cloud Bank Storage is for large volumes of long-term backup data. It is now generally available and can shunt backed-up 3PAR array data to an object storage backend, with four such archive/disaster recovery targets available: Scality on-premises, AWS and Azure object storage in the public cloud, and, lastly, any S3 interface repository.
There's a video giving the marketing spiel:
Click image to run the video
HPE says Cloud Bank Storage costs can be $0.001/GB/month for 100PB or more of data), and data is encrypted in flight and at rest. HPE says this is this is a 20x lower cost than existing public cloud services.
It supports HPE's Recovery Manager Central RMC)and 3PAR array its snapshots. HPE says RMC Express Restore only recalls data from the public cloud that does not exist locally, which could mean quite a lot of data.
If the local StoreOnce system goes down then the Cloud Bank system can be used for DR. Aged data in Cloud Bank can also be moved to Amazon Glacier or Azure Blob storage for archiving.
You can read an HPE blog on Cloud Bank Storage here.
We wonder if Cloud Bank Storage will eventually support Nimble arrays and the SimpliVity hyper-converged gear. Both would seem logical extensions of StoreOnce and Cloud Bank coverage.
Qubole
Big data-as-a-service supplier Qubole has announced a working technology preview of Spark-on-Lambda, enabling Apache Spark applications to run on AWS Lambda, the so-called serverless compute service.
Lambda is typically used for short duration, stateless functions. This complex and longer run-time technology prototype Spark-on-Lambda utilises massive compute burst capabilities of AWS Lambda by scanning 1TB of data on thousands of concurrent Lambda functions.
This line count operation on a dataset involving a read of 1TB data using 1000 Lambda executors took only 47 seconds. Given AWS's cost of $0.000002501 per 100ms compute time, the cost turns out to be $1.18.
Qubole has also run a 100GB sort from AWS S3.
Technical information can be found here and the code is available on Github at github.com/qubole/spark-on-lambda. There is a Qubole blog about it here that discusses the non-trivial changes to Spark needed to make it run successfully on Lambda.
Qubole will be at AWS Re:Invent 2017 in Las Vegas at Sands Expo booth 834 and Aria booth 201 if you want to find out more.
Rubrik
Rubrik has been designated a global ISV co-seller through the Microsoft Partner Network and will offer its hybrid cloud data management product on Microsoft Azure.
In addition, Rubrik has updated its platform to include support for Microsoft Azure Stack as well as support for application migration to Microsoft Azure through its CloudOn solution. ®
