This article is more than 1 year old
An AI can replace what a world leader said in his video-taped speech. This will end well. Not
Final stepping stone to irrefutable fake news?
Video Researchers have crafted algorithms that can blend an audio recording of someone talking with a video of them saying something else entirely – and create a new convincing lip-synched video with the replacement sound.
In other words, the resulting video carries the injected audio, rather than its original sound, and the frames are manipulated so that the speaker's face and mouth movements match the new audio.
You can be forgiven for seeing this as a vital stepping stone to creating the ultimate fake news – highly believable forged video evidence. Imagine taking a clip of someone important speaking at a private event, and using the aforementioned software to dub in a completely new script, voiced by a skilled impersonator or generated by another AI such as Lyrebird, and then distributing that fraudulent footage.
Thankfully, technology is nowhere near that level right now.
The video below demonstrates this machine-learning system's current capabilities: sound taken from an interview with Barack Obama is threaded through a different clip of him speaking, so it looks as though he's giving the same speech in a completely different setting.
Crafting a fake talking head is a tricky process. First, an audio sample is taken and fed into a recurrent neural network that spits out an outlining of the mouth. Next, texture is applied and blended into a target video.
To make it as natural as possible, the jaw line is warped to match the movements of the chin and mouth, reproducing the natural wrinkles and dimples in a person's face seen during speech.
The researchers, based at the University of Washington in Seattle, have published their results in a paper that will be presented at SIGGRAPH – the annual computer graphics conference this year taking place in Los Angeles on July 30 through August 3.
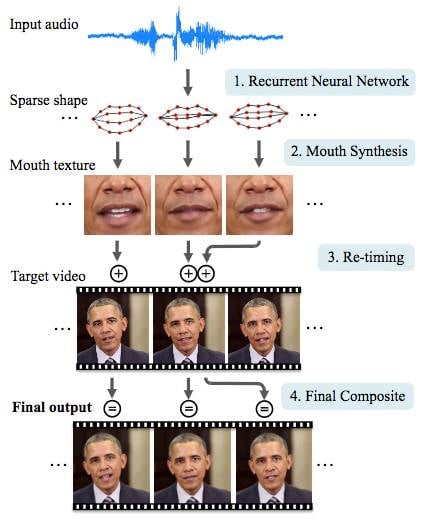
How the system works (Image credit: Suwajanakorn et al)
Supasorn Suwajanakorn, co-author of the paper and a recent doctoral graduate from the University of Washington, said: "People are particularly sensitive to any areas of your mouth that don't look realistic. If you don't render teeth right or the chin moves at the wrong time, people can spot it right away and it's going to look fake. So you have to render the mouth region perfectly to get beyond the uncanny valley."
The research was partly funded by Samsung, Google, Facebook, Intel and University of Washington Animation Research Labs.
It is hoped that it may come in handy when the connection between online video chats times out, making the video patchy and thus some software to fill in the gaps would be handy.
"When you watch Skype or Google Hangouts, often the connection is stuttery and low-resolution and really unpleasant, but often the audio is pretty good," said Steve Seitz, co-author of the paper and a professor in the department of computer science and engineering at the University of Washington. "So if you could use the audio to produce much higher-quality video, that would be terrific."
But it might be a while before something like that is possible. It takes hours of high quality footage – 17 hours for Obama and nearly two million frames – to train a system to translate different audio sounds into basic mouth shapes.
The training time could be decreased if the algorithms learn to recognize a person's voice and speech patterns with less data.
The neural network can only focus on one person at the moment. "You can't just take anyone's voice and turn it into an Obama video," Seitz said. "We very consciously decided against going down the path of putting other people's words into someone's mouth. We're simply taking real words that someone spoke and turning them into realistic video of that individual."
Welcome to the world of AI, where everything can be faked
But it is theoretically possible to put fake words into someone's mouth if different tools can be combined. Lyrebird, a startup specializing in AI speech synthesis, has already demonstrated how input text can be converted to an audio clip said in the voice of someone else. You can basically make world leaders say anything you want.
The demo features Barack Obama, Donald Trump and Hillary Clinton discussing Lyrebird and saying sentences they never actually said.
If an audio sample created using Lyrebird's technology could be fed into the algorithms that create the mouth shapes, then maybe the whole video can be faked. It would be difficult to get the subtle facial movements right, but don't worry, there's another system for that.
Researchers from the University of Erlangen-Nuremberg in Germany, the Max Planck Institute for Informatics in Germany and Stanford University in the US, have managed to recreate facial expressions and map them onto target videos in real time.
The researchers show how a target – the face of Arnold Schwarzenegger – can be manipulated so it mimics the source – an Asian female.
If there was a way to combine all these systems, maybe it would be possible to create completely fake broadcasts.
It's a problem the researchers from the University of Washington have thought about. They are also looking at how the process can be reversed – using the video instead of audio as an input – to see if they can develop algorithms to detect if a video is real or not. Which, it appears, might become necessary in the near future.
For now, we'll have to rely on fact checkers and eagle-eyed netizens, as was the case in the faked photo of Trump and Putin at this month's G20 summit. ®
