This article is more than 1 year old
Sorry to burst your bubble, but Microsoft's 'Ms Pac-Man beating AI' is more Automatic Idiot
Code hardwired to reach perfect 999,990 score
Analysis Back in a bygone era – September last year – Microsoft CEO Satya Nadella told a developer conference: "We are not pursuing AI to beat humans at games."
This week, we learned Redmond has done more or less that – lashed together a proof-of-concept AI that can trounce gamers at Ms Pac-Man, and snatch some headlines along the way. We're told the machine-learning system has obtained the perfect score of 999,990 in the arcade hit, compared to the human high-score record of 266,330.
This achievement seems a bit late. DeepMind's AlphaGo has defeated human Go experts. Libratus and DeepStack cleaned out poker professionals at heads-up no-limit Texas Hold’em. Vicarious whistled past competitors at Breakout. DeepMind's DQN taught itself how to play various Atari console games. And so on.
However, you can forgive the delay with Ms Pac-Man because it is a rather tricky game for machines to master. Playing it is like surviving a Friday evening in a digital nightclub: scoot around a dark maze, swallow pills, and avoid ghostly thugs to a repetitive electronic soundtrack.
Computers can't play this game well, since there are just too many possible game states to consider – 1077 configurations, apparently. It's not hard for an AI to find its way through a maze, but couple that with grabbing pills, dodging or eating ghosts, and collecting fruit for a high score, and it's suddenly tough work for an artificial brain. The electronic player has to appreciate and master secondary goals – efficiently scouring a maze for pills, avoiding ghosts or eating them, strategically sacrificing a life to get a difficult-to-reach pellet, and so on – all to achieve an overall primary goal.
Now Maluuba, a Canadian AI biz pursuing general AI through language processing, and recently acquired by Microsoft, appears to have cracked the challenge of building a bot that can trump humans at Ms Pac-Man.
Remarkable. @Microsoft’s @MaluubaInc beats Ms Pac-Man using unique reinforcement learning technique. https://t.co/ATO23AqHHc pic.twitter.com/o8G0vreCEh
— Steven Guggenheimer (@StevenGuggs) June 14, 2017
At the moment, it's trendy to teach software agents to play games using reinforcement learning. Here's how it works: every time a bot increases its score, typically by making a good move, it interprets this as a reward. Over time, the code works out which decisions and behaviors lead to more rewards. And while chasing these rewards, the bot becomes stronger and stronger, making better and better moves, until it becomes rather good at the game. Some games are better suited to reinforcement learning than others – it's not a one-size-fits-all solution.
Traditional reinforcement learning methods, which use a single agent player to tackle titles from Doom to StarCraft, are unsuitable for Ms Pac-Man. The large number of possible states means it's difficult to generalize the complex environment for a single agent to tackle, Rahul Mehrotra, program manager at Maluuba, and Kaheer Suleman, cofounder and CTO of the upstart, explained to The Register.
A paper published online on arXiv this week by Maluuba describes the team's winning Ms Pac-Man strategy, which uses something called a hybrid reward architecture (HRA) to pull off. Instead of a single bot trying to singlehandedly complete the game, the problem is shared between up to 163 sub-agents working in parallel for an oracle agent. This central oracle controls Ms Pac-Man's movements.
When the oracle agent finds a new object – a pellet, ghost or fruit – it creates a sub-agent representing that object and assigns it a fixed weight. Pills and fruit get positive weights, whereas ghosts get negative weights. These values are used to calculate, for each object, an expected reward for the oracle agent if it moves Ms Pac-Man in the direction of that object. So, for example, moving the character toward a ghost has a negative expected reward, whereas moving it toward a fruit or a line of pills has a very positive expected reward.
At each step in time in the game, the oracle aggregates all the expected rewards from its sub-agents, and uses this information to move Ms Pac-Man in the directions that maximize the total reward. She avoids the ghosts, she gets the pills and the fruit, and she gets the high score.
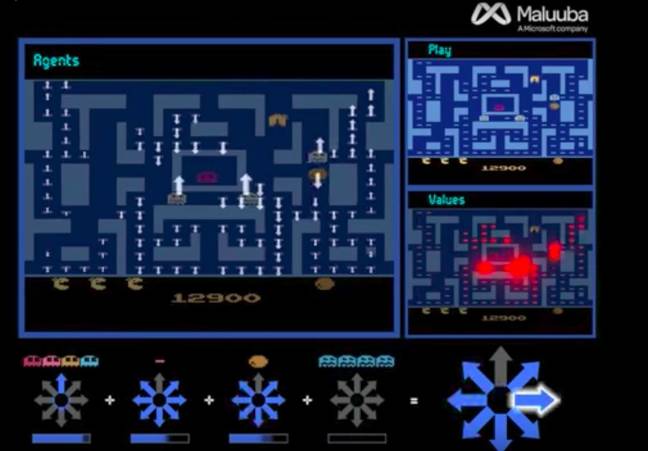
Screenshot of how agents help Ms Pac-Man gobble pellets and swerve ghosts
In effect, the combined agents guide Ms Pac-Man around the maze. It's important to note that the sub-agents do not control the environment – the ghosts still chase after her, for instance – they just provide her with the best strategies to take according to the current game state. After about 840 million video frames from the game, the HRA built a superhuman Ms Pac-Man player for four different maps.
So what's the problem?
It's all a bit of clever trickery. It's a bit of a hack. The crucial thing is that the reward weights are hardcoded into the software. Ghosts are set to -1,000. Pills and fruits are set a weight based on their in-game points. This is programmed in by the researchers. It means the AI hasn't learned very much at all: it hasn't learned that ghosts are bad and to be avoided because they cause Ms Pac-Man to lose her lives and ultimately the whole game, that pills need to be collected, that fruits are good and not stationary ghosts, and so on.
Other reinforcement learning systems found out through hours of trial and error that, for example in Space Invaders, they could press the fire button and sometimes earn points; that firing away made things disappear, also earning points; that moving and firing made more things disappear, earning more points; that moving to avoid being hit by enemy bullets let the player live longer, thus allowing it to gain more points; and so on. These systems learned from scratch the value of their decisions. Hit the ball, shoot the thing, get a reward, figure it out, get better.
Maluuba's HRA is, in all honesty, a proof of concept. It didn't have to learn the hard way. It was born knowing everything it ever needed to know. Until it can learn for itself from scratch, building up intelligence on its own from its environment, it's a preprogrammed maze-searching algorithm. Romain Laroche, one of the paper's coauthors, admitted the weights are defined "manually for the moment," adding they'll become dynamic at some point, hopefully. The fixed design is documented in the paper.
Basically, it's hardcoded to solve Ms Pac-Man: it may be tough to adapt the design to other scenarios without starting all over again with another specialized model. To be blunt, that means the algorithm isn't very valuable to anyone, unless you want to watch a computer solve Ms Pac-Man.
The project is part of Maluuba's push to explore how reinforcement learning under complex environments may be applied to natural language and conversations, according to Mehrotra and Suleman.
If we're being cynical, we would say Microsoft leaned on its acquisition to pop out a headline-grabbing demo to match DeepMind and other efforts. Sure, Maluuba's HRA involves some interesting programming and clever math. And yes, it looks neat, which is why journalists and thinkfluencers loved it. But let's be realistic: it's MAME on autopilot. ®
