This article is more than 1 year old
High-end backup kid Datos IO embraces relational, Hadoop data
Big data, big funding?
Datos IO has extended its on-premises and public cloud data protection to relational databases and Hadoop distributions.
Non-relational database protector and migrator Datos IO has updated its RecoverX distributed database backup product to v2.0 and added RDBMS and Hadoop support.
The RecoverX product is described as being app-centric and can back up applications' data and recover it at various levels of granularity – eg, rows/tables vs entire virtual machines or databases – and employs so-called semantic deduplication to increase storage efficiency. This understands the storage methodology for an application's data objects in database structures and can deduplicate them taking that into account.
According to the vendor, V2.0 adds:
- Migration of non-recovery SQL Server workloads to and between public clouds and on-premises data centres,
- SQL Server and other RDBMS data protection on premises or in the public cloud whether deployed on physical servers, virtual servers or hyper-converged systems,
- Data protection support for Hadoop distributions from Cloudera, Hortonworks and others,
- Scale RecoverX from a 1-node to 3-node and to 5-node software cluster to increase performance and availability, and back again if app needs so dictate,
- Extended policy management with adding/removing/pausing/resuming backups, backup NOW, and rule-based addition for dynamically generated database objects (eg, tables), and
- Enhanced operational montoring with analytics on data source patterns and data protection.
Datos IO has also built integrations with NetApp storage, ACI (application-centric infrastructure) with Cisco, and virtualised infrastructure with VMware. And it has new channel partners: Datalink, Groupware, and SHI
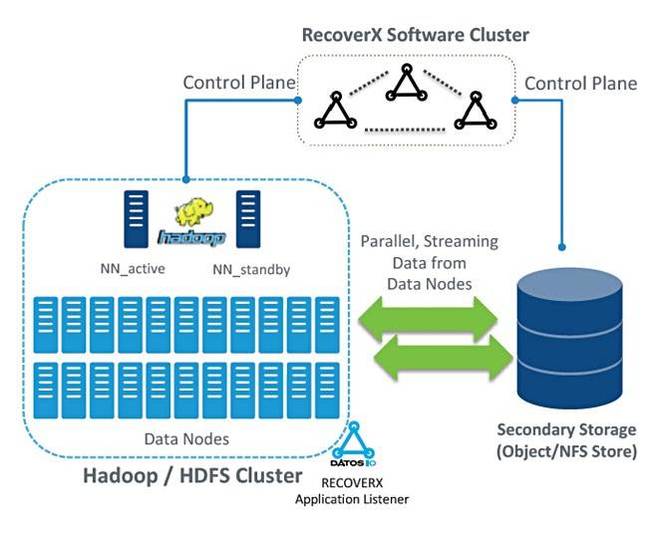
Datos IP and Hadoop
One of Datos IO's tenets is that media servers break native formats and are choke points in moving data at scale. We could say that Datos IO is a new kind of media server, one that embraces extended media serving and backup in a single product.
Tarun Thakur, Datos IO co-founder and CEO, said: “Cloud data management is about reinventing the control plane with cloud principles in mind – elasticity, application-centricity, and scale – because that’s what enables customers to manage, protect, mobilize, and harness the value of their data across all cloud boundaries.”
+Comment
Like Rubrik, Datos IO represents a new approach to data protection. In Datos IO's case, it is application-centric and so more easily usable by application admin staff, and also focused on moving such data within and between on-premises and public cloud environments.
By extending its original non-relational database support to relational databases and to Hadoop file systems, it can tick three of the big data organisation boxes and become a data protection and migration platform to its customers. We might imagine it could extend its coverage environment further and look at things like email too at some stage. It already supports Docker and Amazon machine images.
And it could also extend copy data management facilities and analytics using its central metadata catalogue.
We wouldn't be surprised if an after-effect of this major release is a fresh funding round to help fund Datos IO building out its business infrastructure. ®
