This article is more than 1 year old
Good job, everyone. We're making AI just as tediously racist and sexist as ourselves
Machines are more like us than once thought
Artificial intelligence can inherit the same racial and gender biases as humans do when learning language, according to a paper published in Science.
AI and machine learning are hot topics. Algorithms are becoming more advanced, providing us with better internet searching and recommendations to potentially help us diagnose diseases or drive cars.
There are advantages to relying on them – they don’t get tired and can power through the more mundane tasks that we find boring. But a closer inspection reveals that they aren’t perfect either, and can pick up the same flaws as their mortal creators.
Unconscious bias in humans has been studied with the implicit association test (IAT). The experiment asks participants to rapidly group words into certain categories – like family, career, male and female – to look for possible discriminatory beliefs around things like gender and jobs.
Researchers from Princeton University in the US and the University of Bath in the UK came up with a similar test for machine-learning algorithms. The Word-Embedding Association Test (WEAT) examines how closely the Global Vectors for Word Representation (GloVe) code associates two sets of words with each other – for example the word “food” is more likely to be affiliated with “spaghetti” than “shoe.”
GloVe is an unsupervised learning algorithm that maps words into vectors, a common technique central to natural language processing. Pre-existing word embeddings taken from the Common Crawl dataset, a corpus of 840 billion words (2.2 million different ones) extracted from web pages, were subjected to the WEAT test.
The same biases were examined, and results for 32 participants taking the IAT test and GloVe taking the WEAT test were compared. In hindsight, it’s not surprising considering that machines learn from data that reflects human culture.
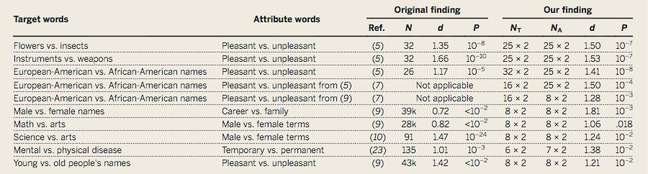
Left columns (IAT), right columns (WEAT). N = no. of subjects, NT = no. of target words; NA = no. of attribute words, d = effect size, P = P values
The results from both tests show striking similarities, implying that machines have the same biases as humans. European-American names are more likely to be associated with pleasant words than African-American names are. And “male” was linked more closely to “career” and “math” than “female” – which was more likely to be correlated with “home” and “arts.”
Studies have shown these racial and gender prejudices sway human behavior. A previous experiment showed that people with European American names were 50 per cent more likely to get an interview from a job application than people with African American names were, despite having identical CVs.
The results suggest that AI could be making these same mistakes if developers aren’t careful. Since biases are detectable in these algorithms, they could provide a way to combat the issue.
“If the system is going to take action, that action should be checked to ensure it isn’t prejudiced by unacceptable biases. So for example, you can – if you choose – be sure not to look at names or addresses on resumes, or to pick as many male as female resumes,” Joanna Bryson, co-author of the paper and AI researcher at the University of Bath, told The Register.
It’s not surprising that machines carry the same biases, considering they learn from data that reflects human culture. It’s an issue that is well known in data science. In November 2016, Joy Buolamwini, a postgraduate student from the MIT Media Lab at the Massachusetts Institute of Technology in the US, set up the Algorithmic Justice League to find out how to make algorithms fairer.
“The best thing to do is to keep trying to make culture better, and to keep updating AI to track culture while it improves,” Bryson said. ®
