This article is more than 1 year old
HDS has HCI – but it's not hyper-converged infrastructure
Containerised Content Intelligence... and it kind of/sort of converges data silos
HDS has announced Hitachi Content Intelligence, software which can search for and read content in multiple structured and unstructured data silos and analyse it.
HCI can extract data from the silos and pump it into workflows to process it in various ways. Users of HCI can be authorised so that sensitive content is only viewed by relevant people and document security controls are not breached. HDS says HCI can create a standard and consistent enterprise search process across the entire IT environment.
HDS says HCI connects to and aggregates multi-structured data across heterogeneous data silos and different locations. It claims HCI provides automated extraction, classification, enrichment and categorisation of all of an organisation's data. Note the "all" and realise that it is literally saying HCI can access all of an organisation's digital data. This is quite a job.
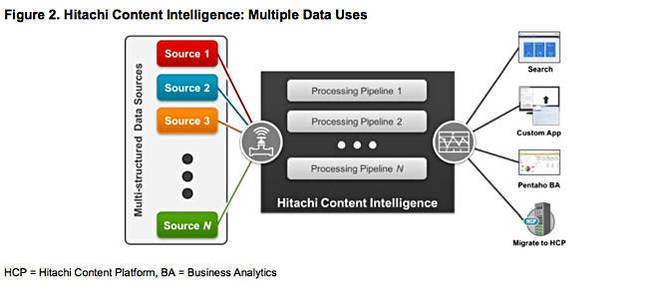
HCI is extensible with published application programming interfaces (APIs) that support customised data connections, transformation stages, or building new applications.
It forms part of HDS' object storage portfolio (HCP) which offers file sync and share, cloud storage gateways, and, now, search and analytics. HCI can run on physical or virtual servers, or hosted on public or private clouds. It is instantiated as a set of containers and provided to users as a self-service facility with support for detailed queries and ad hoc natural language searches.
It will deliver personalised results to these uses. Oh, and it can detect old data and stream it off to low-cost online archives.
All in all this is a significant chunk of content intelligence functionality. The claims are so great, if taken literally, it almost seems hard to take them at face-value.
We asked Scott Baker*, senior director of Emerging Technologies at Hitachi Data Systems, questions about HCI to clarify the "all" and other claims.
Email interview details
Which multi-structured silos does HCI support?
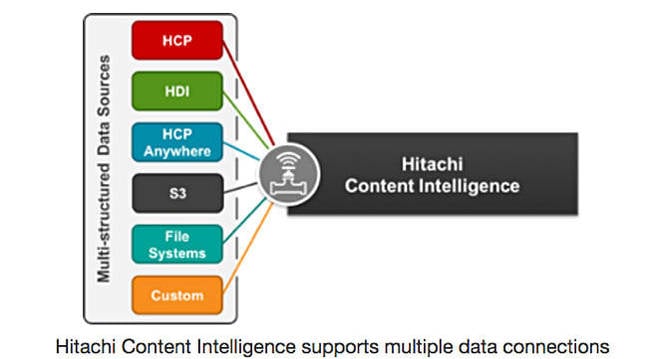
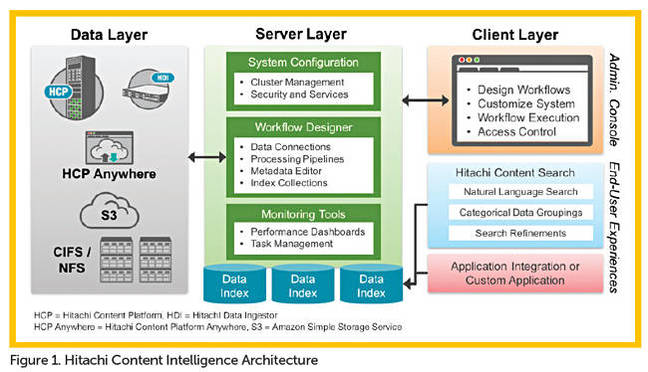
Scott Baker Content Intelligence ships with data connectors that support Hitachi Content Platform, Hitachi Data Ingestor, HCP Anywhere, S3-hosted repositories, and filesystem (CIFS/NFS). Content Intelligence is fully documented and includes a software developer’s kit with examples that partners or customers could use to create connections to data repositories not listed here.
How does it include support for detailed queries and ad hoc natural language searches? (ie. Can it deal with questions like "What content do I have across all my organization’s data stores dealing with X-rays?"
Scott Baker Content Intelligence allows users to navigate their data in the following ways: Facet-based navigation, or the ability to group similar data into one category. In your example, you could use a metadata tag during the processing of data to tag all file sources containing X-rays and make that a category that a user could quickly select to see all of the documents they are authorized for in the resulting list of documents.
Refinements can be used to help limit the results to specific attributes or ranges. For example, show me all files containing X-rays that were taken between Date1 and Date2, or for at these (n) facilities, etc. Pattern matching or data profiling can be used to specifically isolate files based on what they contain. For example, find all files associated with a given X-ray that contain data defined (by a pattern used during file processing) personally identifiable information.
Ad-hoc queries can be used as well in a natural language form with Content Intelligence providing type-ahead recommendations. The results will be ranked based on those files that most closely match the entirety of the query and display with hit-highlighting available in the results. A multi-word query is an implicit “OR” natural language search (i.e. “What” OR “content” OR “do”…), but can be converted to an “AND” when using quotation marks.
What is the search language?
Scott Baker The end-user query or navigations listed above ultimately result in a SolrQuerySyntax that is processed by the indexing engine of Content Intelligence and used to return the results that most closely match the query supplied. These results can be amplified by any additional parameters – such as boost values, relevancy rankings, exclusions or blacklisted files, etc.
How does it automatically extract, classify, enrich and categorize all of a customer's data?
Scott Baker When a workflow is created, data connections are defined and any data discovered in the connected repositories is processed by the different stages in the workflow’s pipelines. As part of those pipelines, content and metadata is extracted, content is classified based on data type or metadata values, steps can be used to normalize the data, additional metadata can be added to it, specific patterns can be searched for (say personally identifiable data), and more. There are 24 different processing steps you can conditionally take that include content analytics, transformation, enrichments, filtering, in-memory extractions, and of course the use of our SDK to create custom steps. These workflows can be executed on-demand or scheduled to run on a cyclic basis.
Really? All of a customer's data? Can you prove that assertion please?
Scott Baker Okay - a little bit of creative license here, but essentially the answer is still a yes. Proving the assertion is really down to the extensible nature of Content Intelligence. If you need a connector that we do not supply you can build it yourself. If you want to process data in a way that is not in the box, you can build it yourself. If you want to view the results in an interface that we do not provide, you can use the RESTful APIs to render the data in the way/app you want.
Where does it put this metadata it generates?
Scott Baker It depends on the intended purpose for processing the data. If the goal is to create a centralized index and not affect the data at the source, then all actions taken by the Workflow and the resulting metadata and content extracted are stored in a Solr index. We use specific Solr capabilities to balance the index across multiple instances to make the searches more performant and to protect the indices from loss. This means that you can also has the index closer to users who are conducting the exploration or discovery activities.
Data connectors for HCP and S3 locations can also have “WRITE” actions associated to them - including: the data, metadata, custom metadata, set retention, apply retention hold, conduct privileged deletes, perform privileged holds. This is a great use-case for those who want to use Content Intelligence to migrate their data in an intelligence way and associate all the custom metadata created when it is written to its new repository.
Does it look inside content?
Scott Baker Yes - Content Intelligence can perform a surface level content identification, sub-surface (the magic header of a file), or deep content identification. With respect to the extraction, transformation, pattern matching, profiling, and loading, Content Intelligence will use the file in its entirety. This includes file containers (pst, zip, tar, mbox, etc.) where each document is extracted and processed independently.
The release says HCI will "Minimize business risk and exposure from data that is inaccessible, dark, or has been lost," Not completely fix the risk then. Is that correct?
Scott Baker That is correct - to completely fix the risk implies a degree of automation. At this point in the product’s maturity, what we are doing is making the user aware, but the action is theirs to take the appropriate steps to minimize the risk. The only exception here is that if I use a data connector for HCP or S3 as a means to migrate data from these hidden and rarely accessed repositories, then I can apply degrees of automation to remove the risk by applying the management and governance features of HCP.
It's a tiering mechanism to detect and suck off old data to what and how?
Scott Baker Users can build a workflow that connects to their primary data and conditionally isolate files (i.e. all files that have not been accessed in the last 30 days) and migrate those to HCP.
Is HCI software that runs on a server? What servers?
Scott Baker Content Intelligence is a software only solution. It can be deployed on bare-metal, in virtual machines, or in the cloud (i.e. AWS). It requires a 64 bit distribution of Linux capable of running Dockers 1.10 or newer. This gives you the freedom to deploy Content Intelligence on the platform that makes the most sense to your use-case. A minimum set of requirements includes at least four cores, 16GB of RAM, and 64GB of disk space. Obviously, the more RAM you offer it, the more you processes and requests each instance can handle.
How does it deliver personalized results that are tailored to the individual user?
Scott Baker The resulting index(es) created from a Workflow can be customized to control how the results are displayed. In the Workflow designer, you would define query settings that are tied to a specific user, or group users, that determine what indexes that can query, what fields they can see, what kinds of facets they can use navigate, what kinds of refinements they can use, and ultimately how the result set is rendered in the end-user applications.
What extensibility does it have with which published APIs that support customized data connections, transformation stages, or building new applications?
Scott Baker The product ships with a fully documented software developers kit (to include example code) to build data connections and/or processing stages. We also have a fully published RESTful API set for data access, which our end-user application (the search app) uses.
What is HCI's price and availability please?
Scott Baker Content Intelligence is licensed by core, where each instance of Content Intelligence requires a minimum of four cores. Should you want a more performant and scalable environment, you can run Content Intelligence in a clustered configuration. A cluster has a minimum of four nodes (3 masters and 1 worker) but can be much larger. List price per core is $13,300 USD, but please keep in mind that is list and often discounted.
Product GA is December 16. ®
* Scott Baker has blogged on HCI here.
