This article is more than 1 year old
Iguazio: Made from Kia parts but faster than a Ferrari with 1,000 drivers
Big Water boys take on Big Data
Backgrounder We introduced Iguazio in September. Assembled hacks were given a deep dive into the company at its Herzliya, Israel HQ this week.
The name refers to the Iguazu falls in South America; it means big water, and we had a technology drenching, some of which I remembered when I came up gasping for air.
The starting point is that a Big Data analytics workflow, from original data ingestion of billions of items through to analysis runs, typically involves multiple cloud-native applications, stateful and stateless services, multiple data stores, and data selection/filtering into subsequent stores in what is a multi-step pipeline.
The transitions between the steps takes time and effort and, compared to traditional, structured database applications with relatively simple process pipelines, is slow and inefficient. Iguazio says this typical multi-step Big Data process pipeline is first generation stuff. A second generation version involves a unified data model enabled by complex metadata processing.
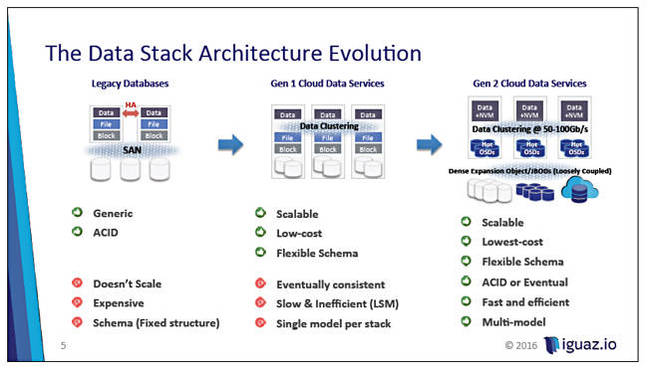
Iguazio scheme
By having this metadata processing done using clustered servers, DRAM and NVMe flash storage it is quick and the overall Big Data processing time dramatically reduced. Think hot data stored/cached in flash and a dense disk backing store for the data points. This scheme provides lower cost and greater scalability.
The company says it has implemented software-defined data, with an enormous increase in the granularity of realtime data analysis. It has implemented a file system above the database and uses this for querying. There is an in-memory metadata database, making metadata operations as fast as possible.
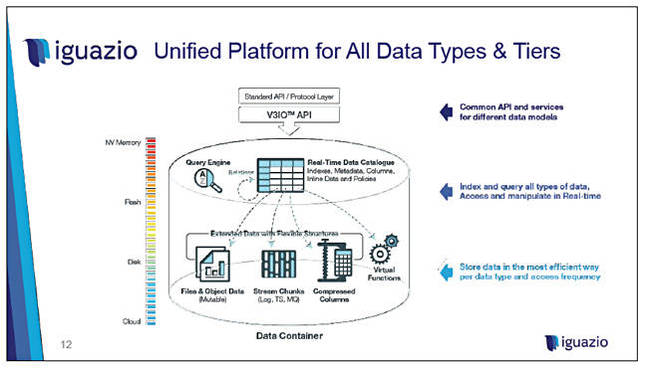
We might imagine Iguazio is like a Coho Data doing storage processing in memory.
You can store different types of data in the most efficient way because the system knows what sort of data it is.
There are pointers to attributes so the system doesn't need to retrieve an entire object to query it. An attribute could specify a stored object is audio, video, object, stream chunk, whatever. If it's a video then metadata could be on a per-frame basis.
Iguazio is saying it has has reinvented the storage array for the cloud-native world with its V3io product. It has taken Linux OS and de-serialised it. There are no locks in it and their storage OS features predictive pre-fetching of data into memory.
Racking Iguazio
A customer might start with a cluster of three highly available V3io controller nodes and 24TB of flash for the three. If one node fails we still have two with replication.
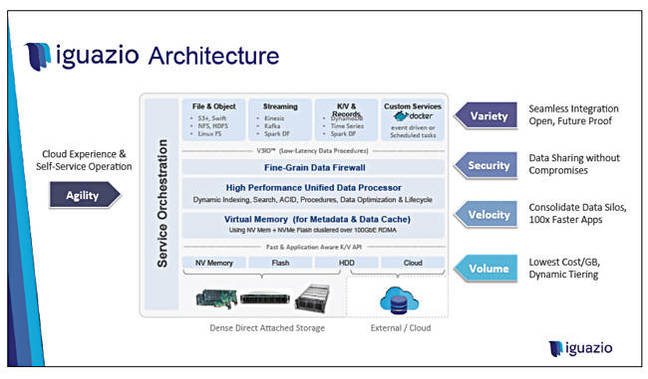
An Iguazio rack could contain a set of dense servers providing an API/protocol gateway front end providing app services. Below these there would be a pair of 10/40/100GB switch enclosures. And next the clustered nodes with their flash storage.
Below these in the rack are dense JBODS, dense disk enclosures providing system object pools, with 72 x 2.5in 4TB SAS disk drives; and up to 1,150TB total capacity. Iguazio uses a key:value API to talk to the JBODs.
Iguazio uses RDMA/Ethernet inside its array. Can it use it to talk to accessing clients? No, but it could expose it if client's data centre has an RDMA facility.
The JBODs could be NVMeF-attached arrays. Iguazio prefer key:value store access to JBODS and not block. But if an NVMeF array was used then Iguazio would put a KVS abstraction layer over its block i/f. The JBODs storage function could also be provided by external pools; S3 or Kinetic drives or NFS, but data access would not be so fast. These external pools could be used to tier-off cooling data using, for example, the S3 API. Admins could uses SQL query with filters to get metadata to find objects that meet a data lifecycle rule, and then backup, scan/convert objects.
Iguazio says it has already tested 3D XP0int SSDs and is ready to use them.
The company is focussed on enterprise Big Data workloads but has some interest in HPC use. It says HPC people don't need high availability. End users (data scientists) can directly use the Iguazio array as their analysis processing engine.
Iguazio's software architecture and implementation is rich and detailed and, for a technically minded system architect, well worth diving deeper into than I could go so you could appreciate the ramifications of the design.
Founding and funding
The company was founded in 2014 and pulled in a $15mn A-round of funding in 2015. There were six founders; quite a large group:
- Asaf Somekh – CEO ex-Compass-EOS/Mellanox/Voltaire
- Yaron Haviv – CTO ex-Mellanox
- Ori Modal – VP R&D
- Orit Nissan-Messing – Chief Architect
- Yaron Segev – founding investor, board member. Ex-co-founder and VP Tech XtremIO/Voltaire
- Eran Duchan – R and D
Iguazio has some 50 employees spread across Israel and the USA and its product is in early deployment at several customers in financial services, IoT and cloud service providers, which represents a rapid development schedule.
Comment
Iguazio says its on-premises array cost $0.03/GB/month over three years, which is cheaper than Amazon, and can deliver 2 million IOPS. As well, it has engineered a web server capable of 500,000 IOPS and does fine-grained SW-defined data processing at 100Gbps rate.
It seems to me that Iguazio has built a storage array, a storage application server really, out of Kia components which is faster than a Ferrari where the slowest element is the driver – but it can support 1,000 drivers.
To be honest, the system is so richly designed and detailed you need to be up to speed with modern Big Data analytics data ingestion, transformation, and analysis processing details to appreciate the nuances and sophistication of Iguazio's design and implementation – and I'm not.
If this is your bag, get yourself a virtual wetsuit and let yourself be drenched by a demo and presentation by Iguazio's waterfall wizards. You will be impressed. That's a given. ®
