4
This article is more than 1 year old
Building iRODS to take load off scientists' back
Panasas and WD/HGST go balls out for parallel file access and object storage integration
Fri 7 Oct 2016 //
08:35 UTC
Panasas and Western Digital are combining high-speed data access and low-cost, bulk data storage for life sciences researchers through a partnership and integration exercise centred on the open-source data management software iRODS.
The use of the systems is described here. This is how it works:
- Lab equipment generates data and open source iRODS (Integrated Rule-Oriented Data System) software gives it a thorough metadata going over, before moving the data from local workstation storage to an HGST Active Archive System, a disk-based object storage array optimised for high capacity and low cost storage with consequent low speed access. Amazon’s S3 protocol is used for the data movement.
- An iRODS metadata catalog stores info about every file, every directory, and every storage resource in the iRODS data grid structure, and this aids data discovery. This grid structure federates zones, such as local workstation stores, the Active Archive System and a Panasas ActivStore array.
- When life sciences researchers then need to process some or all of this disk archive-held data it is fetched, using iRODS rules and dumped into a Panasas ActiveStor array with its parallel file system access software.
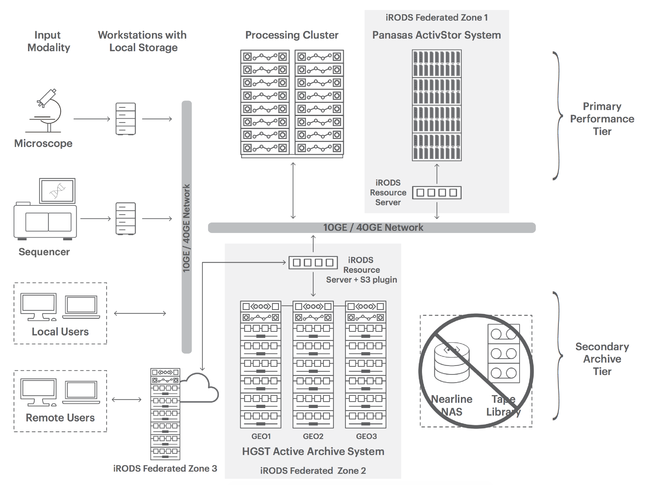
- Once the data is in the ActivStor them high-performance computing (HPC) servers access it in parallel and do their processing thing. In effect the Active Archive System is used to avoid storing all the data in the ActivStor, which would be unnaffordably expensive.
This multi-tiered, multi-product, system to enable fast access to a subset of a vast information store reminds us of Quantum’s StorNext, which can similarly use object storage (Lattus) as a backing store. Panasas competitor DDN has object storage (WOS) in its product set and this can be used as a backing store for its HPC arrays. See also this Fujitsu array and iRODS. ®
