This article is more than 1 year old
DataCore dominating SPC-1 benchmark on price–performance
Parallel server software supercharges commodity servers
DataCore has answered criticism of its Parallel Server SPC-1 benchmark [PDF] – that it was not applicable to enterprises, as it lacked high availability (HA) – by running an HA version that is the fifth-best SPC-1 benchmark performer ever.
It is also the third-best ever price–performance score on the benchmark, with the top three scores all DataCore systems using its parallel server software technology.
The software used the latest PSP5 parallel server code release, which delivers more IOPS than the prior PSP4 version. The earlier single-node PSP4 configuration produced an average response time of 0.32 milliseconds at 459,290.87 SPC-1 IOPS with an industry-best price–performance of $0.08 per SPC-1 IOPS.
The HA config with PSP5 code lowered the average response time by more than 30 per cent to 0.22 milliseconds at 1,201,961.83 SPC-1 IOPS, more than double the throughput, with a price–performance of $0.10 per IOPS.
DataCore chairman Ziya Aral said, "That should help to put an end to the myth that it is Fibre Channel latencies that slow down SAN performance. In our experience, the opposite is true. DataCore Parallel I/O speeds up everything it touches – the fabric most assuredly included."
The company points out that competing SPC-1 storage products take up multiple 42U racks and many square feet of floor space, whereas the DataCore configuration occupies just 12U of one rack.
Here are the top SPC-1 benchmark scores summarised:
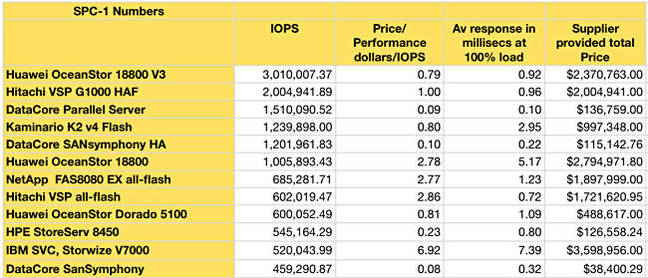
Among other top-scoring systems costing more than a million dollars, the DataCore ones stand out for costing less than $150,000, a tenth or more less than Huawei and Hitachi arrays. DataCore's configuration used a fully redundant, dual-node Fibre Channel Server SAN configuration running its SANsymphony storage software on a pair of off-the-shelf Intel-based servers, two Lenovo x3650 servers. Each had 2 x Xeon 2.3GHz E5-2696 v3 processors with 18 cores and 45MB Intel Smart Cache, with 758GB of main memory. They ran Windows 2008 R2 Enterprise Server w/SP1.
These were synchronously mirrored using 16Gbit/s FC. The storage in each was 18 x 240GB 6Gbit/s Samsung SATA SSDs and 4 x 300GB 12Gbit/s HGST SAS disk drives. These weren't even totally all-flash systems.
A 2TB 5,400rpm SATA disk drive was the system disk drive for one system; it was a 500GB SATA SSD for the other server.
DataCore's Eric Wendel, Director, Technical Ecosystems Development, says the top scorer, a Huawei system, is not an HA configuration. The second-placed Hitachi VSP G1000 is an HA setup.
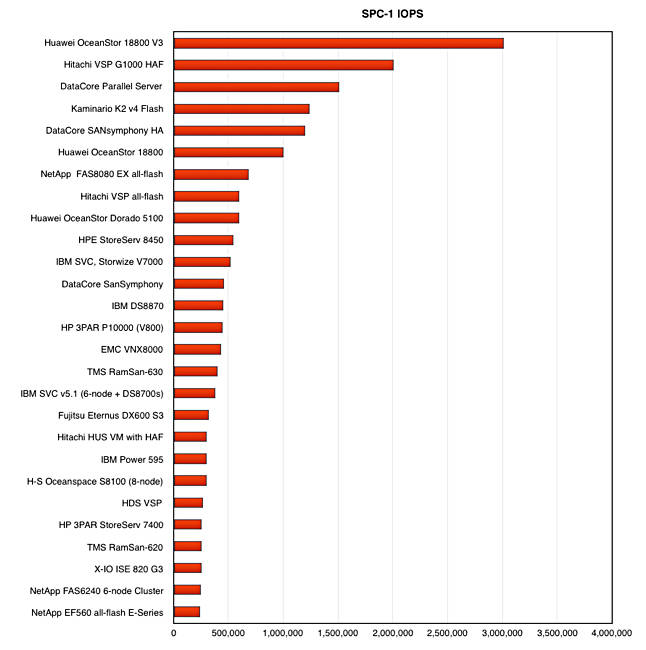
Here are the top SPC-1 scores charted:
And here are the top SPC-1 price–performers:
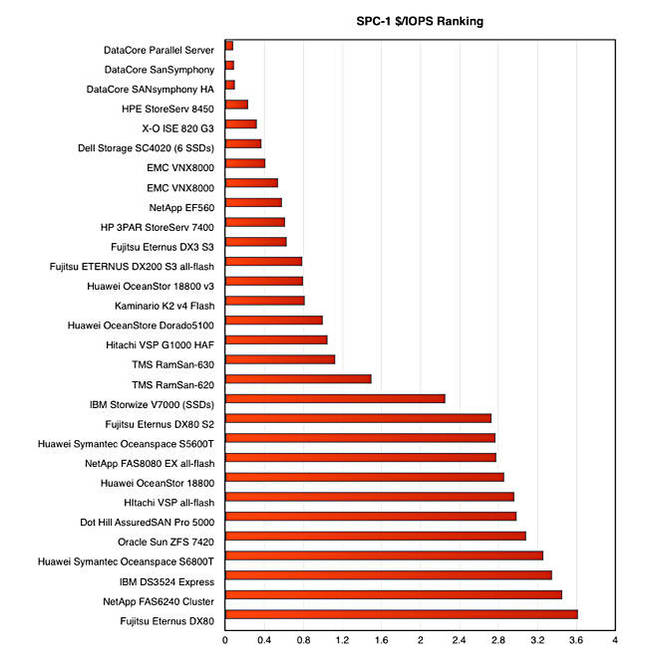
DataCore thinks its "new results are sure to send a wake-up call to a storage community obsessed with debating how to speed up latency-sensitive applications."
Wendel points out that, looking at the Hitachi VSP G1000 (and HP's OEM'd equivalent) response times at various system loadings, "You can arbitrarily choose any response time, and DataCore will deliver 5x to 10x more IOPS at that response time ... If ~220 microseconds is a desired response time, then the Hitachi ... can only manage 200K IOPS@220us while DataCore is delivering 1.2 million IOPS@217us."
He says DataCore at 100 per cent full IOPS utilization is faster than Hitachi at 10 per cent utilization.
El Reg just wonders how much longer other storage vendors, both array and converged/hyper-converged, can carry on apparently ignoring DataCore's parallel server tech while it almost casually blows their products out of court in SPC-1 terms. They must suspect, as we do, that theoretically, DataCore could produce a configuration that could top three million IOPS and take the absolute SPC-1 benchmark crown away from Huawei.
Imagine that – a $2.4 million system crucified by one costing, what, a fifth as much?
And then ... populate the servers used with NVMe flash and see the suckers really fly.
Another thought: 12Gbit/s SAS and NVMe PCIe interconnects to all-flash systems are kludges to get around the fact that server IO isn't being processed by multiple cores. IO processing is CPU-bound and not IO-bound. Parallelize IO processing and existing HW and SW IO stacks can fly, because they will no longer be CPU-bound.
The entire recent investment in developing all-flash arrays could have been avoided simply by parallelizing server IO and populating the servers with SSDs. Is this fantasy? Look at the SPC-1 numbers and charts above and think about that question.
Check out the full SPC-1 DataCore disclosure report here. ®
