This article is more than 1 year old
Inside Nvidia's Pascal-powered Tesla P100: What's the big deal?
Under the hood of the HPC, AI workhorse ... which'll be coming to a desk near you
GTC16 So there it is: the long-awaited Nvidia Pascal architecture GPU. It's the GP100, and it will debut in the Tesla P100, which is aimed at high-performance computing (think supercomputers simulating the weather and nuke fuel) and deep-learning artificial intelligence systems.
The P100, revealed today at Nvidia's GPU Tech Conference in San Jose, California, has 15 billion transistors (150 billion if you include the 16GB of memory) and is built from 16nm FinFETs. If you want to get your hands on the hardware, you can either buy a $129,000 DGX-1 box, which will gobble 3200W but deliver up to 170TFLOPS of performance when it ships in June; wait until one of the big cloud providers offers the gear as an online service later this year; or buy a Pascal-equipped server from the likes of IBM, Cray, Hewlett Packard Enterprise, or Dell in early 2017. The cloud goliaths are already gobbling up as many of the number-crunching chips as they can.
So no, this isn't aimed at gamers and desktop machines; it's being used to tempt and tease scientists and software engineers into joining Nvidia's CUDA party and run AI training systems, particle analysis code and the like on GPUs. "Deep learning is going to be in every application," Jen-Hsun Huang, co-founder and CEO at Nvidia, told the conference crowd.
That said, unless Nvidia pulls a WTF moment out of its hat, these Pascal designs will make their way into the electronics of ordinary folks' computers. The architecture has a few neat tricks up its sleeve if you're not already aware of them. Here's a summary of the best bits.
Generous to a fault
Since CUDA 6, Nvidia's offered programmers what's called Unified Memory, which provides (as the name suggests) a virtual address space shared by the host's GPUs and CPUs. This method gives developers uniform access between the GPU and CPU cores. The maximum size of the unified memory space is the same size as the GPU's memory.
Now with Pascal, the GP100 can trigger page faults in unified memory, allowing data to be loaded on demand. In other words, rather than spend a relative age shifting huge amounts of material to the GPU's memory, the code running on the graphics processor assumes the data is already present in the GPU memory and accesses it as it requires. If the memory is not present, a fault is generated and the page of data is migrated from wherever it was supposed to come from.

For example, if you allocate a 2GB array of shared memory, and start modifying its contents using a CPU core running a modern operating system, the CPU will fault on accessing the virgin allocation and map in physical pages to the virtual space as required. Then the GPU starts writing to the array. The pages are physically present for the CPU but not for the GPU, so the GPU migrates the contents of the array into its physical memory, page by page, and the pages are marked as not present for the CPU.
When the CPU next modifies the array, it faults, and pulls them back from the GPU. This happens transparently to the software developers, and provides data coherence in the uniform memory. It also allows the unified memory space to be larger than the GPU's physical memory, because the data will be loaded on demand. As such, the unified memory address width is 49 bits.

Remember, this heterogenous model is really aimed mostly at scientific and AI workloads handling large and complex bundles of data: games and low-latency apps won't be expected to page on demand all the time. It's expensive handling page faults – especially if the data has to be migrated over PCIe. But it means boffins get a great deal more simplicity and efficiency from the flat memory model. Programmers can, in their code, drop hints to the system on how much memory should be prefetched by the GPU when a new kernel is launched to avoid a storm of page faults. The GPU can also service groups of page faults in parallel, rather than tediously dispatching them one by one. Each page can be up to 2MB in size.
Nvidia is also said to be working with Linux distro makers to bake further support for unified memory into systems: software should, in future, just call a generic malloc() function, and then pass the pointer to the GPU, with the underlying operating system taking care of the allocation and paging, rather than using a special CUDA allocation call.
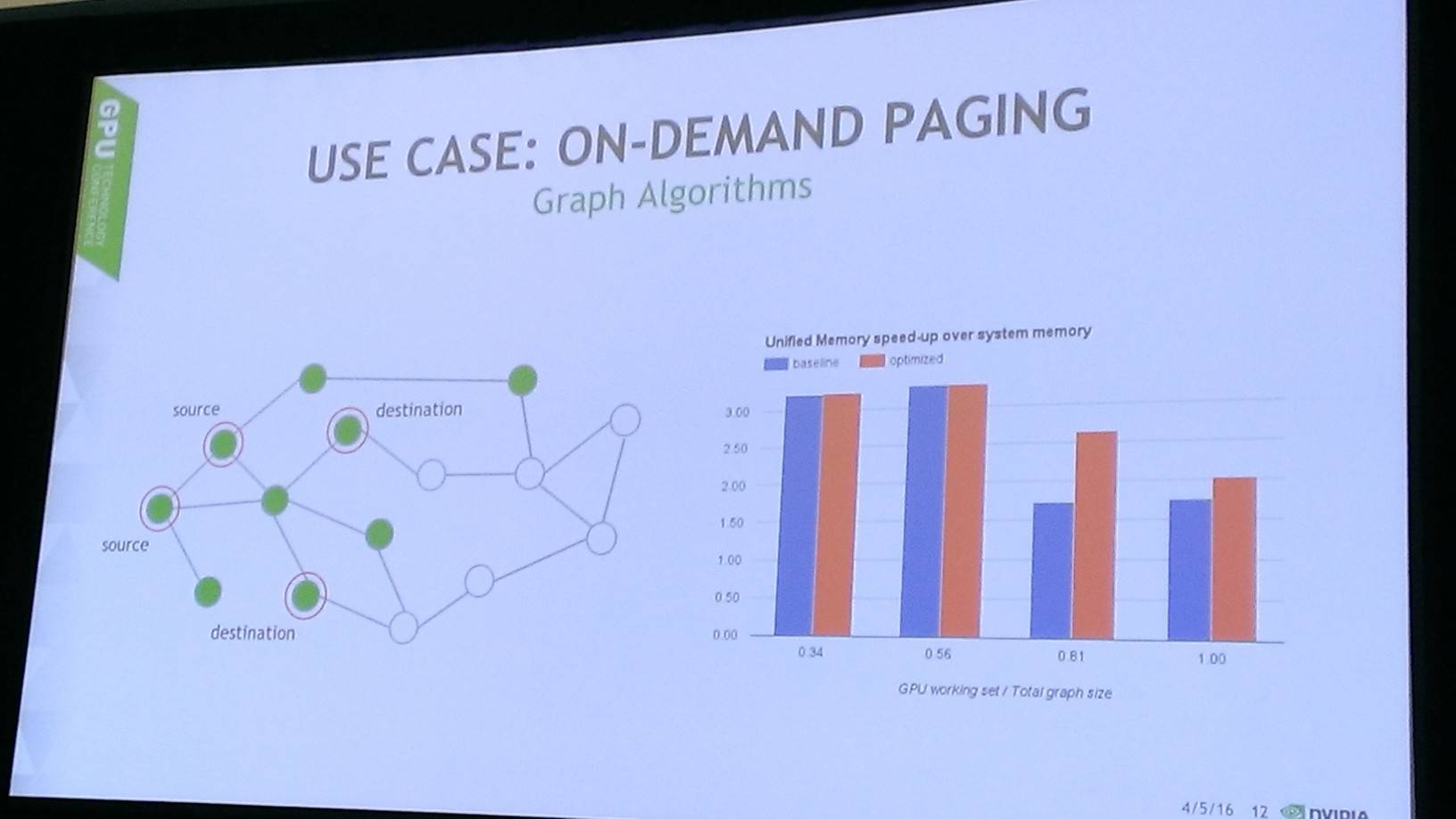
Implementing data coherence using page faults is rather nut meets sledgehammer, nuts falls in love with sledgehammer, sledgehammer does its thing. Sometimes you gotta do what you gotta do (like, perhaps, wait for Volta).
Down to the core
The GP100 has 3,584 32-bit (single precision) CUDA cores, and 1,792 64-bit (double precision) CUDA cores, per GPU. The 32-bit cores can also run 16-bit (half precision) calculations.
The L2 cache size is 4MB and there's 14MB of shared registers that can shift data internally at 80TB/s. The base clock speed is 1.3GHz, boosting to 1.4GHz and 5.304TFLOPS with double-precision math (21TFLOPS using half-precision). The TDP is 300W. The cores are arranged into 56 SMs (streaming multiprocessors), each of which look like this:

It's dangerous to go alone, NVLink
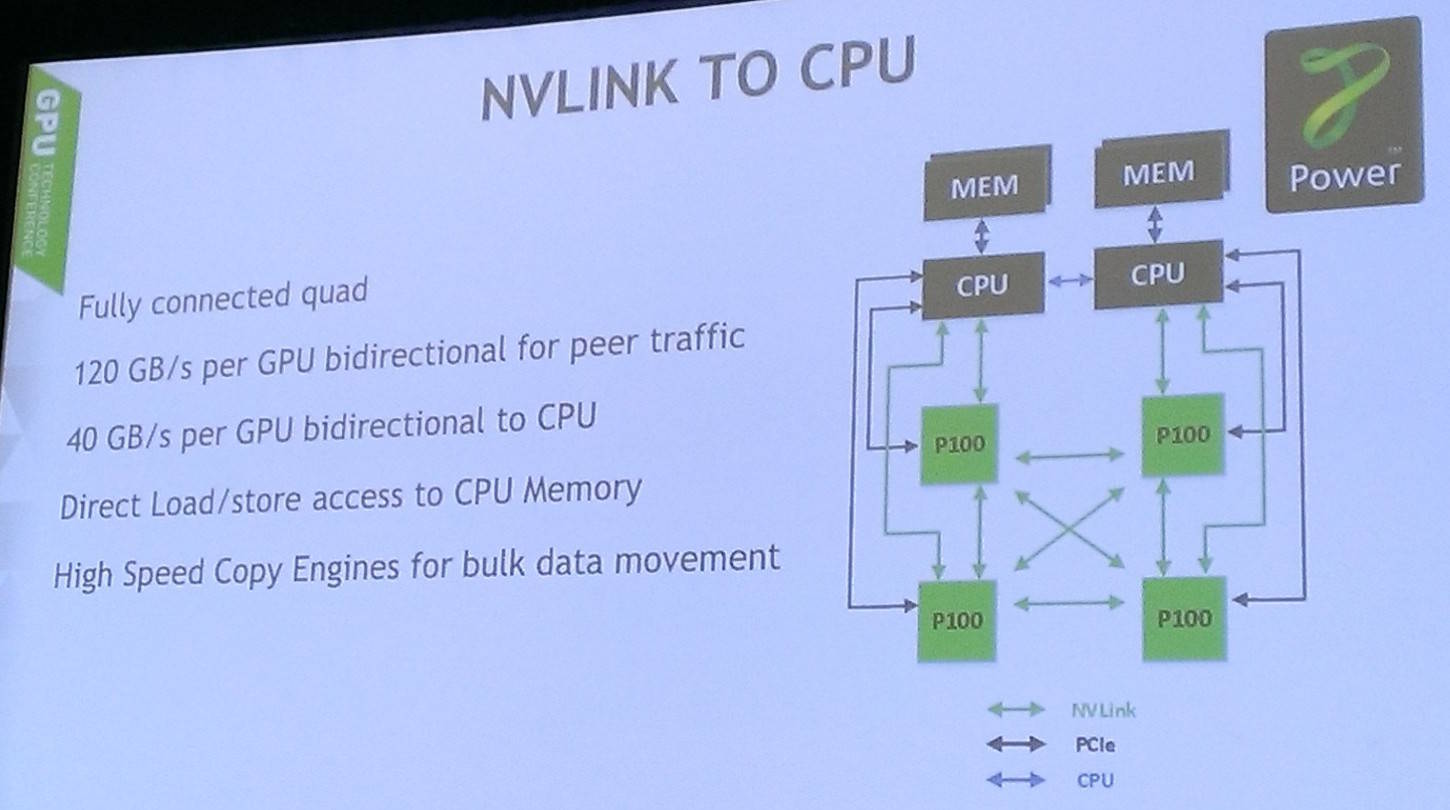
GP100 uses the new NVLink interconnect to hook clusters of GPUs together using 40GB/s links rather than PCIe. This means data can be shifted at high speed between the graphics processors. A cluster of eight P100s (as found in the DGX-1) use NVLink to shuttle data between themselves at a rate that's a little shy of 1TB/s.
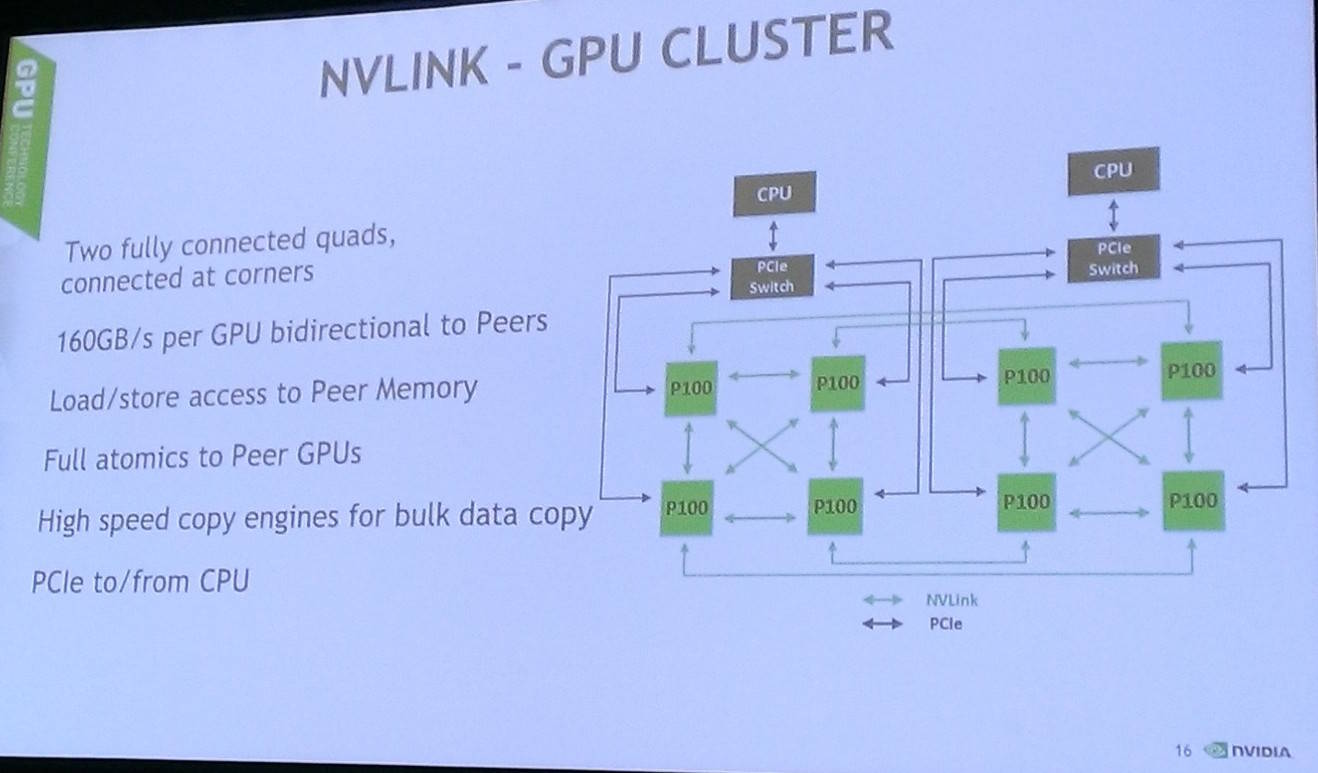
Future compute cores – so far, just IBM's OpenPOWER – can wire themselves direct into NVLink so that there would no need to shunt information over slower buses. The Tesla P100 supports up to four 40GB/s bidirectional links which can be used to read and write to memory. It's just a big performance boost, we're told.
Hate to interject – but...
Software running on the P100 can be preempted on instruction boundaries, rather than at the end of a draw call. This means a thread can immediately give way to a higher priority thread, rather than waiting to the end of a potentially lengthy draw operation. This extra latency – the waiting for a call to end – can really mess up very time-sensitive applications, such as virtual reality headsets. A 5ms delay could lead to a missed Vsync and a visible glitch in the real-time rendering, which drives some people nuts.
By getting down to the instruction level, this latency penalty should evaporate, which is good news for VR gamers. Per-instruction preemption means programmers can also single step through GPU code to iron out bugs.
Thanks for the memories
The P100 uses HBM2 (literally, high-bandwidth memory) that shifts data at 720GB/s with error correction thrown in for free – previous Nvidia chips sacrificed some storage space to implement ECC.

HBM2 is said to offer capacities larger than off-chip DDR5 RAM and use less power, too. Each stack of HBM2 storage can contain up to 8GB. On the P100, the four stacks of HBM2 adds up to 16GB. The whole single package – GPU and memory – measures 55 mm by 55 mm. The die itself has an area of 600mm2.
The GP100 also throws in a new atomic instruction: a double-precision floating-point atomic add for values in global memory.
"Huang said that thousands of engineers have been working on the Pascal GPU architecture," noted Tim Prickett Morgan, coeditor of our sister site The Next Platform. "The effort, which began three years ago when Nvidia went 'all in' on machine learning, has cost the company upwards of $3 billion in investments across those years. This is money that the company wants to get back and then some."
There are more details on the Pascal design over here, by Nvidia boffin Mark Harris. ®
