This article is more than 1 year old
Two storage startups walk into a bar. One gulps investor funds, one sips gently
Which one is right?
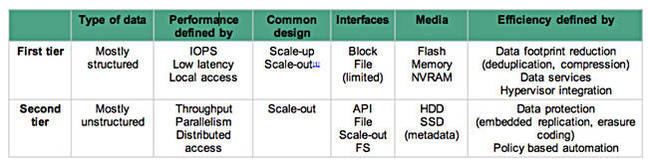
It’s all about secondary storage these days. We are talking about a market that is estimated to grab 80 to 90 per cent of the overall capacity installed and 40/50 per cent of the total storage expenditure in a few years from now. Tellingly, their $/GB is much lower than for primary storage).
Part of this storage will be object/cloud based, to the benefit of a few object storage vendors and CSPs like Scality, Caringo, DDN or AWS and Azure. But a large part of it will be installed on-premises, contributing to build two-tier storage infrastructures which I usually refer to as “flash and trash”. In any case, most of these installations will be based on scale-out architectures.
Secondary means everything. Well, everything apart from data stored in primary storage. In most of the cases also NAS filers (which are critical for the day-to-day business) are now considered secondary storage.
It’s no longer a problem of data protection, which you take for granted on every type of system now, nor of features, which are probably easier to implement and adopt on these systems. It’s becoming more a problem of local Vs. distributed performance.
Local Vs Distributed performance
Over time, demand for local performance, featuring high IOPS and latency sensitive data and workloads running within the data centre, has been joined by distributed performance needs that are associated with high throughput, parallelism and distributed data accessed from anywhere, and on any device. Even though high IOPS demand can also be a characteristic of distributed performance workloads, this is always associated with high latency, due to the nature of design of distributed systems and consistency of network connectivity involved.
Today, only a small percentage of data (between 10 and 20 per cent) needs local performance, all the rest is much more well served by infrastructures capable of distributed performance. The latter is also the kind of data that is seeing the highest growth, and this is why scalability is a key factor.
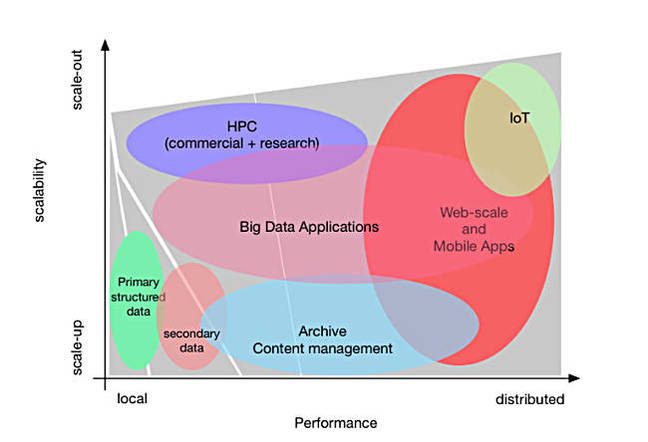
I’ve also mapped performance and scalability to different types of applications.
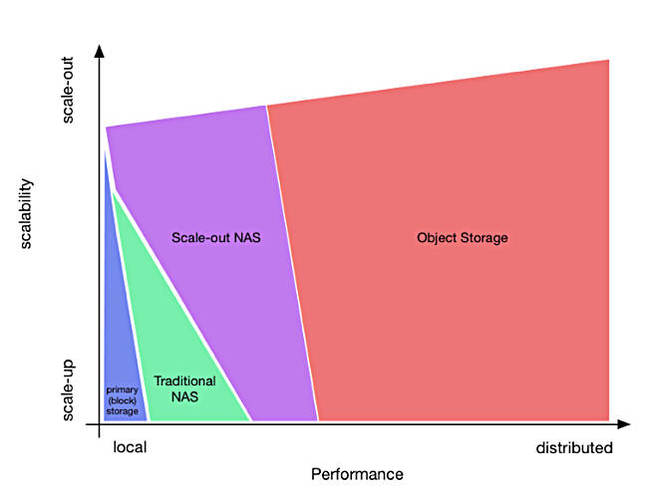
And ...
A tale of two startups
There are two startups in the field I've described that are working on two awesome products that are not in direct competition (well, not today… or, at least, that’s what they say), but have a lot in common and share a similar long term goal. They have chosen two opposite strategies, but I’m sure that there is space for both of them and that they will have a bright future.
I’ve met with both startups several times in the last six to nine months.
As a matter of fact, the founders of the two companies both come from Nutanix, and funnily enough, they left this company more or less at the same time. And, they inherited a lot of basic concepts from Nutanix: scale-out, almost identical hardware appliances and, also, the philosophy seems very similar in many aspects.
The two are very similar in the kind of engineers they have hired, from Google, Facebook and the like. They are building two all-star teams of developers that are implementing awesome features one after the other.
The difference lies in the strategy
Every time I meet with them, I’m impressed about how each has chosen its strategy, and how they have gone in opposite directions.
The first has chosen an all-at-once approach. They’ve raised an incredible amount of money, started with a very large development team and the product is aiming to solve every secondary storage need at once.
For example, version one of the product has an impressive list of features: integrated backup, file services, archiving, cloud integration, big data analytics, and more. Version two was launched a few days ago, improving many aspects of the product.
The only issue I see with this kind of approach is that they have a lot to prove in a short time span.
The second seems more cautious by applying what can be considered a step-by-step strategy. The team is smaller, and the product – even if you can see the overall potential – started from a single aspect of secondary data: data protection and archiving.
It’s one of the most intriguing solutions you can find already out in the field and I really love the simplicity of the GUI, as well as the new concepts it has introduced to manage what is usually considered one of the most painful activities in data storage.
There is some risk here too, though. Competing backup products are hard to eradicate, especially in the large enterprises, and the competition is tough. The risk is that it will take too long to make the product popular enough and then complete the vision.
You couldn’t say the two startups are in direct competition and actually, they aren’t today (expect for the backup part). But the reality is different. I’m not looking at what they are doing today. On the contrary, I’m trying to figure out where they will be tomorrow.
Both of them, thanks to backup and file-based protocols, can ingest any kind of data. The kind of developers they have hired is no secret, and you don’t need to bring in search engine gurus or data scientist to do another backup or a basic storage solution. In fact, if you look at the demos they are already showing, search capabilities are off the chart, and they’ll get even better in the near future.
It’s also interesting to note that they are both actively looking to partner with primary storage.
Today it’s just marketing, but I’m sure they are working on strong integration features. For example, I’m thinking about leveraging the internal backup scheduler to take a snapshot on a primary storage device and then copy the data volume without impacting the primary system. Once the data is ingested you can do whatever you want: search, backup, archive, cloud replication, data copies for test and dev, and any other sort of activity that comes to your mind…
Closing the circle
At this point, I’m sure you already know who I’m talking about: first, Cohesity, and second, Rubrik. I’ve written about them many times and I like them both. Their potential is huge and I have no preference at this point.
I also know they don’t like to be associated with each other or put in the same discussion together, in fact, I’m sure they won’t be retweeting this article as many times as they usually do. But again, it’s fascinating to look at them and compare what they are doing to succeed.
Rubrik and Cohesity both have an amazing technology background, all-star teams, superb products and a similar objective: being that 80 per cent of storage capacity in your data centre. I found only one aspect that is particularly different while looking at them: their overall strategy for achieving that result.
