This article is more than 1 year old
Splice Machine bags $9m to fund RDBMS on Hadoop and Spark
Carry on database splicing
Splice Machine has secured $9m in C-round funding to carry on splicing Hadoop and relational database management system (RDBMS) technologies together. Total funding is now $31m and the extra cash will pay for accelerated product, sales and marketing efforts.
So what is the problem that this start-up is trying to solve? Splice Machine says it has the key to providing a scale-out RDBMS, capable of catering for ever-growing Big Data storage and processing needs.
Traditional relational database needs remain - well - traditional but if you can combine an RDBMS with Hadoop and Spark, increase run-time speed and save cost then you have a winning proposition.
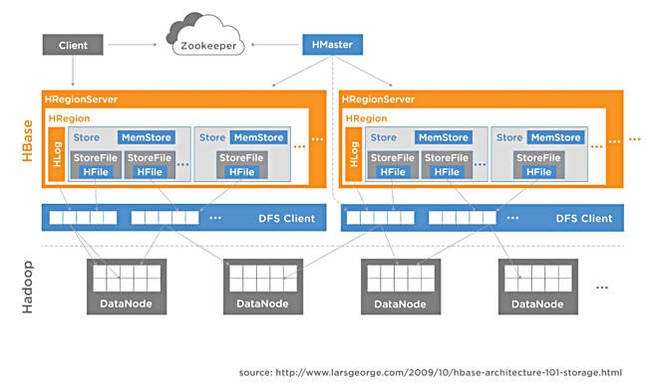
Splice Machine technology diagram
Splice Machine aims to have an RDBMS running on top of Hadoop and Spark and it claims it can “increase performance over traditional RDBMS, such as Oracle and MySQL, by 10-20X, at one-fourth the cost”.
The company recently announced v2.0 of Splice Machine RDBMS, a hybrid in-memory technology that incorporates Hadoop, ANSI SQL, ACID transactions, and the in-memory performance of Apache Spark, the open source clustered engine for large-scale data processing.
Users can run concurrent OLAP (on-line analytics) and OLTP (on-line transaction processing) workloads. ®
