This article is more than 1 year old
Openio's objective is opening up object storage space
Late object comer reckons its tech zings. See for yourself
Openio is an open source object storage startup founded in 2015 by CEO Laurent Denel and six co-founders. The founders had experience with Orange and Atos Wordline and some had built the messaging application for Orange.
It is headquartered in Lille, France, and has an office in San Francisco. The technology development commenced in 2006 and there are 16 people in all. The product is an object storage system for applications that scales from terabytes to exabytes, and is in its v15.12 release.
It has 1PB under management so far, and is being used in email storage, consumer cloud, archiving for speed control cameras, healthcare systems, voice call recordings and similar applications.
The starting idea, we're told (PDF), was "to store huge amounts of relatively small files produced by end-users like emails, eventually using a large storage capacity, but always accessed with the lowest latency," and service level agreements.
In the Openio SDS product there is a single global namespace, and metadata is distributed, avoiding metadata nodes become scalability choke-points. According to the firm's marketing blurb: “The solution had also to be hardware agnostic and support heterogeneous deployments. It had to support multiple hardware vendors and multiple storage technologies, from simple single drive x86 hosts to high-end NAS and SAN arrays that were going to be re-used behind x86 servers.”
The media can be SSDs, disk drives and even tape.
A production system was built in 2008 and the software became open source in 2012. We understand this came about as a request from a major customer.
The metadata system is a distributed directory with a tree-like structure made of two indirection tables. Whether the size of the data store is 1MB, 100TB, 100s of PBs it takes 3 hops to get an object's location, meaning, Openio says, faster reads. A 3-server system is the minimum recommended starting configuration.
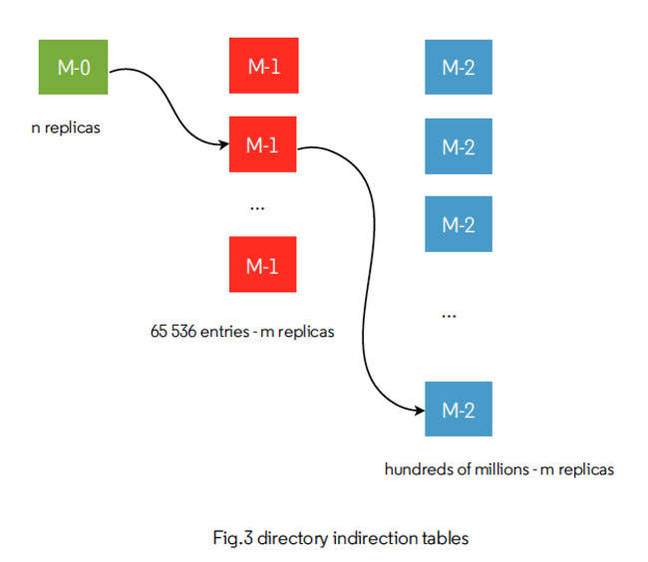
Openio directory scheme
There is a shared nothing architecture and no single point of failure, even at node level, and every service used to serve data is redundant. All metadata and data is duplicated.
As a French company is terminology is distinctive, with its Conscience technology being used to manage its system across heterogeneous hardware, automatically discover it and use it. Whatever hardware can be mounted and mapped by an X86 Linux server running the Openio SDS software can then by auto-discovered by the Openio grid.
The storage load is distributed across hardware nodes according to their performance potential, both hardware attributes, like CPU and RAM, and IO Idle measure. With new hardware, workload is directed to it until it reaches its maximum performance and capacity. Nodes can be added in ones, tens or more at a time. New nodes will have a high workload availability score and, as they become loaded, their availability for work lessens.
Storage policies can push high access data to solid state media for lower latency access, and there can be many different policies, working on object age, hardware categories, number of replicas needed for a data set, erasure coding used or not, encryption, and other categories. WORM is available for compliance needs.

Openio CEO and co-founder Laurent Denel
The erasure coding service (e.g. Cauchy-Reed-Solomon) splits the data into N chunks of data and K chunks of parity, with N and K being configurable.
Data objects are stored in a hierarchy of Namespace, Account, Container and Object, with a flat structure at the container level. Each item knows its parent, with a container knowing its account, a chunk knowing the object of which it is part and the container that object belongs to. This is a reverse directory scheme. If containers are lost they can be reconstructed from the data. A directory can be rebuilt with a crawl of the items present on the storage nodes.
Object integrity checking is done by periodic storage node crawls which also check chunk accessibility and container referencing. REST APIs can be used to trigger these activities. There is a REST API for metadata access. Accessing clients use a layer of gateways that use these APIs. The gateways can use a shared cache mechanism, equivalent to a Name Service Cache Daemon on Linux hosts.
A filesystem tree can be emulated but has no physical reality in the system. An account is equivalent to a tenant, with multi-tenancy supported, and manages one or more containers, which manage collections of objects, applying policies to them for security (replicas), revision levels and so forth.
Objects, which are not stored in containers but pointed to by them, are BLOBs with metadata and ones with the same name represent revision levels. Large objects will be split into smaller sub-objects or chunks, which are immutable and stored as a file in a filesystem with filesystem extended attributes being used for metadata. Multi-chunk objects can be accessed with distributed reads for faster, smoother reads, which is useful for video-streaming. Each object or chunk is stored as a separate file.
Chunks can be compressed. asynchronously, with them being decompressed when read.
Container and objects are stored in a persistent 3-level distributed directory (Meta-0, Meta-1, Meta-2). Caches are used extensively, inside directory gateways for example, and are available on the client side. There is no gateway in native object mode.
The Conscience technology receives metrics from each node that provide a performance quality score that takes account of service policies. These metrics are shared amongst the nodes and Openio claims “each node knows in realtime what are the best nodes with the highest scores to handle a subsequent request.”
Openio provides tools to automate rebalancing of chunks and containers across nodes. Old and new data and old and new containers can be mixed on the same hardware.
The product supports the S3 SPI and OpenStack Swift. Client sdks are available in C, Python and Java plus a command line interface. There is parallel access to the grid of storage nodes via S3, Swift snd HTTP (native API).
The v0.8 release adds:
- The upcoming 3.0 release of Cyrus Imap server can run on top of OpenIO’s object storage and is enabled as a fully scale-out mailbox management system
- A new Go client, a new C client and better OpenStack SWIFT integration
- Vagrant sandboxes have been updated
- A Docker micro cloud image is available on Docker Hub
A newer release has added an NFS connector (not open source), Dovecot and Zimbra support. There is event-based transcoding for video, and an adaptive streaming connector.
Openio says it has lower latency for object access, any size object, as the size of the system (number of objects) increases, having run internal benchmarks.
The roadmap includes adding a cloud storage tier. It’s possible for customers to run the Openio software as an instance in a public cloud.
Its marketing strategy involves appealing to developers with low amounts of storage as well as ISPs with lots of needed capacity. The aim is to get an ecosystem of developers growing with the developers familiar with object storage concepts.
Seed funding came from the Okto group and an A-round is provisionally planned for early 2016. It needs high quality references in order to grow to a substantial size. The main quality of is software is that it is easier to deploy and manage, also with its low-capacity starting point. It is also a pure software solution, the addition of new nodes to the grid is easy and straightforward compared to competitors' systems, and performance is fast – better than competing systems – and consistent.
Our thinking is that Openio has a credible background and the architecture is elegant and credible. However, it is going to have to make way against well-funded and experienced competitors used to playing in the gladiatorial Silicon Valley arena. It's going to have to fight its way forward with aggression and decisiveness to get its technology virtues and advantages given a fair hearing.
Get access to an Openio core system description here(pdf). Find out about installing the software here and the various support services. Standard support is $0.05/GiB actual data/year billed monthly. Premium support is $90,000/year for 600TB to 5PB. ®
