This article is more than 1 year old
Peaxy offers a vision of the future – and it’s a silo-melding data lake
Raking over dead file virtualisation ashes ... could the flames return?
Data management and storing startup Peaxy aims to provide a Big Data analytics tool that locates and gives you access to data where ever it is.
Well, okay, that all seems a bit of a yawn. We’ve all experienced file virtualisation software, that moves files around storage locations leaving stubs behind. Did someone mention Brocade’s StorageX, EMC’s Rainfinity, Acopia/F5, AutoVirt and Cisco’s NeoPath? None of them set the world on fire.
So why should Peaxy, seemingly raking over these cold, dead ashes, set the world ablaze?
There are more files involved of course, data lakes instead of relative puddles. And Peaxy talks Hyperfiler and dataplanes and merging datasets.
It talks workflows and file system semantics so applications can access files even when the files have been moved to the cloud and require cloud API use. Peaxy hides that problem.
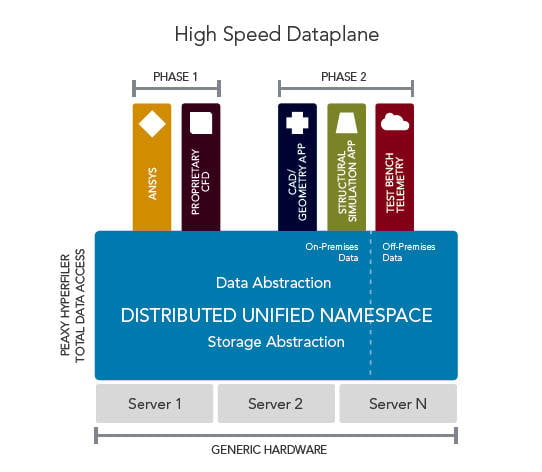
The product is the Hyperfiler and it is a software layer presenting file storage to applications as if there is a single file storage pool. In fact, is a virtual pool composed of both on-premises and cloud storage which exist in a distributed and unified namespace.
Peaxy Hyperfiler diagram
Conceptually, Peaxy has its own (meta) data or namespace store separate from the individual data stores. This is distributed across many servers “making it fully expandable with parallel access to data while eliminating performance bottlenecks – even for small files".
Peaxy says it can scale to exabyte levels with linear performance growth as servers are added. We'll see.
Data and metadata are replicated up to four times, both locally and to remote sites, so that an entire server loss need not be a disaster. Asynchronous replication is included. The architecture is said to be self-healing, using cyclic redundancy checks (CRCs) for both data and metadata.
It says its Hyperfiler “provides a large-scale data infrastructure that consolidates data across types and infrastructures (on and off-premises) into data lakes supported by the unified Peaxy namespace. The namespace spans applications, storage types and uses patented technology to retain file pathnames — even across file migrations and technology refresh cycles — to ensure uninterrupted access to data assets".
The Hyperfiler software “creates a distributed data space that is dynamically expandable [and] serves files, independent of the specific attributes of the underlying hardware, by clustering virtual machines (VMs) or containers to host and manage data".
Peaxy dashboard showing storage classes
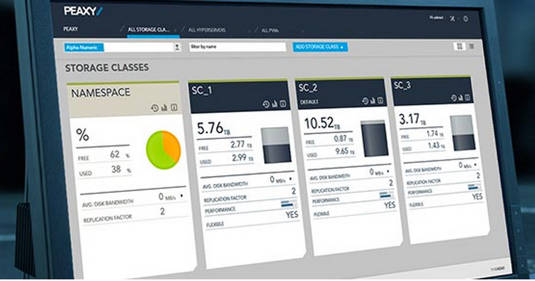
Users can define storage classes (information containers) for data and Peaxy moves data to appropriate storage hardware for its class. The storage classes are set up for different balances of performance, reliability, and cost, with hot data in flash and older and cold data on slower and cheaper media.
It has "automated data migration based on customer-defined policies [which] is performed seamlessly without the need for manual intervention".
We’re told that "data policies define the indexing, security, integrity checks and data set for each container".
Indexing and searching is based on Lucene and Solr, and the Hyperfiler indexes data when it’s modified. Supported file types for indexing include Microsoft Office, HTML, PDF, and AutoCAD DXF and DWG.
Data can be migrated to different storage classes without re-indexing since the Hyperfiler manages both storage class as well as indexing. “The system architecture enables expansion of parsers to support additional file types,” said the company.
Peaxy’s Hyperfiler supports POSIX, Windows CIFS and HDFS. It claims Hyperfiler is a “highly available and well-performing foundation to ingest and store data in Hyperfiler and perform computations on it, with Hadoop or Spark regardless of the application and the access method through which the data was originally written".
