This article is more than 1 year old
Fujitsu sidesteps data scientists with a move toward tuned machine learning
'Why Cheesoid exist?'
Comment Simple questions can be difficult to answer when the predictive analysis needles being looked for are buried in a 50-million-record haystack. However, so-called Tuned Machine Learning techniques can be used to automate data scientists' work, and get answers in a couple of hours that used to take a week or more.
The questions are like these:
- When will users on an e-commerce site give up and not buy anything, and how can the number be reduced?
- When are e-commerce website members likely to cancel their membership?
- What is the response time for an equipment failure, and how can it be lowered?
- When will electricity power demand rise and fall in Tokyo-sized areas so we can generate power that more closely matches actual need?
There are tens of millions of records now available, from sites such as eBay and Amazon, or power generation consumption records, which can be stored in Big Data repositories and analysed to look for the answers to questions like these.
Machine learning is one of many analytical techniques to look into huge masses of data and try to extract meaningful information.
Machine learning difficulties
It looks at building algorithms that learn from a set of data and can then be used to make predictions of what will happen with a fresh set of records in the same data type. Applications have included optical character recognition and spam filtering.
There are many machine learning algorithms, such as supervised ones like Random Forest, Logistic Regression, and Support Vector Machine (SVM), as well as unsupervised ones*.
Fujitsu tells us: “There are numerous methods for machine-learning algorithms, each for a different purpose, and they all differ in their predictive accuracy and run-time. The algorithm that will produce the best accuracy will depend on the data being analysed, and getting the most accurate predictions will also depend on fine-tuning its configuration," and the conditions it uses during its run.
Data scientists use their skill to select a combination of algorithm and configuration to get the most accurate predictive model from the starting data.
The skill levels of individual data scientists vary of course. Where the analysis takes more than 12 hours it’s usually applied to a sub-set of the data and the result is less accurate.
Fujitsu Laboratory researchers in Japan wanted to improve this situation and came up with the idea of using machine learning, so to speak, to improve machine learning.
Improving machine learning
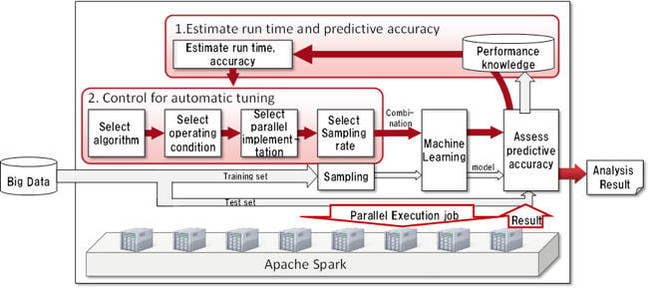
What it does is to run combinations of machine learning and conditions, using Spark, on a subset of data to predict the most accurate machine learning/condition combination to run on the full set of data.
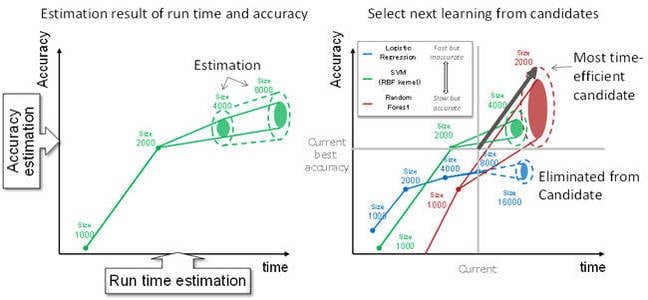
Fujitsu Labs measured the run-time of standard machine learning algorithms on varying sized datasets and attribute numbers. It built a run -time estimation model based on this data saying which algorithm/attribute combos produced the most accurate predictions and can use this to estimate the predictive accuracy of new combinations.
Actual on-the-fly run-time measurements are used to fine tune this model.
Schematic view of the technology
Having got this baseline, and faced with a new data set, Fujitsu says:
This technology selects time-efficient candidates from among all the candidate combinations, and iterates over them efficiently and in parallel.
This technology combines estimates of run-time and predictive accuracy to select candidate combinations of algorithms and configurations that are expected to provide high improvements of predictive accuracy in return for short run-time.
Each selected combination is then run in a distributed manner.
Because this technique automatically focuses on the most effective combinations, it does not depend on the know-how of an analyst.
Control technology to automatically tune machine-learning algorithms
Results
The Fujitsu Labs researchers then ran tests using 8 x 12-core servers and a 50 million record dataset. It claims that “existing techniques would take roughly one week to develop a predictive model with 96 per cent accuracy.“
With its preliminary machine learning algorithm selection run, its “technique reached that level in slightly more than two hours.” Going from one week to two hours is one heck of a speed up.
It’s running field trials now, and it aims to introduce product by the end of its fiscal 2015 year, saying it could “be used to provide services such as predicting electrical-power demand for every household in an area the size of [the] Tokyo metropolitan area." Not a bad result. ®
* There is an excellent Wikipedia article on Random Forest which can be used as a starting point to explore the field of machine learning.
