This article is more than 1 year old
DDN: Quicker storage access passes HPC buck to CPU makers
Bypassing POSIX releases the brake pedal on the server-storage IO equation
Comment At a DDN user group meeting in Frankfurt earlier this year, Alex Bouzari said high-performance computing (HPC) exhibits an enduring tug-of-war between compute and storage.
The co-founder and CEO of DataDirect Networks – which makes fast-access and capacious storage for supercomputing and HPC – speaks from the storage side of the struggle and is repeating a point of view held by many.
Applications running in this HPC world need immense CPU and data storage resources. Typically, sets of processors have parallel access to sets of storage nodes: fast CPUs making best use of slow-spinning disks.
Supercomputers and HPC installations were once compute-bound, with the run-time of apps featuring much more CPU time than IO time.
As supercomputers and HPC server processors became faster, the applications they ran moved into the IO-bound world. The application software spent more time waiting for IO than processing data. However, their users didn't want to wait for storage arrays with serial IO access.
Parallel file systems, like IBM's GPFS and Lustre, provided a popular way of enabling lots more access to storage resources ... and the apps, now getting data faster, reverted to being compute-bound.
But Moore's Law had its way and processors became even more powerful, with multi-threading, multiple cores, and multi-socket servers, shortening the CPU-run time for HPC apps and making them IO-bound once more. Which is where we are today.
Bouzari says the balance can be redressed by inserting a faster-than-disk, drop-in, solid-state tier between the compute servers and the storage nodes, effectively relegating the disk-based nodes to a backing store.
The new tier uses PCIe flash and NVMe drivers. This has similarities to an EMC DSSD (rack-scale flash storage) implementation at a University of Texas supercomputing centre, TACC.
The DDN idea has working set data in its five million IOPS WolfCreek devices, with their IME (Infinite Memory Engine) technology. Bouzari's scheme involves agent software in the servers intercepting POSIX IO requests and sending more optimised IO requests to the IME, with it talking to the backing stores.
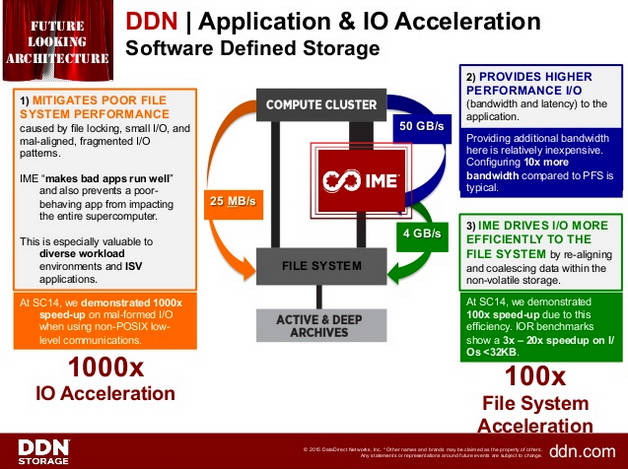
DDN IME application acceleration slide
DDN says the host agent software and IME “mitigates poor file system performance caused by file locking, small IO, and misaligned, fragmented IO patterns”.
POSIX*, the Portable Operating System Interface, is a set of standards to maintain compatibility between operating systems such as Linux, and other Unix variants like OS/X and Solaris. It includes file and directory operations and IO port interface and control.
We can say this is part of a general wave of bringing non-volatile memory closer to compute, using PCIe-based linking and finding ways to shift host operating system IO stacks – based on disk assumptions – out of the way. This is a multi-faceted assault on data-access latency and its effects are going to be profound.
DDN's WolfCreek promises five million IOPS. If we think of this in SPC-1 terms, the highest-performing system today is a Hitachi/HDS VSP G1000 HAF (all-flash) with 2,004,941.89 IOPS. It used 28 K-nodes and 2 management nodes. WolfCreek will be a 4U box.
EMC's NVMe fabric-linked DSSD box is also going to have face-melting performance, according to Chuck Sakac, an EMC president.
Add in the potential from FlashDIMMS and Intel/Micron XPoint memory and we really could be on the cusp of a dramatic change in server-storage IO efficiency. ®
*Check out a POSIX FAQ here.
