This article is more than 1 year old
How to storm the virtual heights of SAN
Size matters
Platoons are easy to manage, nimble and fast-moving, but regiments need a host of logistics operations to bring them to the battle point.
Virtual SANs (Storage Area Networks) comprised of a few nodes are simpler to buy and operate than a full-scale SAN with its network connections, HBAs, thousands of LUNs (logical unit numbers), drives and so forth. Yet virtual SANs with 1,000 nodes or more are heading towards corporate IT as if there was no problem.
Really? How can thousands of servers operate as a single virtual SAN without drowning administrators in complexity?
To answer that question we need to start with a basic appreciation of physical and virtual SANs, then go on to scaling issues.
Physical and virtual
A physical SAN, meaning a traditional block storage array, is accessed over a network link: iSCI/Ethernet, Fibre Channel or Fibre Channel over Ethernet. It is a single box with a controller and disk and/or SSD shelves.
From an accessing host's point of view data is stored in LUNs (groups of blocks viewed as an entity). Applications are provisioned with storage by being assigned a LUN.
The controller operates and manages the array and knows where particular blocks of data are stored so that it can translate LUN/block accesses into disk/track addresses.
Arrays can have dual controllers to protect against controller failure, or multiple controllers to provide more controller processing power. Dual-controller arrays can be clustered, but the basic access principle remains the same: accessing applications see their storage space, a LUN, and the controller translates LUN-based addresses into disk, or SSD, addresses using some kind of look-up table.
A virtual SAN is made up of several server nodes, each with its own directly-accessed storage (DAS). These separate pools of physical server DAS are combined into a single virtual SAN which is seen by accessing applications and their host operating systems exactly as a physical SAN: it has an address and data is stored in blocks inside assigned LUNs.
The obvious difference, however, seems to be that a physical SAN is often a single box, whereas a virtual SAN is made up of several servers and their DAS. But this need not be the case.
A virtual SAN could operate from a single node, albeit with limited capacity. And physical SANS could be multi-node as well, with clusters or multi-controller as with monolithic arrays.
In both cases, unless there is a master controller, each controller needs to know where all the data is stored and the array software/firmware needs to update mapping tables in each controller whenever a write takes place.
It is the same with a multi-node virtual SAN, and there has to be a cluster or network link between the nodes. Don’t make the mistake of thinking a virtual SAN does away with network links and has a necessarily higher metadata maintenance burden than a physical SAN.
Here come the appliances
The first virtual SANs were called virtual storage appliances (VSAs) and came from iSCSI storage suppliers such as LeftHand Networks.
HP bought LeftHand and its SAN/iQ software and used its technology to produce its P4000 StoreVirtual VSA. Other suppliers such as Chelsio, Datacore, Mellanox and NetApp with ONTAP Edge produced their own VSA technology. Hyper-converged startups such as Maxta and Nutanix used VSA technology to construct their block storage resource.
ScaleIO was started up in 2011 by former XtremIO and Topio people, after Topio was bought by NetApp. The founders talked about elastic storage that would be as ubiquitous as RAM and said it would scale to thousands of nodes. EMC bought ScaleIO in June 2013. Two months later EMC subsidiary VMware launched its virtual SAN. In beta test form it had three to eight nodes and used flash as a caching tier above disk storage.
VSAs often run as virtual machines in a VMware environment or under Hyper-V. VMware’s virtual SAN VSA is implemented as an extension to the vSphere core, a VMware kernel module, giving it speed advantages; it is not just another virtual machine.
VMware also abandoned the traditional block storage paradigm and dealt with storage as a virtual machine disk (VMDK) resource holding a virtual machine’s files and using the virtual volume abstraction idea.
In early 2014 VMware launched the virtual SAN product with up to 16 nodes and a petabyte of disk capacity, each node having up to 35 disk drives. The node count is shooting up to 32 with the latest release.
Data accesses
Imagine a traditional physical SAN where an accessing server sends out a read IO request, say, to access blocks A-F on LUN N (or VMDK xx, File yy in the case of virtual SAN).
This is received by the array controller which looks up in its index (metadata) how the LUN and block reference translate to hard disk drives, tracks and blocks. It then fetches the data and pumps it out to the accessing server.
Generally speaking there has been a network hop, an internal table look-up, a data read operation and a further network hop. A write operation is pretty much the same except that the array disk location metadata is constructed during the write process and stored in the array’s metadata store.
With a virtual SAN the process is similar so long as each node has an overall data location table. When data is written to the virtual SAN it ends up on a particular server, or several of them. Every virtual SAN node then has to be told where the data is.
So in both cases, a write is initially complete when it is written to persistent storage (in other words data is safe) but finally complete when all the physical SAN controllers or virtual SAN nodes have their metadata tables updated with the new data’s location. That means every virtual SAN node and every physical SAN controller knows where all the data is and can access it.
A read data request involves sending the request to a SAN controller (physical SAN controller or virtual SAN server node), a table lookup, followed by an access to the desired SAN storage location, probably involving a network hop or hops if the data is striped, fetching the data and shipping it out to the accessing app.
Scaling issues
The more nodes there are in a virtual SAN then the more chunks of data – blocks (or VMDKs) can be stored. Let’s suppose 5 million chunks of data are stored across 10 nodes, 500,000 per node. A new chunk gets written and the writing node sends out metadata updates to the other nine nodes.
Suppose new chunks get written at a rate of 100 per minute per node. Each node sends out 100 updates to the other nine nodes each minute, 1,000 updates in all. Sounds manageable. Just.
Against this background storage has to be provisioned for applications and de-provisioned. RAID groups operate and are managed. Disks fail and data is recovered. Disks are added and data rebalanced across the nodes. Protection policies are applied per application/groups of apps. It is still manageable.
Now scale this up to 1,000 nodes and we have 100,000 updates per minute and equivalent rises in disk failure rates, RAID recoveries, protection policy use and so forth. The inter-node network can get choked. Each node's storage controller functionality becomes a local bottleneck, consuming more and more host CPU resources.
No wonder VMware caps virtual SAN at 32 nodes. But how does ScaleIO manage to operate at all in the 1,000-plus node area without falling over, dizzy at its own complexity?
Massive virtual SANs
What the ScaleIO founders did was to separate ScaleIO storage client (SDC) functions from storage data controller server (SDS) functions and have each node be part of a loosely coupled cluster. The SDCs maintain a “very, very small in-memory hash, being able to maintain mapping of PBs of data with just MBs of RAM”.
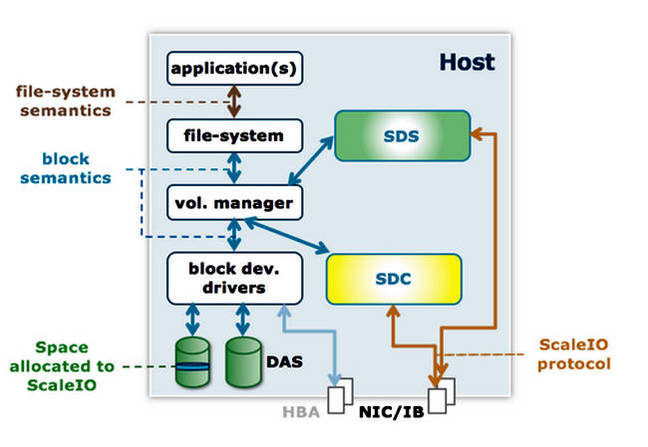
Data and client separation
The SDC (client) is small and has volumes presented to it by the SDS which can use disk and flash for persistent storage and both RAM and flash for caching. SDCs in nodes communicate between each other using fast Ethernet or InfiniBand networks.
A separate ScaleIO cluster management function operates outside the data path. Every SDC knows where all the data is in the cluster, as there is a distributed metadata mapping model.
The inter-node protocol used by SDCs is simpler than iSCSI and uses fewer network resources.
ScaleIO software takes each chunk of data to be written and spreads it across many nodes, mirroring it as well. This makes data rebuilds from disk loss very fast as lots of nodes contribute their own smaller, faster and parallel rebuild efforts to the whole.
ScaleIO supports VMware, Hyper-V and KVM hypervisors. It also supports OpenStack, Red Hat, SLES, CentOS, and (coming soon) Ubuntu LTS releases and CoreOS (docker). Any app needing block storage can use it, including Oracle and other databases.
It has quality of service, partitioning and multi-tenancy functions. EMC information infrastructure president Chad Sakac claims it is faster than Ceph, Nutanix’s NDFS storage and Oracle’s Exadata system, but it is not as closely integrated with VMware as Virtual SAN, although the SDC functionality has moved into the VMware kernel.
Because it is loosely coupled, global data reduction doesn’t work as well as, say, XtremIO, with its tightly coupled design of up to 16 nodes and shared memory model.
ScaleIO is for transaction-type workloads where global data reduction is not necessary, scalability is essential and performance needs to be fast and linear. Sakac says "writes are generally sub-millisecond, and reads about half that".
It takes over, in a way, in VMWare-only environments where Virtual SAN stops. The software can be used to avoid buying high-end disk arrays or hybrid arrays, according to EMC.
It is available as a free download with community support or as a paid-for EMC-supported option. Virtual SAN is available in the traditional VMware way, as a paid-for license.
EMC would have us understand that ScaleIO gives us monster array scale with small array nimbleness. Storage battalions and regiments can move faster and be managed more easily by rapidly adding platoon-level entities.
Sakac's blog features a candid analysis of the pros and cons of the approach, and there is also an ESG Lab validation.
No other supplier has anything quite like ScaleIO, although others may well be evaluating the concept. If they are, no-one is brave enough to talk about it. ®
