This article is more than 1 year old
Tachyon Nexus theorises on ultra fast storage
Not faster-than-light but way quicker than in-memory HDFS
Any in-memory-focussed clustered system has to deal with failure at some point, and learn how to recover from, or tolerate, it.
Replication is a common method but it slows down processing, especially in sequences of jobs in a pipeline. However, upstart Tachyon Nexus thinks it has found a way round that problem, and can go a hundred times faster than in-memory HDFS.
Tachyon Nexus, with $7.5m in A-round funding from Andreessen Horowitz, was set up this year by a bunch of people from UC Berkeley’s AMPLab.
They have been working on an in-memory storage architecture involving server clusters, and the software, called Tachyon, is a two-year old Apache open-source project.
A tachyon is a proposed faster-than-light particle. Such a speed means you would not be able to see it coming, but once it had arrived you would then see it both coming and going.
The founder of Tachyon Nexus is Haoyuan Li, currently studying for a Computer Science doctorate at AMPLab, which is a UC Berkeley facility involved in aspects of getting information from data via Big Data analytics. AMP stands for Algorithms, Machines and People.
Li and four others wrote a paper late last year entitled: “Tachyon: Reliable, Memory Speed Storage for Cluster Computing Frameworks.”
The abstract said:
Tachyon is a distributed file system enabling reliable data sharing at memory speed across cluster computing frameworks. While caching today improves read workloads, writes are either network or disk bound, as replication is used for fault-tolerance.
Tachyon eliminates this bottleneck by pushing lineage, a well-known technique, into the storage layer.
The key challenge in making a long-running lineage-based storage system is timely data recovery in case of failures.
Tachyon addresses this issue by introducing a checkpointing algorithm that guarantees bounded recovery cost and resource allocation strategies for recomputation under commonly used resource schedulers.
Our evaluation shows that Tachyon outperforms in-memory HDFS by 110x for writes. It also improves the end-to-end latency of a realistic workflow by 4x. Tachyon is open source and is deployed at multiple companies.
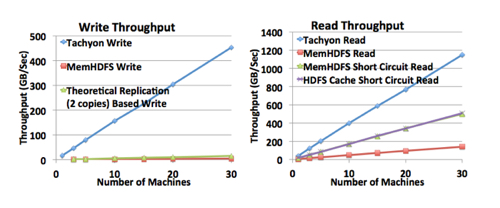
Tachyon performance
Interesting quotes from the paper (pdf) include:-
- [Memory] caching can dramatically improve read performance. Unfortunately, it does not help much with write performance. This is because highly parallel systems need to provide fault-tolerance, and the way they achieve it is by replicating the data written across nodes.
- Tachyon circumvents the throughput limitations of replication by leveraging the concept of lineage where lost output is recovered by re-executing the operations (tasks) that created the output. As a result, lineage provides fault-tolerance without the need for replicating the data.
Read the paper to find out more.
Tachyon software is geared towards servers in clusters having lots of memory and avoiding replication for fault-tolerance. El Reg thinks storage memory using 3D TLC NAND chips might have a role to play here, assuming DRAM stays substantially more expensive than such flash.
The Tachyon open source project has had contributions from 80 sources in more than 30 organisations and is growing fast, but then outperforming in-memory HDFS 100-fold is quite something. ®
