This article is more than 1 year old
IS there anything sexier than hype-converged systems?
First Map Reduce, then Hive/Impala, but what’s next?
Why divergence?
I’m sure you're already aware that there is an interesting trend around Hadoop and Object storage; most of the object storage (and scale-out NAS) vendors are developing HDFS interfaces on top of their platforms while the Hadoop guys are working to use object storage as a sort of extension of HDFS.
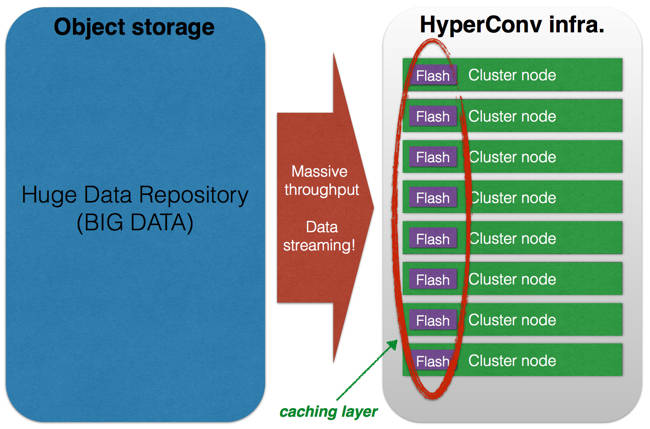
Doing this means that you’ll be able to increase storage independently from other resources. This is a first step but, at the moment, it only solves the capacity problem ... storage must also be fast.
Caching technology helps in this case and a good mix of DRAM and NAND memory on your compute nodes can do the magic. These nodes, because they lack 3.5-inch or 2.5-inch disks, are much smaller so you can build denser clusters.
MCS (Memory Channel Storage) is an example of what I’m talking about. Developed by Diablo Technologies and manufactured by companies such as SanDisk, it’s a flash memory device with the form factor of a standard DDR3 DIMM. This type of device is very sophisticated and brings very low, predictable latency to each single node. Two weeks ago I met Diablo Technologies and it talked about the next step of this technology.
Thanks to their physical position (a DIMM slot), clever engineering and a set of APIs, they’ll be able to “extend” DRAM with NAND (they are only different kinds of memory after all), making it possible to build multi-terabyte-memory nodes. This is mind-blowing tech and its best characteristic is not pure performance but agility.
The next step is micro-convergence (aka “Dockerization”)
One of the best characteristics of hyper-converged infrastructures is their VM-centric view of the world. But here we are talking about an application and a data-centric world; in this case their VM-only idea limits agility and manageability due to all the redundant parts included.
If a big data cluster becomes the centre of many different kinds of workloads, used by various departments of the same organisation, then containers will be the best way to go.
You could instantiate different kinds of jobs (CPU or RAM-bound), manage peaks, multi tenancy, different applications, and so on. It’s just a matter of reconfiguring the cluster for that particular application or specific temporary workload. And thanks to container characteristics it could be done very quickly.
