This article is more than 1 year old
Pivotal ships eponymous Hadoop distro to the masses
An inquisitive HAWQ rides the big data elephant
Pivotal, the spinout from VMware and EMC that's trying to create the application platform of the future, is shipping its first product based on the Hadoop big data muncher.
The new offering is called Pivotal HD, short for Hadoop distribution of course, and the 1.0 release will go after the Hadoop incumbents with add-ons and a relatively low price for support contracts.
Technically speaking, this is not the first time that disk array maker and software player EMC has peddled a Hadoop distribution. In the wake of its acquiring the Greenplum parallel database and related data warehouse appliance business a few years back, EMC hooked up with MapR Technologies to rebrand its own rendition of Hadoop to make its Greenplum HD variant.
But with the Pivotal HD 1.0 distribution, the EMC and VMware spinoff has gone back to the open source Apache Hadoop well and drawn out the 2.0 code as the foundation of its own 1.0 release.
Specifically, Pivotal HD includes the core Hadoop 2.0.2 software, which has the old MapReduce 1.0 algorithm for spewing and chewing data on a cluster of servers as well as the new YARN 2.0 algorithm, all riding atop the Hadoop Distributed File System (HDFS).
The YARN (also known as MapReduce 2.0) layer allows other kinds of algorithms to be loaded onto the Hadoop framework and do different kinds of scatter-gather processing across a cluster.
The Pivotal HD Community Edition, which is freely distributed and has community support, includes the HBase 0.94.2 columnar database, Hive 0.9.1 SQL query engine, Mahout 0.8.0 machine learning layer, and Pig 0.10.0 scripting language all wrapped up. The Flume 1.3.1 log collector and Sqoop 1.4.2 data exchange tool are also in the Pivotal HD Community release.
The Pivotal HD Enterprise Edition adds the Spring Java framework (contributed to Pivotal by VMware) as well as the "Project Serengeti" Hadoop virtualization extensions. The Enterprise Edition also sports a data loader to suck data into HDFS from other sources, and a unified storage service that rides atop HDFS. The Pivotal Command Center is also part of the Enterprise Edition. All of these pieces are developed by Pivotal.
The HAWQ distributed SQL query engine, which has all the smarts of the Greenplum parallel database applied to HDFS so it can speak perfectly fluent SQL, is sold as an add-on for the Enterprise Edition. (El Reg is radically oversimplifying what HAWQ is, we realize.)
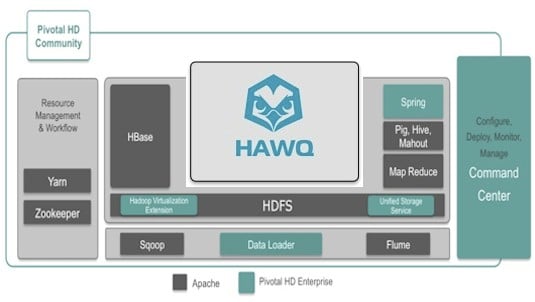
The different editions and add-ons to the Pivotal HD Hadoop stack
HAWQ is a real-time query language and is used instead of Hive, which takes SQL-like queries and turns them into MapReduce batch jobs. HAWQ also competes against the Impala database layer that is in the Cloudera CDH4 distribution and the accelerated HBase functionality that is part of the MapR M7 Edition distribution.
In a blog post announcing the availability of the Pivotal HD 1.0 release, Saravana Krishnamurthy, head of product strategy and vision for the Hadoop stack at Pivotal, explained that there are three packages of Hadoop code being delivered today: the Community and Enterprise editions outlined above as well as something called Pivotal Single Node.
The Community edition is a free download, and you can put it into production and use the community web support on a cluster with up to 50 nodes. (It is not clear if you have to buy a support contract or upgrade to Enterprise edition after this.)
The Enterprise edition has almost all of the goodies, and it has commercial support that costs $1,000 per server node per year. That is undercutting Hortonworks, which is charging $12,000 for support for a ten-node starter cluster, and it is significantly lower than the $4,000 to $5,000 that Cloudera and MapR are charging for their commercial releases, respectively. (Both are a bit vague on pricing, and the feature sets are not perfectly analogous across the releases.) You can also get a perpetual license for Enterprise edition, but Pivotal will not say what it costs.
The HAWQ SQL database query layer for HDFS is priced on a per-node basis just like Pivotal HD Enterprise, but Pivotal is not divulging the price. It is hard to guess what Pivotal thinks it can charge for this function, but with relational databases costing tens of thousands of dollars per core, there is plenty of room to charge many thousands or maybe even tens of thousands of dollars per server node and still make a buck.
If you put a gun to the head of the El Reg systems desk, we would say that if a data warehouse costs $20,000 per terabyte and a raw Hadoop cluster costs $500 per terabyte just using HDFS and HBase, then Pivotal will probably split the difference with HAWQ and try to charge around $10,000 per terabyte.
Working backwards from this, if you have a HP DL380e Gen8 server node with a dozen 3TB drives, that gives you 36TB of data. And at that $10,000 per terabyte price outlined above, that would be $360,000 per node. That may sound crazy until you look at what IBM and Oracle try to charge for the enterprise editions of their relational databases. Still, this sounds far too expensive for a two-socket server.
The point is, what Pivotal is really selling is not so much Hadoop support but the HAWQ database layer, no matter what the price is. And the newbie company is not going to start low and then try to raise the price later.
Rather, Pivotal will try to position HAWQ against relational databases for certain kinds of analytical work and will try to charge as much as the market will bear. And it will probably find that the market will not bear anything like the cost of a relational database cut in half for mainstream customers. HAWQ will have to make it up in volume, just like Linux and MySQL did.
And if Pivotal tries to price HAWQ too high, companies will shift to Project Impala and do it themselves for a lot less (including cutting out Cloudera if it charges too much for commercial support on Impala). Whoever decides to race to the bottom in the SQL-like or SQL query layer for Hadoop is going to set the price. Period.
And no one is in a hurry to start that race just yet – except Hadoop customers. ®
