This article is more than 1 year old
The summer hit you're all waiting for: Windows 9? No. MapR's flashy M7
Amazon cloud boots big-data muncher with PCIe slabs
Customers who want to fire up a Hadoop cluster on the Elastic MapReduce service offered by Amazon Web Services just got another distribution option. Oh yes. It's the MapR Technologies' full-tilt-boogie M7 Edition.
The MapR team is talking up the performance of its variant of the big data muncher Hadoop when using the flash-backed virtual server instances on Amazon's public cloud - and has also put the M7 Edition through the paces on in-house clusters sporting Fusion-io flash cards to show how to speed up Hadoop performance.
Amazon doesn't say how many Hadoop customers it has on its cloud, but a year ago MapR told El Reg that 90 per cent of the Hadoop work running on AWS was pumped through the Elastic MapReduce (EMR) service. Only 10 per cent of customers went out and bought server images and loaded up their own operating system, Java stack, and Hadoop on top of it.
This stands to reason, of course, with the whole point of an infrastructure/platform cloud being to get companies out of the habit of installing and maintaining systems software.
Amazon packaged up its own Hadoop distribution when it launched EMR as a beta in April 2009. The service automates the operation of a Hadoop cluster, scaling up EC2 computer instances and S3 object storage as needed to run Hadoop jobs. MapR was founded about the same time Amazon fired up the EMR service, and it spent two years creating a better file system than the native Hadoop Distributed File System - one that lets applications hook into the MapR file system with either NFS mounting or ODBC connectivity.
MapR's M5 Edition also included distributed JobTracker and NameNode controller nodes, eliminating single points of failure in a Hadoop setup and allowing for the cluster to scale further than kosher Apache Hadoop can, and also had data compression and other features to boost the I/O performance compared to M3. These M3 and M5 editions really didn't come to market until late 2011, and the M7 Edition hit the streets a year later in beta form with special code to speed up the HBase distributed database layer that rides on top of HDFS. The M7 Edition just became generally available in May.
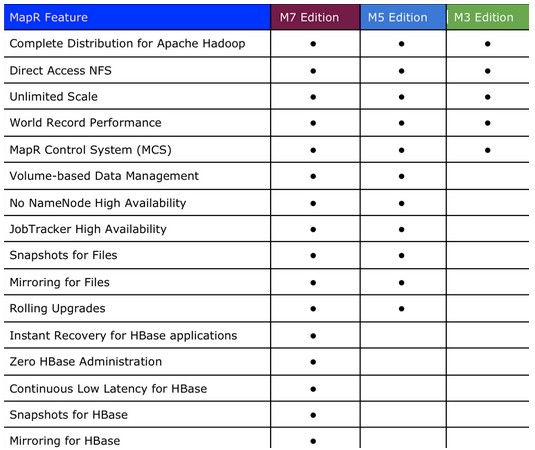
How the three different MapR Hadoop editions stack up
Last summer, the open-source M3 Edition and open-core M5 Edition distributions of Hadoop created by MapR were options in the drop-down menus on the EMR service, including premium pricing that kicks some dough over to MapR. So far, AWS has not added Hadoop distributions from Cloudera, Hortonworks, or IBM. (EMC's Greenplum HD Hadoop distribution was based partly on the MapR code, by the way, so there would be no point in putting that one up there on EMR, but the new Pivotal HD from the EMC spinoff called Pivotal is its own distro and if customers start clamouring for it, Pivotal HD could end up on EMR some day.)
The key thing about the M7 Edition is that it shards raw HDFS data and now HBase database tables that run on top of HDFS natively in the file system, eliminating several layers of Java virtualisation software and at the same time grouping the data sets and database tables together so they can be snapshotted and backed up to mirrors together.
Here's the pricing for the MapR code running inside the EMR service, which does not include the price of the EC2 instances shown or the S3 data storage service, if you don't want to store input and output data in the storage affiliated with the on-demand Hadoop cluster:
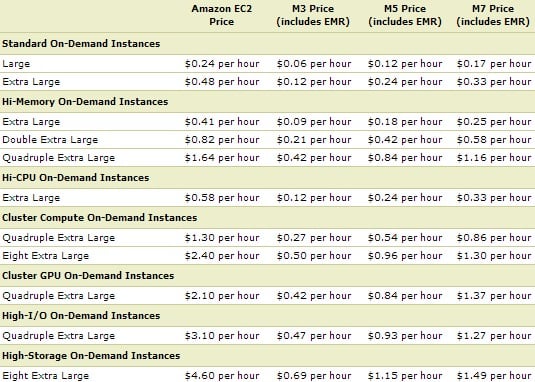
Pricing for EC2 compute instances and the MapR Hadoop inside the EMR service
The M3 Edition has the same price as what Amazon is charging for its own implementation of Apache Hadoop.
The High I/O instances in the table above are backed by solid-state disks, which MapR has taken a shining to as a means of further boosting the performance of HDFS and HBase as well as the overall Hadoop stack.
MapR says an EMR service using the M7 Edition and SATA disk-based High Storage instances can crank through more than 100,000 operations per second per node when running the Yahoo! Cloud Serving Benchmark, which is being put forth as something of a standard for Hadoop performance measurement.
But it is not clear what would happen if EMR customers using M7 switched to the flash-based EC2 instances. It's hard to compare that 100k figure with anything else.
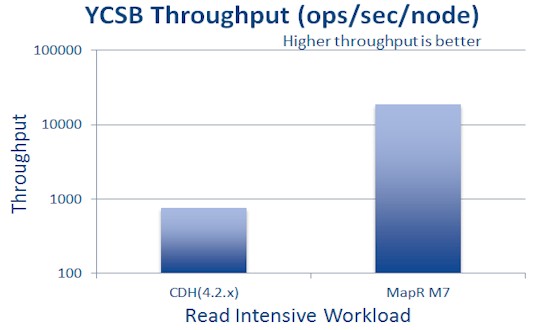
How flashy-backed servers running CDH4 and M7 stack up on a read component of the YCSB test
MapR has, however, benchmarked its clustered servers fitted with Fusion-io flash storage cards to show how the solid-state drives can boost the performance of M7 when running the YCSB test, a data-retrieval rate benchmark. Specifically, MapR put 1.2TB ioDrive 2 cards from Fusion-io into its clusters, and compared the YCSB speed of M7 and the Cloudera CDH4.2 distro on the same server hardware. The nodes were able to process YCSB workloads at anywhere from three to four times faster on M7 than CDH4.2.
(The chart above just shows the comparison on a read-intensive component of the YCSB benchmark.)
If you fire up HBase workloads on the two flash-enhanced Hadoop clusters, then the M7 code can whip through transactions as much as 25 times faster, according to Jack Norris, vice-president of marketing at MapR.
"With other Hadoop distributions, the stack is HBase on a Java instance writing its data to HDFS on another Java instance running atop a Linux operating system writing to disk," Norris explained. "That's a lot of moving parts, and we do not require HBase RegionServers, either, and handle Java garbage collection better, too. This re-architecture in M7 has some performance benefits, as does using flash drives, and as flash proliferates, you will see a greater and greater divergence between MapR and other Hadoop distributions."
Other flash storage has not been tested running the MapR Hadoop distributions yet, but there is no reason to believe they would not goose performance, although perhaps not as far as the Fusion-io cards do.
The important feature of the M7 Edition is that is can create logical volumes in that proprietary file system that is at the heart of MapR's distribution and also has data placement control that can be matched to job placement. You can create a zone with multiple compute nodes equipped with flash inside a Hadoop cluster as a region of fast I/O. You do not have to equip the whole cluster with flash drives or flash cards to see benefits.
It is actually necessary to see how the M3, M5, and M7 Editions all stack up against each other with and without flash storage in the server nodes running the YCSB test to make any kind of intelligent purchasing decision. And moreover, it would be even better to see the price/performance differences with all of the hardware and software costs fully burdened. The limited data that MapR is providing is more than most Hadoop disties have offered, but it is still wildly insufficient to make intelligent choices.
So, in the meantime, do your benchmark tests - perhaps out on the EMR service, with different MapR editions and different kinds of storage and compute on a handful of nodes. And don't forget to share your results with El Reg.
And one more thing: isn't it time that the YCSB test became an actual standard and was implemented by all of the Hadoop distros through an independent third party to substantiate all of the claims made publicly – and the many more no doubt made privately – about the performance of their distros? If Hadoop is all grown up, prove it. ®
