This article is more than 1 year old
Top500: Supercomputing sea change incomplete, unpredictable
A mix of CPU and hybrid systems jockey for HPC hegemony – and lucre
ISC 2013 If you were thinking that coprocessors were going to take over the Top500 supercomputer rankings in one fell swoop, or even three or four, and knock CPU-only systems down to the bottom of the barrel – well, not so fast.
While GPU and x86 coprocessors are certainly the main computation engines on some of the largest systems that made it onto the June 2013 HPC system rankings, it's going to take years before such offload engines are the norm – it takes time to port code and get the big bucks needed to put together hybrid machines. Besides, existing machines have to go through their economic life cycles of five years or so.
But make no mistake about it: the HPC racket is in the midst of a transition that will be as jarring and dramatic as the shift from single processor, symmetric multiprocessing, and constellation systems in the 1980s and early 1990s to Linux-based clusters and other massively parallel systems in the late 1990s and early 2000s.
With coprocessors offering ridiculously better floating point performance per chip plus lower electricity use and cost, the CPU is just not the answer any more except for workloads that really need a fast execution pipeline. In years hence, when memory, fabric interconnect, coprocessors, and likely central processors will all be crunched down to single chip packages, we won't even be talking about coprocessors any more. This will simply be the way computing is done.
But in the meantime, there is lots of drama as chip etchers, system makers, interconnect weavers, and government agencies with pride all joust to see what technologies are going to win.
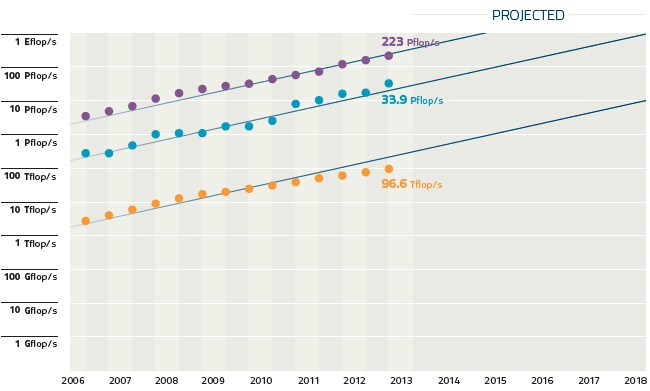
It sure looks like we can get to exaflops, doesn't it?
(The top line shows the aggregate Top500 performance over time, the middle line shows the performance of the fastest system over time, and the bottom line shows the performance of the smalled Top500 system over time)
There are plenty of issues with the Top500 rankings, which are based on the Linpack parallel Fortran benchmark that has been used to rank supers for the past several decades. However, you have to keep score somehow for the technologies in use at the upper echelon of the HPC space – many times, the technologies employed way up there end up on our desktops and in our data centers.
As El Reg previously reported it might, China's Tianhe-2 supercomputer has indeed topped the June Top500 list. This machine has over 16,000 server nodes, using a mix of impending twelve-core "Ivy Bridge-EP" Xeon E5 v2 processors from Intel and custom Xeon Phi x86-based coprocessors, also from Intel.
Tianhe-2 is being paid for by the National University of Defense Technology (NUDT), where it was running during its Linpack tests, but will be moved to the National Supercomputer Center in Guangzhou by the end of the year. Chinese server maker Inspur had a hand in making the system boards and installing testing the system.
The Tianhe-2 uses a proprietary interconnect code-named "Arch" and called TH Express-2 that seems to have some of the attributes of InfiniBand but offers much more bandwidth. The machine aggregates 54.9 petaflops of raw number-crunching power at double precision, and 61.7 per cent of those flops were actually used to generate the 33.86 petaflops rating on the Linpack test that gave the system its number-one ranking.

Artist's rendering of China's shiny new Tianhe-2 super
Unless someone comes up with the big-time budgets for upgrades in the United States, Europe, or Japan, it is likely that Tianhe-2 will retain that rank in the November Top500 list. More importantly, perhaps, the churn throughout the high-end of the list will be minimal.
But watch further down in the list as the rest of the HPC community starts embracing Nvidia Tesla and Intel Xeon Phi coprocessors, or maybe even using APUs that embody a ceepie-geepie on a chip from AMD.
The thing to remember is that we are still in an experimental phase in HPC development – which, in fact, is a perpetual condition to be enjoyed.
The other top systems
The entry of Tianhe-2 at the top has pushed down other systems in the June rankings, of course. The "Titan" XK7 ceepie-geepie at Oak Ridge National Laboratory, which was just formally accepted by the lab last week, is now ranked number two with its 17.59 petaflops of sustained performance on the Linpack test against a peak theoretical performance of 27.11 petaflops. (This story originally said it was not yet accepted at Oak Ridge.)
Titan forges 16-core Opteron 6274 processors with Nvidia's Tesla K20X GPU coprocessors. It has a total of 560,640 cores, with 261,632 coming from the Tesla cards – which do a big chunk of the work – and manages to bring 64.9 per cent of the aggregate performance to bear on Linpack.
It will be interesting to see what Cray can do with its XC30 systems with their much better "Aries" interconnect, when these machines are equipped with the same Xeon E5 v2 processors that Tianhe-2 uses and are outrigged with both Nvidia Tesla K20X or Intel Xeon Phi coprocessors. Cray is working on the upgrades to make this possible, and one of the US government labs will no doubt scrape up the money for a machine, perhaps before the end of this year, perhaps next year.
The XC30 can scale above 100 petaflops right now with "Sandy Bridge-EP" Xeon E5 v1 processors, and it can probably do better with higher energy efficiency (but maybe lower computational efficiency) with an upgrade on the processors and the addition of coprocessors of some kind. The issue is not a technical one, but a budgetary one.
Speaking of computational efficiency, the "Sequoia" BlueGene/Q machine out at Lawrence Livermore National Laboratory has been beefed up to 1.57 million cores using those 16-core Power processors and a funky 3D torus interconnect that IBM cooked up based on work done a ways back at Columbia University.
Sequoia takes a wimpy approach to cores, tuning them for HPC workloads that are embarrassingly parallel, and delivers what is still an impressive 85.3 percent computational efficiency delivering its 17.17 petaflops sustained on Linpack. The Sequoia box consumes 7.89 megawatts, which works out to 2,176.6 megaflops per watt. That was stellar last year, but Titan is catching up with 2,142.8 megaflops per watt. By the way, Tianhe-2 might be the top flopper, but it delivers only 1,901.5 megaflops per watt.
The Chinese system has its own interconnect, its own Kylin Linux variant, and its own OpenMC parallel programming environment that is similar to (but presumably more cross-platform than) Nvidia's CUDA or Open-CL or OpenACC running atop of it.
Give NUDT time and it will tune its software better to its hardware to drive up computational efficiency. Over time, as it shifts to its own Godson MIPS processors and maybe even its own coprocessors, boosting efficiency will no doubt be a goal. There is more headroom there than in process technology – unless you happen to be Intel, which should be at 14 nanometer processes this time next year. (Hard to believe, ain't it?)
IBM could shrink down the BlueGene/Q processor and boost its clock speed, and maybe even goose its interconnect, but thus far, Big Blue has been mum on the subject except for some hints that it may do some kind of asymmetric processing with accelerators distributed throughout the system, not just a ceepie-geepie offload.
The K super installed at the Riken lab in Kobe, Japan has not been upgraded with new processors, even though Fujitsu has put out two generations of peppier chips since K was the top of the Top500 a few lists back. It's not that Fujitsu could not build a machine that might scale up to 50 petaflops or so, but rather it cannot get anyone in the Japanese government to pony up the cash to build another Sparc64-based monster.
K delivers a sustained 10.51 petaflops on Linpack, its computational efficiency is an outrageous 93.2 per cent, and there's some serious engineering in that "Tofu" 6D torus interconnect that Fujitsu created for K. But the system burns 12.66 megawatts, and that works out to a not-so-good 830.2 megaflops per watt. The "Oakleaf-FX" machine that Fujitsu built for the University of Tokyo, which is based on the 16-core Sparc-IXfx processor and the Tofu interconnect, is ranked 26th on the list. It delivers 1.04 petaflops across its 76,800 cores, but delivers only 866.2 megaflops per watt.
It's hard to imagine that a system using the latest Sparc64-X processors surpassing the efficiency of the ceepie-geepies above – or BlueGene/Q for that matter – but it would be nice to see a Sparc64-X machine prove El Reg wrong.
Number five on the Top500 list is the "Mira" BlueGene/Q machine at Argonne National Laboratory, which is essentially a half Sequoia from IBM.
The sixth most powerful machine is the "Stampede" ceepie-phibie built by Dell for the Texas Advanced Computing Center at the University of Texas. This machine is a cluster of PowerEdge C8220 server nodes with Xeon E5 processors that get a whole lot of help with the math homework from an earlier generation of Xeon Phi cards; the nodes are lashed together with a 56Gb/sec InfiniBand network.
Stampede burns 4.51 megawatts and delivers 1,145.9 megaflops per watt not as good as Tianhe-2, obviously, but Stampede is based on older iron.
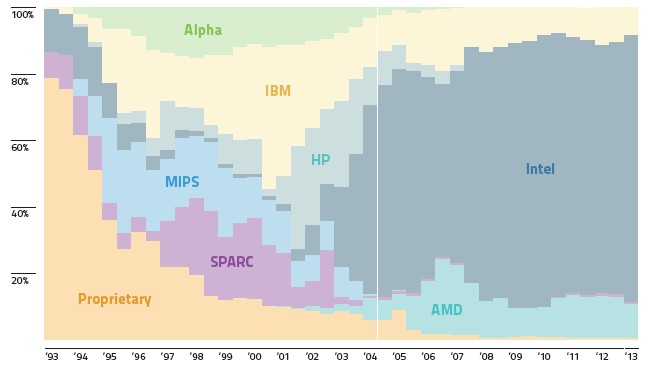
The X86 processor dominates the Top500 super list, and Intel has the lion's share of systems
Another BlueGene/Q machine, called JuQueen, is running at the Forschungzentrum Juelich in Germany. This machine has 462,462 cores and delivers 5.17 petaflops of sustained performance, making it number seven among the Top500 and the most powerful system in Europe.
Number eight, the "Vulcan" BlueGene/Q machine at Lawrence Livermore National Laboratory, has 393,216 cores and delivers 4.29 petaflops of sustained Linpack oomph.
IBM scored number nine with the "SuperMUC" x86-InfiniBand cluster at the Leibniz Rechenzentrum in Germany. This machine, which is based on IBM's iDataPlex dx360 M4 servers – which it does not talk about much after the PureFlex modular systems came out last April – uses eight-core Xeon E5-2680 processors and packs a total of 147,456 cores into the box.
SuperMUC's peak theoretical performance is 3.19 petaflops; just a hair under 2.9 petaflops actually cranks through Linpack, which is a pretty good 91 per cent computational efficiency. But as with other big x86-only machines, SuperMUC is not particularly energy efficient, and you only get 846.3 megaflops per watt out of it.
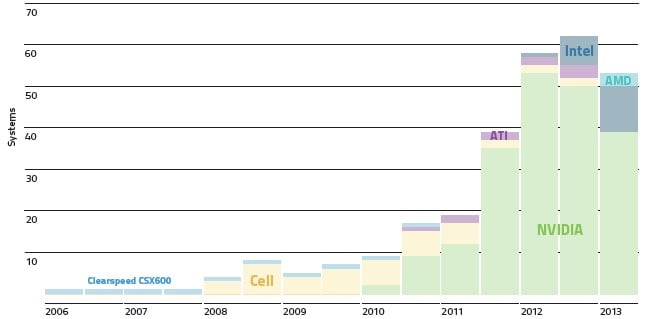
Nvidia supplies most of the accelerators on the Top500 list, but Intel is coming on strong
Rounding out the top ten machines on June's Top500 is the Tianhe-1A machine built by China's NUDT for the National Supercomputing Center in Tianjin that topped the list two and a half years ago using a mix of Intel Xeon X5600 processors and an earlier generation of Nvidia Fermi 2050 GPU coprocessors. This machine is not particularly efficient, with 45.4 per cent of its aggregate 4.7 petaflops going up the chimney on the Linpack test. At 2.57 petaflops, it's no slouch – but it's not particularly energy efficient, yielding a mere 635.1 megaflops per watt.
