This article is more than 1 year old
Cloudera revs up Impala SQL for Hadoop
Big-data elephant to pronk like a gazelle - or roar like a Chevy
Commercial Hadoop distributor Cloudera is first out of the gate with a true SQL layer that sits atop Hadoop.
It lets normal people – if you can call people who've mastered SQL normal – perform ad hoc queries in real time against information crammed into the Hadoop Distributed File System or the HBase database that rides atop it.
Every Hadoop distie dev is working on their own standards-compliant SQL interface for HDFS and HBase, and that's because these are inherently batch-mode systems, like mainframes in the 1960s and 1970s. Hadoop is a perfectly acceptable platform into which you can pull vast sums and run algorithms against to make correlations between different data sets to do fraud detection, risk analysis, web page ad serving, and any other number of jobs.
But if you want to do a quick random query of all or part of a dataset residing out on HDFS or organized in HBase tables, you have to wait.
It took a while for interactive capabilities to be added to mainframes, and it's no surprise that it has taken many years and much complaining to transform the Hadoop stack from batch to interactive mode – but now there are a number of competing methods available.
Cloudera has been working on the Project Impala SQL query engine for HDFS and HBase for years, and formally launched the project at Hadoop World last October when it entered an open beta program in which nearly 50 customers put Impala through some serious paces. Mike Olson, CEO at Cloudera, tells El Reg that there were over 1,000 unique customers who downloaded Impala in the past six months to see how it works, and after all of that testing, Cloudera is ready to sell support services to customers as they put it into production on their big data munchers.
Olson dissed the other methods his rivals have come up to add true SQL functionality to Hadoop.
"Many of the methods we see are rear-guard actions to try to preserve legacy approaches," Olson told us. "This is not really just about putting SQL on Hadoop, but rather making one big-data repository and allowing access to that data in a lot of different ways."
Cloudera went right to the source to get some help to create the Impala real-time SQL engine for HDFS and HBase: Google. Or more precisely, Cloudera hired Marcel Kornacker, one of the architects of the query engine in Google's F1 fault tolerant, distributed relational database that now underpins its AdWords ad serving engine. Impala also borrows heavily from Google's Dremel ad hoc query tool, which has been cloned as the Apache Drill project.
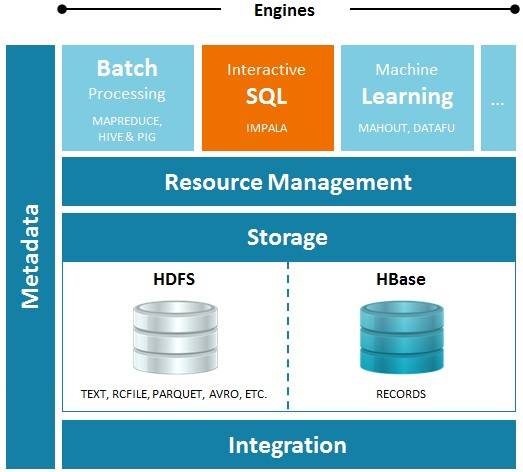
Impala sits between MapReduce and Mahout in the CDH distro
This is the way it works on the modern Internet: Google invents something, publishes a paper, and the Hadoop community clones it. In a way, this is how Google gives back to the open source community, merely by proving to smart people that something can be done so they will imitate it.
Hadoop's MapReduce batch algorithm for chewing on large data sets and its HDFS are riffs on ideas that were part of Google's search engine infrastructure years ago. HBase is a riff on Google's BigTable distributed database overlay for its original Google File System, which has been replaced by a much more elegant solution called Spanner.
In Cloudera's case with Impala, the company not only got the idea for Impala from the F1 and Dremel papers, but hired a Googler to clone many of its core ideas.
The Hadoop stack not only has the HBase distributed tabular data store, but also the Hive query tool, which has an SQL-like query function. But in business, SQL-like don't cut it. What companies – the kind who will pay thousands and thousands of dollars per node for a support contract – want is actual SQL.
In this case, the Impala query engine is compliant with the ANSI-92 SQL standard. What that means is that most tools that use Microsoft's ODBC query tool are compliant with Impala, and marketeers and other line-of-business people who use SQL queries to do their jobs can therefore query data in Hadoop without having to learn to create MapReduce algorithms in Java.
"Large customers running Hadoop today have tens of users who know how to do MapReduce," says Justin Erickson, senior product manager at Cloudera. "But there are a lot more SQL users, on the order of hundreds to thousands, and they want access to the data stored in Hadoop in a way that is familiar to them."
And not surprisingly, as is the case on mainframes even today, there is a mix of batch and interactive workloads running on these behemoths, and this is exactly what Olson expects to see happen eventually on Hadoop systems thanks to tools like Impala.
Based on his inside knowledge of the workloads at Facebook and Google, Olson says that these organizations have already passed the point where the total number of cycles burned on SQL interactive jobs exceeds MapReduce batch jobs. MapReduce will never go to zero, just like batch jobs have not gone away in the data center – you still need to generate and print statements, bills, and other business documents – they are not going away in Hadoop clusters.

Free is below the line, for a fee is above the line
The Impala tool replaces bits of the HBase tabular data store and the Hive query tool without breaking API compatibility but radically speeding up the processing of ad hoc queries and providing ANSI-92 SQL compliance. Hive uses MapReduce, which is why it is so damned slow, but Impala has a new massively parallel distributed database. Customers can use Impala without changing their HDFS or HBase file formats, and because it is open source, you can download it and not pay Cloudera a dime. It will snap right into the Apache Hadoop distribution if you want to roll your own big-data muncher.
While having ad hoc SQL query capability that happens in real time is important, there is more to it than that – this is all about money, as you might expect. "If you are spending tens of thousands of dollars per terabyte in a data warehouse," explains Olson, "you have an imperative to actually throw data away. Impala and Hadoop will let you do it for hundreds of dollars per terabyte, and you never have to throw anything away."
Cloudera is unnecessarily cagey about pricing for its Hadoop tools, but here is how it works. The Cloudera Distribution for Hadoop is open source, and that includes the code for Impala. If you want support and the closed-source Cloudera Manager tool, then you have to pay more. The base Cloudera Manager tool cost $2,600 per server node per year, including 24x7 support, but Cloudera says it is going to split up the functionality for Cloudera Manager into Core (for MapReduce), Real Time Data (for HBase), and Real Time Query (for Impala) data-extraction methods. Cloudera won't say what Core and RTD cost, but RTQ, which manages Impala and provides the support contract, costs $1,500 per node per year – with the obligatory volume discounts, El Reg is sure. ®
