This article is more than 1 year old
Project Savanna tames Hadoop big data muncher with OpenStack control freak
Mirantis, Hortonworks, and Red Hat pull out the whips and peanuts
Batman and Robin. Peanut butter and chocolate. OpenStack and Hadoop. These are things that go together, with the latter pairing being something that commercial OpenStack distie Mirantis, commercial Hadoop distie Hortonworks, and commercial KVM and Linux distie (and soon to be OpenStack commercializer) Red Hat are putting together under a new OpenStack effort dubbed Project Savanna.
The idea of virtualizing Hadoop is not new. Enterprise server virtualization juggernaut VMware has been trying to convince Hadoop shops of the agility and management benefits of putting Hadoop atop its vSphere server virtualization stack for two years now. And the top brass in the OpenStack community are seeing more and more interest in using the cloud control freak (which also can deploy to bare metal) to tame Hadoop.
And hence they came up with a Savanna to package up Hadoop to be controlled by OpenStack as an alternative to VMware's Project Serengeti, which virtualizes the control and compute nodes in a Hadoop cluster. VMware just updated the Serengeti tool a few weeks ago.
There has been much complaining about how difficult it is to set up an OpenStack cloud, and similarly there has been much weeping and gnashing of teeth about how complicated and time consuming it is to set up a Hadoop cluster.
"The infrastructure guy wants to deal with OpenStack and not deal with the complexities of Hadoop," Jim Walker, director of product marketing at Hortonworks tells El Reg. "And the Hadoop guy doesn't want to have to deal with the underlying infrastructure."
Automating the process of installing both OpenStack and Hadoop is the answer, according to the three backers of Project Savanna. The effort was started by Mirantis, which has just made waves for being the OpenStack distie chosen by PayPal for its shiny new private cloud.
Mirantis enlisted the help of Hortonworks for its Hadoop distribution and then Red Hat for its Enterprise Linux and KVM hypervisor. There is some murmuring at the OpenStack Summit that Rackspace Hosting is interested in contributing to Project Savanna as well, but it has not committed to do so as yet formally.
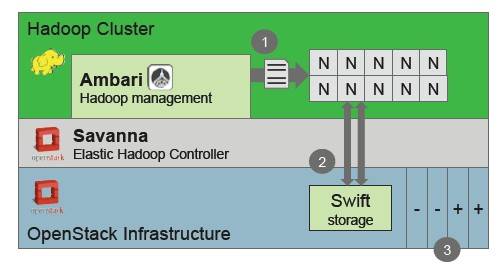
Block diagram of Project Savanna Hadoop-on-OpenStackery
According to Walker, the basic cluster provisioning code donated by Mirantis is done, but the first release of Savanna code, which will include cluster operations, is not expected to be finished until the end of June when the Hadoop Summit is held.
The basic cluster provision for Hadoop clusters uses Ambari to manage templates for Hadoop node images, which include compute/storage nodes as well as NameNode, TaskTracker, and JobTracker nodes, to just name a few. This base Savanna code has REST APIs for cluster start up and operations and is integrated into the Horizon management console for OpenStack.
In phase two of Savanna, OpenStack will be tweaked to allow for the addition and removal of nodes in a manual mode from a Hadoop cluster, and Savanna will be able to configure the Hadoop cluster topology and integrate with the Swift object storage controller bit of OpenStack. This phase also include integration with various third party management and monitoring tools other than Ambari.
In phase three, which is expected to be completed by the end of September (and presumably in conjunction with the future "Havana" release of OpenStack, due in October), the Savanna code will smell a bit more like the Elastic MapReduce (EMR) Hadoop service over at Amazon Web Services.
With EMR, you submit a Hadoop job to the EMR service and it scales up automagically to run the job. With this third phase of Project Savanna, there will be an API in the OpenStack add-on that allows for Map/Reduce jobs to be kicked off without people knowing or caring what the underlying infrastructure looks like. (That is both a good thing and dangerous, like most technology.)
Savanna will also get a user interface for submitting ad-hoc queries to the Hive or Pig add-ons to Hadoop. Over the long haul, the Savanna project will integrate the Hadoop Distributed File System with the Swift controller, allowing for data stored in Swift to be cached in HDFS, and also add the HBase data warehousing layer to HDFS and allow it to be deployed in an automated fashion with OpenStack.
At the moment, Savanna is provisioning elements of the Hadoop stack inside of virtual machines, but another thing that customers may want to do is use OpenStack to deploy Hadoop on bare metal, but still allow OpenStack to play nanny for the Hadoop cluster in terms of provisioning and updating the software.
While hyperscale cloud operators like Google, Facebook, and Yahoo! do not virtualize their Hadoop clusters, Walker says that this makes sense for enterprises because they want to run many different jobs on their Hadoop clusters.
El Reg remains skeptical about this, but it is true that such companies have armies of techies and lots of experience and home-grown tools to provision and manage bare-metal big data munching clusters. Enterprises do not, and they may have to accept the overhead that virtualization imposes on CPU, memory, I/O, and storage so they can.
No one is quite sure what VMware will do with Project Serengeti, and it seems likely that it will be spun into the Pivotal group that EMC and VMware are getting set to launch formally next week after hinting at it since last summer and revealing some details last month.
Hortonworks is supported on both Serengeti and Savanna, and clearly for those shops that prefer the vSphere/vCloud stack, Serengeti will be useful if they want to bring the benefits of virtualization and cloud to their Hadoop clusters.
But, there is a big difference between putting code out on GitHub, as VMware has done with Serengeti, and building a community around an integrated Hadoop/OpenStack setup, which is what the OpenStack community will now do. ®
