This article is more than 1 year old
Intel pits QDR-80 InfiniBand against Mellanox FDR
And hints at integrated networking on future CPUs
As Joe Yaworski, fabric product marketing manager at Intel, put it to El Reg, the next frontier of system innovation will be in fabrics. As we see it, that frontier may also be the front line of the InfiniBand war between Mellanox and Intel – with one upcoming battle being the former's 56Gb/sec interconnects versus Intel's new QDR-80.
Unfortunately, of all the interesting details that you may want to ask Intel about its what it plans to do the networking business, they're not really prepared to provide them. Well, most of them.
But fortunately, Intel does have to keep hinting. It needs to rebuff competition away from other suppliers of networking technology – and that's true both at the high end, where you'll find InfiniBand rival Mellanox, and at the low end, where an army of ARM suppliers are marrying low-powered processors and interconnects to disrupt the hegemony of Xeon servers and top-of-rack switches in the hyperscale data center.
Yaworski hails from the QLogic InfiniBand business that Intel acquired a year ago for $125m. That True Scale networking business, as the brand is now known, includes InfiniBand server host adapters as well as InfiniBand ASICs and whole switches.
But True Scale is only a piece of the networking future at Intel, and the company is looking to do more than supply raw components to switch and server makers.
Intel aims to double the revenue of its Data Center and Connected Systems Group to $20bn by 2016. It took ten years to double it to $10bn, a level the company hit in 2011, and that was done by expanding from server chipsets, processors, and motherboards out to storage components and then networking components.
With ambitions to be the supplier of components for future exascale class machines – capable of supporting maybe 100,000 server nodes with an exaflop of floating point performance and an exabyte of permanent storage of some kind – Intel needed to beef up its networking intellectual property, engineers, and marketeers.
With exascale systems being expensive and requiring tight integration of processing, networking, and memory components to lower power consumption, Intel has no choice but to become an expert in networks. And, as El Reg has contended for a number of years, Chipzilla may also have no choice but to return to the memory business from whence it sprang so many years ago, or else partner so tightly with a company such as Micron Technologies for 3D memory stacking that Micron would effectively become a division of Intel – much like HP and Dell are more or less informal divisions of Microsoft and Intel when it comes to PCs and servers.
To build up its networking portfolio, Intel started out by snapping up Fulcrum Microsystems, a maker of ASICs for Ethernet switches, in July 2011 for an undisclosed sum. (Probably a healthy premium over the $102m in venture capital that Fulcrum had raised, so for fun let's call it $160m.)
Then came the QLogic buy seven months later, followed by the acquisition of Cray's "Aries" butterfly supercomputer interconnect for $140m three months after that in April 2012. Intel already had a respectable business making chips for network interface cards, and if it didn't want to get into the switch racket with gusto, it could have stayed there.
Now Yaworski is being trotted out by Intel to talk about how True Scale 40Gb/sec QDR (Quad Data Rate) InfiniBand products are competing against rival products from Mellanox running at 56Gb/sec FDR (Fourteen Data Rate) speeds based on benchmark tests in some of the big supercomputing labs run by the US Department of Energy.
But Yaworski concedes that the topic of interest is what Intel will do with all of these networking assets – and we will get to that in a moment.
Back when the QLogic deal was done, Yaworski reminded El Reg of something that QLogic has been saying for years: InfiniBand, which was championed first and foremost by IBM and Intel, was not designed to be an interconnect for supercomputer or cloud clusters, but rather as a switched fabric for linking more modest numbers of servers to each other and to their peripherals.
IBM, by the way, uses InfiniBand in this manner today in its Power Systems machines, and has for more than a decade to link server processors directly to remote I/O drawers that house controllers, disk drives, and flash units.
The InfiniBand protocol was largely derived from an I/O paradigm, which made sense when it was designed to replace Ethernet and Fibre Channel. But when InfiniBand first came out in 2000, the mainstream Ethernet switches of the time ran at 10Mb/sec and had port-to-port hop latencies of 150 microseconds; InfiniBand could handle 10Gb/sec of bandwidth and deliver it with a 15 microsecond latency.
And so the message passing interface (MPI) protocol for supercomputer clusters was grafted onto InfiniBand, and a supercomputing niche was born.
QLogic spent years removing the verb architecture of InfiniBand and replacing it with its own "performance scaled messaging" reworking of MPI, which has a more lightweight interface and is very efficient with the kind of small messages that are typical of HPC applications and not typical for I/O workloads.
You have to be careful whenever any vendor whips out benchmark test results, and particularly in a realm where very few organizations have the kind of system scale that DOE supercomputing centers bring to bear. So get out your salt shaker and take a few grains.
Over at Sandia National Laboratory, where the US government is doing simulations to model the degradation of its nuclear weapons stockpile (to better maintain them for readiness) as part of the National Nuclear Security Administration, the boffins have been putting the new Chama system, one chunk of a 6 petaflops super that Appro International (now part of Cray)was commissioned to build back in June 2011. The other two bits of this Tri-Labs Compute Cluster 2 (TLCC2) system, by the way, are going into Lawrence Livermore and Los Alamos National Laboratories, and they are running tests as well.
Appro picked Intel Xeon E5 server nodes for the TLCC2 machine, and QLogic adapters and switches to lash them together. It was probably around here that Intel started to see the networking handwriting on the wall, and started thinking about buying the QLogic InfiniBand biz.
Eventually, Tri-Labs will share a machine with more than 20,000 nodes across the three sites, and this was the biggest deal that Appro ever did – and the wake-up call to Cray to buy Appro and get into the InfiniBand cluster racket proper.
Here's what Sandia found in its benchmark tests on three of its machines, which admittedly are using older Mellanox InfiniBand and Cray "Gemini" 3D torus interconnects compared to QDR InfiniBand links from Intel, and mixing and matching processor types and vintages, too:
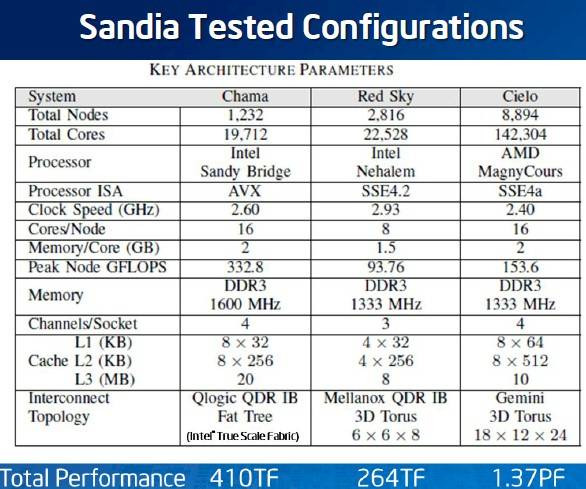
Sandia stacks up its Chama, Red Sky, and Cielo supers
There are many things that make these unfair comparisons, but the biggest one is the AVX floating point instructions in the Chama machine, which are absent from the two others. In fact, there are so many things that are different about these three systems that it would be hard to isolate the impact of choosing one interconnect over another. A proper test would pit identically configured nodes against each other with the different interconnects, but there is not enough time or money in the world to do that at DOE labs. (Hard to believe, but true.)
Here is another set of performance specs that came out of the Tri-Labs Appro machines, this one pitting Opteron nodes using Mellanox InfiniBand against Intel nodes using QLogic InfiniBand. This comparison is somewhat closer – but again, there are such substantial differences between the server nodes (in terms of configurations and count) that it is hard to call this an apples-to-apples comparison. Maybe quince-to-apple, or apple-to-pear would be closer:
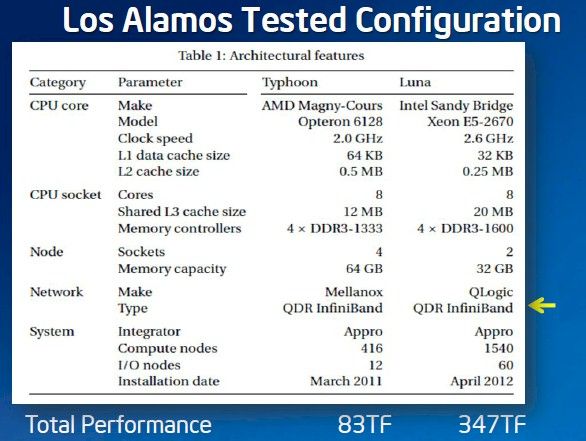
Los Alamos pits the Typhoon Opteron/SwitchX cluster against the Luna Xeon/True Scale cluster
The intent of this chart is simple enough. Both machines are hooked together with QDR InfiniBand, and the Luna machine using Intel processors and QLogic adapters and switches has 4.2 times the performance on a Tri-Labs workload. If you normalize that for the number of cores, the number of nodes, and the clock speed of the cores – that's an aggregate of 26,624GHz for the Typhoon box compared to an aggregate of 64,064GHz for Luna – then you would expected to see somewhere around a factor of 2.4 times higher performance in the Luna machine. Intel contends that its superior implementation of InfiniBand is what makes the difference.
Over at Lawrence Livermore, applications are seeing a 1.8X to 3X performance speedup that can be attributed to a move to Xeon E5 processors, but with the pairing of Xeon E5s with True Scale QDR InfiniBand, workloads are seeing a 4X to 4.7X speedup, says Yaworski, calling it a "better-together story."
El Reg isn't presenting this data to settle any arguments, but it will no doubt start a few – and rightly so. It takes a lot of data to make a case for superior performance of any technology.
