This article is more than 1 year old
Accelerators tag team in Top500 supercomputer CPU smackdown
Titan cuts down Sequoia with Tesla K20X GPUs
Dicing and slicing the Top 500
The top ten machines in the list of 500 systems are always interesting, of course, because they show the level of scalability that the HPC industry has attained and the exotic technologies that are deployed to reach that scalability. But the list as a whole is probably a better indicator of what is going on in the HPC market overall.
In terms of architectures, it has been a very long time since a single processor vector supercomputer ranked on the Top500 list. That ended back in 1996, four years into the establishment of the Top500 rankings by Hans Meuer of the University of Mannheim; Erich Strohmaier and Horst Simon of Lawrence Berkeley National Laboratory; and Jack Dongarra of the University of Tennessee.
Dongarra, along with Jim Bunch, Cleve Moler, and Gilbert Stewart, created the Linpack suite back in the 1970s to measure the performance of machines running vector and matrix calculations. For a long time, Dongarra kept a running tally of machines used on the test that he would put out once a year, with everything from the original PCs all the way up to the hottest SMPs and MPPs stacked up from first to last.
In many ways, this was more useful than the current Top500 list, because it measured machines by type, not by installation, and you could see a wider variety of architectures. That said, the Top500 is a better gauge of what is going on at the high-end of the HPC market in terms of what choices academic, government, and commercial HPC centers are making to run their simulations.
People whinge about Linpack – as some people do about any benchmark test – but the thing to remember is that Linpack is useful more for spotting trends in system design and projecting how they might be more widely adopted in the broader HPC market than it is in making a purchasing decision.
Symmetric multiprocessing (SMP) machines with shared memories had a big chunk of the Top500 back in the early days, and so did massively parallel processing (MPP) architectures that usually lashed together SMPs with proprietary, federated interconnects that have some shared memory characteristics.
Speaking very generally, an MPP has a special network to keep the latency as constant as possible between the nodes, and an interconnect that allows the bandwidth to grow as the number of nodes scales up (ideally, you keep this in proportion). With clusters, the bandwidth is held constant and the latencies get worse as you add nodes, but because it's a hell of a lot cheaper to build a cluster than an MPP system, you're happy to make that tradeoff.
Since the advent of InfiniBand and Gigabit Ethernet, the Linux operating system, and Beowulf clustering back in the late 1990s, clusters have been muscling in and now dominate the Top500 architectures.
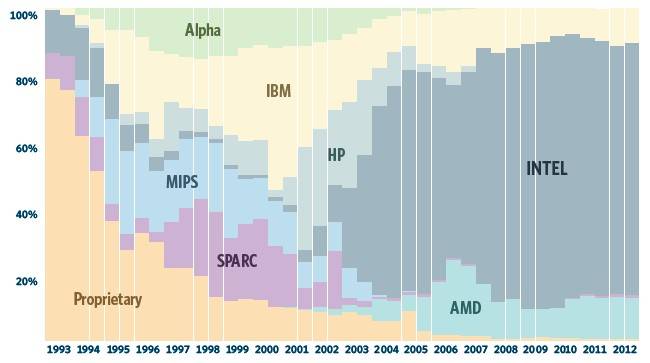
Chips used in Top500 supers over time
Just like clusters dominate the Top500, so do x86 processors. Intel is the main supplier of processors by system count, with 380 machines or 76 per cent of the boxes ranked on the November list. AMD, thanks to Cray's XT5, XE6, and XK7 systems as well as a bunch of clusters, is the processing engine supplier for 60 machines, giving it a 12 per cent share. IBM ranks third with its various Power-based machines, of which there are 53 machines, a 10.3 per cent share.
The use of multicore processors became the norm years ago, and the core count is on the rise. Of the Top500 machines, 435 systems (84.6 per cent) have six or more cores per socket, and 231 systems (46.2 per cent) have eight or more cores per socket. AMD is double-stuffing its Opteron 6200s and now 6300s, driving the per-socket core count to 12 or 16, which is bringing up the class average. IBM is getting set to double-stuff its sockets with the Power7+ processors next year, and we could see some interesting HPC clusters based on these.
The Top500 list has 14.9 million cores across all the machines, for an aggregate of 229.3 peak petaflops, slightly more than twice what was on the list a year ago. Sustained aggregate performance on the Top500 list was 162 petaflops, up by a factor of 2.2X compared to a year ago. The machines are getting more efficient in general, but at a very slow pace. There are far too many machines with heavy x86 processors that use Gigabit Ethernet networks in clusters that have only 40 to 50 per cent computational efficiency.
Of course, processors are no longer the only computing elements out there in HPC Land, with the advent of GPU and now x86 coprocessors onto which CPUs offload the hard math.
Programming these coprocessors is not a simple task, and there are inefficiencies that are tough to overcome. But the growing consensus – excepting the big CPU-based MPP boxes built by IBM and Fujitsu – is that the future of supercomputing is going to be based on some kind of ceepie-geepie.
El Reg is not so sure about that. For instance, imagine a big fat GPU used by gamers with a baby ARM core on it with a distributed switch built in and you can see it doesn't have to be a fat GPU and a fat CPU. You could unify the memory architectures by getting rid of the server node (in this case an x86 server node) entirely.
Similarly, Intel could embed an Atom core with a Cray "Aries" interconnect chip on a Xeon Phi coprocessor and simply do away with the Xeon and an external network. Stack up some 3D memory on top of this and we're at exascale.
Ah, if it were only that easy.
In the meantime, the top supercomputing centers of the world are starting to adopt accelerators in earnest, thanks to the application development path cut by the "Roadrunner" Opteron-Cell hybrid, the world's first petaflopper, and now relatively cheap Tesla and Xeon Phi accelerators from Nvidia and Intel.
On the current Top500 list, there are 62 machines that use coprocessors of one kind or another, up from 58 on the June 2012 list and 39 on the November 2011 list. Of these machines, 50 use Nvidia GPUs to goose performance, three use AMD Radeon GPUs, two use IBM Cell GPU-ish processors, and seven use Xeon Phi coprocessors.
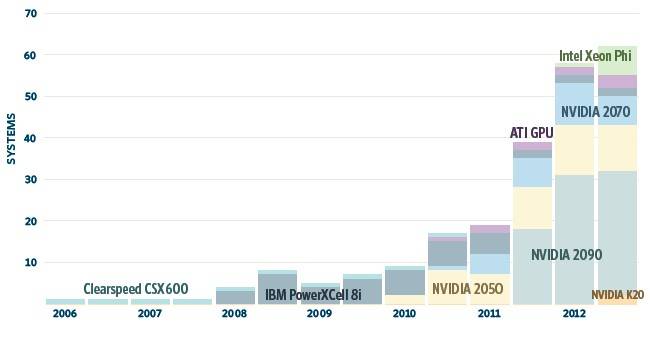
Accelerators are being used to boost the performance of supers
The number of accelerator cores has grown by a factor of 2.2X on the list over the past year while the number of accelerated systems has grown by a factor of 1.6X: on the year-ago list, there were a total of 336,168 accelerator cores across those 39 systems, but now there are 1.19 million accelerator cores across 62 machines. Accelerators are being woven more deeply into systems, even in these early days.
On the networking front, InfiniBand networks have widened the gap in share against Gigabit Ethernet networks as the dominant cluster interconnect. There are 226 machines using InfiniBand at one speed or another, up from 209 machines six months ago; 188 machines are based on Gigabit Ethernet, down from 207 machines on the June Top 500 list.
InfiniBand-based machines have an aggregate of 52.7 petaflops of aggregate peak oomph on the list, compared to 20.3 petaflops for Gigabit Ethernet. By El Reg's count, there are 30 machines on the list that use 10 Gigabit Ethernet links, with an aggregate performance of 4.5 petaflops.
In terms of number-crunching oomph, the 10GE clusters are nearly twice as fat, and it probably will not be long before Gigabit Ethernet is a thing of the past now that 10GE ports are on system motherboards with the Xeon E5 processors from Intel. On average, the InfiniBand machines are nearly three times as fat in terms of sustained Linpack as the Gigabit Ethernet machines, and the ones using the fastest FDR InfiniBand for node-lashing are nearly five times as fat.
Microsoft Azure cluster competes with AWS HPC instances
Aside from accelerators, the other new part of the Top500 list are cloudy clusters set up by Amazon Web Services and now Microsoft Azure to run the Linpack test to show that utility-style HPC is a viable option for customers that do not have the millions to tens of millions to set up and manage their own clusters.
Coming in at number 102 on the November list is a cluster on AWS's EC2 HPC compute cluster variant using 10GE networking that entered the list at number 42 a year ago. This setup, which has not changed in the past year, has 17,024 Xeon E5-2600 cores and a peak theoretical performance of 354.1 teraflops. It delivered 240.1 teraflops running the Linpack test, for a computational efficiency of 67.8 per cent. It is also based on Amazon's own homemade servers.
This time around, after making raw infrastructure available on its Azure cloud, Microsoft has fired up a virtual cluster on its Azure cloud and put Linpack through its paces on it. The Azure configuration is nicknamed "Faenov" in homage to Kyril Faenov, the leader of Microsoft's HPC efforts, who died back in May.
The Faenov virtual cluster on Azure is based on HP's SL230s Gen8 half-width modular servers, which use Intel's Xeon E5-2600 processors. This particular box has 8,064 cores (Xeon E5-2670) running at 2.6GHz, and uses QDR InfiniBand to link the nodes together. That choice of InfiniBand seems to make the difference in terms of computational efficiency, with 90.2 percent of the aggregate oomph of the cluster being brought to bear to deliver a Linpack rating of 151.3 teraflops. That ranks it as the 165th fastest machine in the world.
Do you count this as an HP machine or a Microsoft machine? Good question.

The path to exascale supers looks easier than it is going to be (click to enlarge)
Presuming that the underlying hardware maker gets the credit for the machine, then the Microsoft box is one of the 149 machines with an HP label on them in the November 2012 Top500 list. That gives HP a 29.8 per cent share of systems, compared to IBM's 39 per cent share with 195 systems. HP gained 8 machines and IBM lost 20 machines since June.
IBM kicks it when you look at aggregate performance, however, with a 41 per cent share of the total petaflops, and – thanks to Titan – Cray more than doubled its performance share of the Top 500 list to 17.4 per cent this time around. Cray jumped past HP, which has 11.4 per cent of aggregate petaflops on the list. Fujitsu ranks fourth in terms of aggregate oomph with 8.5 per cent of total petaflops, thanks mostly to the K beast.
Cray just bought Appro last Friday, and those two vendors had 6 and 4.8 per cent share of systems respectively. Silicon Graphics had a 3.8 per cent share of the system count on the November Top500 list, followed by Bull with 3.6 per cent.
If the presidential election last week did not make it abundantly clear that the United States is more like several countries than one, the geo-political statistics from the Top500 list sure do. Being several countries with a federal government, the US dominates the list, with 251 of the 500 systems on the list located within its borders. That is down one machine compared to a year ago.
All in, Europe accounted for 105 systems, also down one, and Asia gained one machine for a total of 123 systems. China is the number two country on the list with 72 machines – but thanks to the K super, Japan bypasses China if you look at aggregate performance.
The United Kingdom has the largest piece of theTop 500 list in Europe, with 24 systems, followed by France with 21 machines and Germany with 20.
To get a machine on the Top500 list this time around, you needed a box with 76.5 teraflops of double-precision floating-point performance on the Linpack test, up from 60.8 teraflops six months ago. To get on the upper fifth of the list and break into the Top 100, you needed a box with 241.3 teraflops, compared to 172.7 teraflops on the June 2012 list. ®
