This article is more than 1 year old
Nvidia puts Tesla K20 GPU coprocessor through its paces
Early results on Hyper-Q, Dynamic Parallelism speedup
Back in May, when Nvidia divulged some of the new features of its top-end GK110 graphics chip, the company said that two new features of the GPU, Hyper-Q and Dynamic Parallelism, would help GPUs run more efficiently and without the CPU butting in all the time. Nvidia is now dribbling out some benchmark test results ahead of the GK110's shipment later this year inside the Tesla K20 GPU coprocessor for servers.
The GK110 GPU chip, sometimes called the Kepler2, is an absolute beast, with over 7.1 billion transistors etched on a die by foundry Taiwan Semiconductor Manufacturing Corp using its much-sought 28 nanometer processes. It sports 15 SMX (streaming multiprocessor extreme) processing units, each with 192 single-precision CUDA cores and 64 double-precision floating point units tacked on to every triplet of CUDA cores. That gives you 960 DP floating point units across a maximum of 2,880 CUDA cores on the GK110 chip.
Nvidia has been vague about absolute performance, but El Reg expects for the GK110 to deliver just under 2 teraflops of raw DP floating point performance at 1GHz clock speeds on the cores and maybe 3.5 teraflops at single precision. That's around three times the oomph – and three times the performance per watt of the thermals are about the same – of the existing Fermi GF110 GPUs used in the Tesla M20 series of GPU coprocessors.
Just having more cores is not going to boost performance. You have to use those cores more efficiently, and that's what the Hyper-Q and Dynamic Parallelism features are all about.
Interestingly, these two features are not available on the GK104 GPU chips, which are used in the Tesla K10 coprocessors that Nvidia is already shipping to customers who need single-precision flops. The Tesla K10 GPU coprocessor puts two GK104 chips on a PCI-Express card and delivers 4.58 teraflops of SP number-crunching in a 225 watt thermal envelope – a staggering 3.5X the performance of the Fermi M2090 coprocessor.
A lot of supercomputer applications run the message passing interface (MPI) protocol to dispatch work on parallel machines, and Hyper-Q allows the GPU to work in a more cooperative fashion with the CPU when handling MPI dispatches. With the Fermi cards, the GPU could only have one MPI task dispatched from the CPU and offloaded to the GPU at a time. This is an obvious bottleneck.
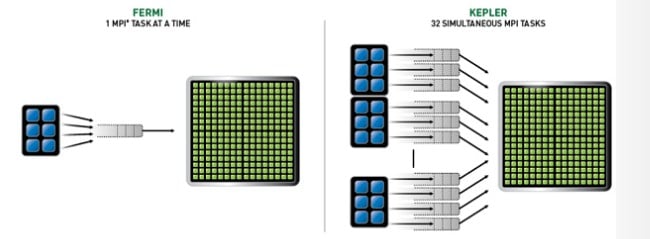
Nvidia's Hyper-Q feature for Kepler GPUs
With Hyper-Q, Nvidia is adding a queue to the GPU itself, and now the processor can dispatch up to 32 different MPI tasks to the GPU at the same time. Not one line of MPI code has to be changed to take advantage of Hyper-Q, it just happens automagically as the CPU is talking to the GPU.
To show how well Hyper-Q works (and that those thousands of CUDA cores won't be sitting around scratching themselves with boredom), Peter Messmer, a senior development engineer at Nvidia, grabbed some molecular simulation code called CP2K, which he said in a blog was "traditionally difficult code for GPUs" and tested how well it ran on a Tesla K20 coprocessor with Hyper-Q turned off and then on.
As Messmer explains, MPI applications "experienced reduced performance gains" when the MPI processes were limited by the CPU to small amounts of work. The CPU got hammered and the GPUs were inactive a lot of the time. And so the GPU speedup in a hybrid system was not what it could be, as you can see in this benchmark test that puts the Tesla K20 coprocessor inside of the future Cray XK7 supercomputer node with a sixteen-core Opteron 6200 processor.
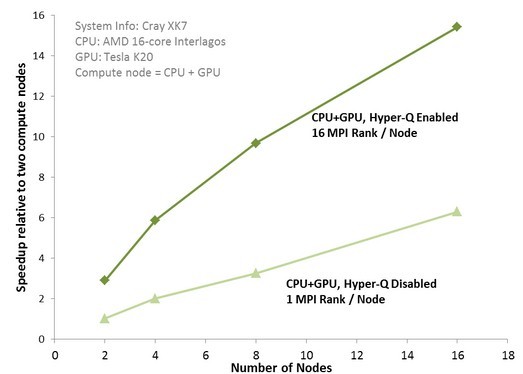
Hyper-Q boosts for nodes running CP2K molecular simulations by 2.5X
With this particular data set, which simulates 864 water molecules, adding node pairs of CPUs and GPUs didn't really boost the performance that much. With sixteen nodes without Hyper-Q enabled, you get twelve times the performance (for some reason, Nvidia has the Y axis as relative speedup compared to two CPU+GPU nodes). But on the same system with sixteen CPU+GPU nodes with Hyper-Q turned on, the performance is 2.5 times as high. Nvidia is not promising that all code will see a similar speedup with Hyper-Q, mind you.
El Reg asked Sumit Gupta, senior director of the Tesla business unit at Nvidia, why the CP2K tests didn't pit the Fermi and Kepler GPUs against each other, and he quipped that Nvidia had to save something for the SC12 supercomputing conference out in Salt Lake City in November.
With Dynamic Parallelism, another feature of the GK110 GPUs, the GPU is given the ability to dispatch work inside the GPU as needed and forced by the calculations that are dispatched to it by the CPU. With the Fermi GPUs, the CPU in the system dispatched work to one or more CUDA cores, and the answer was sent back to the CPU. If further calculations were necessary, the CPU dispatched this data and the algorithms to the GPU, which sent replies back to the CPU, and so on until the calculation finished.
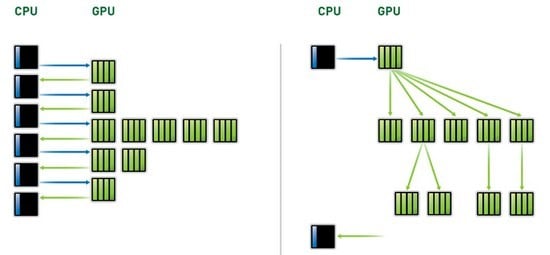
Dynamic Parallelism: schedule your own work, GPU
There can be a lot of back-and-forth with the current Fermi GPUs. Dynamic Parallelism lets the GPU spawn its own work. But more importantly, it also allows for the granularity of the simulations to change dynamically, getting finer-grained where interesting things are going on and doing mostly nothing in the parts of the simulation space where nothing much is going on.
By tuning the granularity of the simulation with the granularity of the data across space and time, you will get better results and do less work (in less time) than you might otherwise with fine-grained simulation in all regions and timeslices.
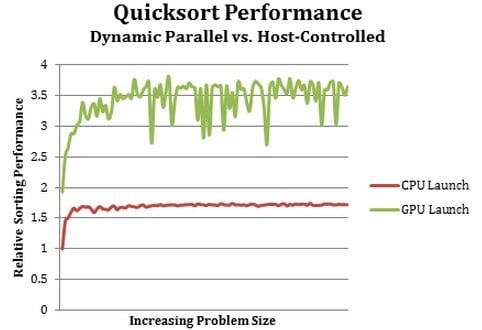
Performance gains from dynamic parallelism for GK110 GPUs
The most important thing about Dynamic Parallelism is that the GPU automatically makes the decision about the coarseness of calculations, reacting to data and launching new threads as needed.
To show off early test results for Dynamic Parallelism, Nvidia did not do a fluid-mechanics simulation or anything neat like that, but rather in another blog post, Nvidia engineer Steven Jones ran a Quicksort benchmark on the K20 GPU coprocessor with the Dynamic Parallelism turned off and then on.
If you've forgotten your CompSci 101, Jones included the Quicksort code he used in the test in the blog post. Interestingly, it takes half as much code to write the Quicksort routine on the GPU with Dynamic Parallelism turned on and used because you don't have to control the bouncing back and forth between CPU and GPU.
As you can see in the chart above, if you do all of the launching for each segment of the data to be sorted from the CPU, which you do with Fermi GPUs, then it takes longer to do the sort. On the K20 GPU, Dynamic Parallelism boosts performance of Quicksort by a factor of two and scales pretty much with the size of the data set. It will be interesting to see how much better that K20 is at doing Quicksort compared to the actual Fermi GPUs, and how other workloads and simulations do with this GPU autonomy.
Gupta tells El Reg that the Tesla K20 coprocessors are on track for initial deliveries in the fourth quarter. ®
