This article is more than 1 year old
Intel hints at weaving network fabric into Xeons, Atoms
Time for controllers and processors to share the bed
IDF 2012 If it wasn't immediately obvious to you, Intel thinks the future of the systems business is weaving interconnection fabrics onto server processors - thus consolidating yet another component of the data center onto the processor and bringing to bear Chipzilla's wafer etching process advantages on that unified chip. And, if Intel plays its cards right, giving it a sustainable advantage to keep arch-nemesis Advanced Micro Devices and up-and-coming rivals in the ARM collective.
"We used to think of a server as a computer, but now the data center has become the computer," Raj Hazra, general manager of technical computing at Intel, told El Reg.
"There is a difference between networks and fabrics, and while there is a place for networks, they lack certain optimizations that fabrics have. Some applications need purpose-built interconnects, and fabrics look at compute and storage nodes as partitioned logical resources rather than as separate units of compute and storage. Problems are becoming superscalar across multiple machines, and that is driving new approaches of adding bandwidth and reducing latencies in that bandwidth. The fabric interconnect has become what was the system bus or processor interface."
The problem, of course, is that many applications are so big that they cannot be solved in a shared memory system that gangs up multiple processors together in an SMP or NUMA cluster. SMP and NUMA systems pretty much run out of gas after 32 sockets, and there is not much more you can do about it beyond cramming more cores into a socket. Shared memory systems make programming easier because coders don't have to deal with parallelism themselves – it is done by the processor, the chipset, and the memory controllers that make a moderately parallel machine look more monolithic.
If you want to scale further than SMP or NUMA, you need something that looks more like a modern supercomputer interconnect and the related programming and scheduling tools that are tuned for it.
Everybody in the server chip racket knows they need some sort of fabric interconnect because it is, in effect, the new chipset for scalable computing. And a fabric is more than just a network, which can allow anything to talk to anything. Fabrics are tuned for specific workloads and are designed to deliver predictable performance without jitter and other side effects.
Feel the width
Fujitsu has the very interesting "Tofu" 6D mesh/torus interconnect in its K supercomputer and its commercial variant, the PrimeHPC FX10 clusters. IBM has created a bunch of interesting ones over the years for its Power Systems. Its latest ones are in the 5D torus in its BlueGene/Q supers and the 1.13TB/sec (that's bytes, not bits) hub-switch interconnect in the Power 775 clusters formerly known as "Blue Waters."
Silicon Graphics and Cray have their own respective NUMALink and XE interconnects. The latest UV2 shared memory supers from SGI use the NUMALink 6, a substantially improved and more compact design than prior NUMAlink interconnect fabrics and notable because they implement shared memory across a maximum of 512 Xeon E5-4600 nodes. Advanced Micro Devices snapped up SeaMicro for $334m in March to get its hands on the "Freedom" 3D mesh/torus interconnect that bears some resemblance to the BlueGene family of interconnects.
At the other end of the spectrum, the ARM server processors just shipping or in development from Calxeda, Applied Micro, and Marvell all have on-chip networking of various kinds. These vendors are actually blazing the trail by adding switches or routers to compute devices.
Intel can't let the ARM collective take the lead here, and it has also made no secret that it wants a big piece of the exascale supercomputing market. It has done a number of key, strategic acquisitions to put a very serious stake in the ground. And as we all know, ideas that start in HPC systems often make their way into commercial systems down the road. In this case, fabric interconnects may end up in regular systems a little sooner than many expect – particularly considering the parallel nature of many database, data warehousing, big data systems, and web caching these days.
This is why Intel bought Ethernet chip specialist Fulcrum Microsystems back in July 2011 for an undisclosed sum (probably well north of $100m based on the VC money Fulcrum blew over the years), and then ate the InfiniBand adapter and switch business from QLogic for $125m in January of this year. (In a way, this was a homecoming for InfiniBand, a standard that Intel helped to create along with IBM and that, like Itanium, was supposed to take over the world. It's tough to beat that x86 instruction set or Ethernet, though.)
The icing on the cake for Intel when it comes to interconnects was the $140m acquisition of the "Gemini" XE6 interconnect and the future "Aries" interconnect, due to be commercialized next year, from Cray. Under that deal, Cray gets to build and sell machines using Gemini and Aries interconnects, but Intel gets the 74 people who know how to make and support them and all the intellectual property behind them. Cray gets three or four years to figure out what it wants to do with itself as Intel basically takes over the core engineering work that Cray did. (Software and services, anybody?)
Both Gemini and Aries are based on a high radix router design, with Gemini being a dumbed down version of Aries that is meant to plug into the HyperTransport links of Opteron processors. Aries will plug into PCI-Express 3.0 ports and therefore not be tied to any specific processor. (Well, we'll see about that, with Intel owning Aries now.) Gemini was designed to scale to 1 million cores in a single system (not with a shared memory architecture, but just as a high-speed cluster), and Aries will no doubt scale further than that and may even have shared memory features for modestly sized clusters with a few thousand cores.
Plugging the pieces together
With its own Ethernet, InfiniBand, and Cray interconnects and lots of people who know about system I/O and server-side networking, Intel has a formidable set of assets from which it can build fabric interconnects and gradually move them onto the Xeon and Atom dies to make very scalable clusters of compact and efficient server nodes. But don't think Intel is going for a one-size-fits-all approach.
"The fabric requirements for each segment of the market are not the same, and their bandwidth and latency needs are not growing at the same rates," said Hazra.
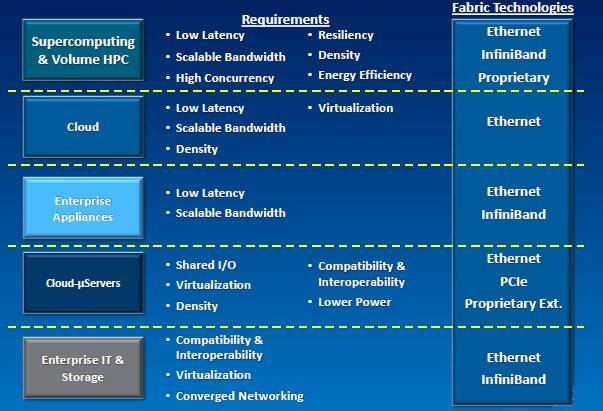
Use cases of fabrics in conjunction with servers
All fabric interconnect makers face the same issues, he said. Customers want scalable link bandwidth and to fully utilize that bandwidth so they don't waste power. (An interconnect chip can burn as much juice as a CPU, after all, and needs to do the same power gating and data perfecting that CPUs and their caches do.) They want low latency and predictable, deterministic latency at the same time. They also want to be able to scale from thousands of nodes to hundreds of thousands of nodes, and they want the ability to carve a cluster into secure tenants with quality-of-service guarantees. But each customer set has slightly different challenges:
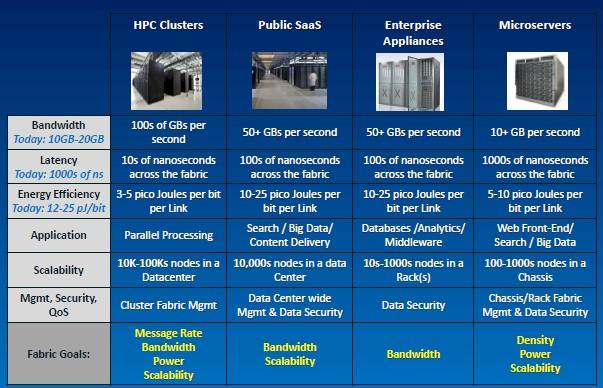
Challenges with modern interconnect fabrics
Intel wants to rule system interconnect fabrics like it does server processors and increasingly does with storage array processing - and it will also have to rule main and flash memories for systems, too, since these will be integral parts of future exascale computing systems and their commercialized offshoots.
The first step was to get the intellectual property and foundation for various fabrics. The next step will be to integrate fabrics onto server processors and coprocessors like the Xeon Phi x86 compute coprocessor that will come to market early next year.
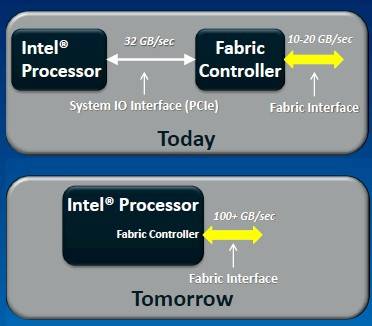
Intel will integrate fabrics onto future processors
Hazra wouldn't give out a lot of details about precisely how Intel will integrate fabrics into chips. But there are clearly three options. Intel can move a fabric controller onto the system motherboard beside the CPU socket, as Cray, SGI, Fujitsu, IBM, and AMD/SeaMicro do with their respective interconnects. It can move the interconnect controller into the processor package but have it be a distinct chip from the processor, as was done with early hybrid CPU-GPU processors for laptops. Or Intel can use the transistor budget and process shrink to put the fabric controller right on the CPU die, much as it has moved on main memory controllers and now PCI-Express 3.0 peripheral controllers with the Xeon E3 and E5 server processors.
"We haven't worked through all the details yet, and we certainly have not announced if fabric integration onto the chip will happen in one step or two steps," Hazra tells El Reg. The packaging and chip processes available in volume at the time that Intel hopes to get fabric integrated with Xeon, Xeon Phi, and server variants of Atom processors will ultimately determine what Intel does. "Be prepared to be surprised," Hazra says with a laugh.
Intel is looking at a number of processor and fabric interconnect combinations, and will not say which of the three interconnects will end up with what processors. And, finally, Hazra hints: "Don’t assume that we will integrate an existing fabric interconnect, such as Ethernet or InfiniBand or Aries. We are innovating with the fabrics, too."
That is a pretty powerful hint, and it brings to mind the switch-hitting SwitchX ASICs that Mellanox Technologies has cooked up, which are at the heart of its own Ethernet and InfiniBand switches and can speak either protocol.
Cray already has a software stack that makes the Gemini interconnect look like Ethernet to a Linux operating system, and Intel could go so far as to create an Aries derivative that could function like an Ethernet, InfiniBand, or Aries controller in a server cluster. Or, if that is too ambitious, Intel could do an Aries integration for high-end supers and a converged Ethernet/InfiniBand controller for more generic servers. Oddly enough, a trimmed down Aries interconnect that spoke Ethernet and could scale to hundreds of thousands of Atom cores is probably what web infrastructure companies might want. And could take on AMD's newly acquired Freedom interconnect.
This is going to get very interesting very fast. Brace yourself. ®
