This article is more than 1 year old
Cloudera herds new bacon-saving Hadoop stack
CDH4 makes elephants chew data quicker
In advance of the Cloud Expo in New York next week, commercial Hadoop distributor Cloudera got the jump on its rivals HortonWorks and MapR Technologies by kicking out a new release of its Cloudera Distribution for Apache Hadoop – CDH for short – and the related Cloudera Manager tool for making the Hadoop elephant, er, stand on a stripy ball..?

Well, you can't make an elephant sit up and bark, now, can you?
The new CHD4 release is based on the open source Apache Hadoop 2.0.0+73 distribution, which was originally mislinked to Hadoop 0.23.1, just to confuse anyone not in the loxodonti. The 2.X code was released as the first alpha version in the Hadoop 2.X series on May 23.
The CDH4 distribution contains 15 separate Hadoop-related programs, as well as a collection of utilities called Hadoop Common. These are packaged up and integrated as a single product, much as Red Hat does with the Linux kernel and some 2,300 different applications that run atop that kernel to create its Enterprise Linux distro.
Hadoop is fairly young yet, and users are driving companies such as Cloudera to quickly adopt the new code coming out of the Apache Project because it addresses real needs right now – much as was the case with Linux 2.2 and Linux 2.4 so many years ago.
The modules include the Hadoop Distributed File System (HDFS), which is the heart of Hadoop and which automatically replicates the unstructured data multiple times across a server cluster and then sets the MapReduce algorithm on it to chew it like cud.

Omer Trajman (left), vice president of technical solutions at Cloudera, tells El Reg that the CDH4 release is unique in that it supports the original MapReduce distributed computing framework (called MR1) as well as the new "Yarn" MapReduce framework (aka MR2) in the same distribution.
The Yarn framework "still has a ways to go in terms of stability," says Trajman, "and if you are running mission-critical Hadoop, you will still run MR1." But the point is to give enterprise shops a chance to play with MR2 and see how it is different.
With MR1, there is a central JobTracker that was responsible for provisioning resources and parceling out data-munching work across the whole cluster. Whenever you have one thing in change of everything, however, you have created a bottleneck.
With the MR2 framework, the Apache Hadoop project has created a global resource manager (RM) that, as the name suggests, manages the resources in the cluster and an application manager (AM) that is, in effect, a JobTracker for every individual application running on the cluster.
Scale further and better
By breaking the JobTracker function apart, a Hadoop cluster – in theory – should be able to scale further and better. You can read the design paper for the MR2 framework here (PDF).
The idea with MR2 is to eventually get Hadoop clusters that can span up to 10,000 nodes and maybe 200,000 cores, and also to have the Application Manager asking permission from the Resource Manager to get resources.
With proper workload management – as every operating system needs – applications have to behave. The initial MR2 release is designed to scale to maybe 6,000 nodes and 100,000 cores. The current MR1 framework tops out at about 4,000 nodes for a variety of different reasons.
The CDH4 stack also includes the Fuse-DFS tool, which lets you mount HDFS as a normal file system on a Linux server. (Fuse is short for Filesystem in Userspace.) The distribution also includes Flume, HBase, Hive, Mahout, Oozie, Pig, Sqoop, Whirr, Zookeeper, and Hue, all of which were contained in the latest CDH3 Update 3 release, and all of which have been updated for the CDH4 release.
Here are the CDH components, what they do, and how they have been updated between CDH3u3 and CDH4:
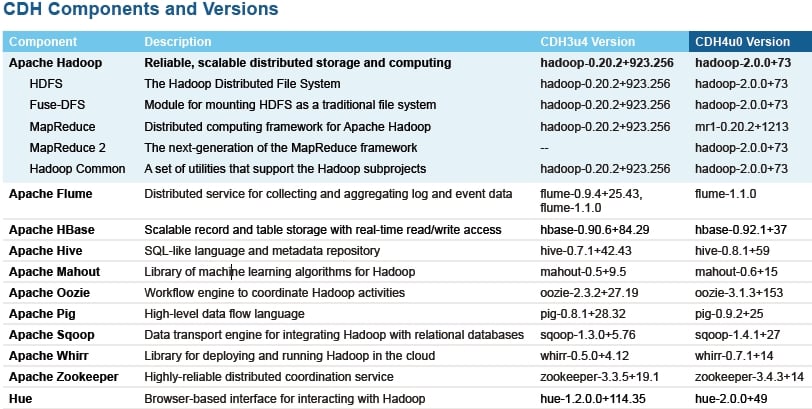
Components of the Cloudera CDH Hadoop distro (click to enlarge)
The big change that gets a lot of attention with Hadoop 2.X (or 0.23.1 if you still call it that) is in the NameNode, which keeps track of where data is replicated around the Hadoop cluster (three copies of each data chunk is the default setting) and tells the JobTracker (or the AM and RM if you are using the new MapReduce 2 framework) where to go to do the munching on the data. If you lose the NameNode, you basically lose the Hadoop Distributed File System, so enterprise shops are understandably jumpy about having this single point of failure.
Until now, says Trajman, companies have coped with this single point of failure as best they can. Facebook has a number of interesting workarounds that it has hacked together, but for most shops, you RAID-protect the disks on the NameNode server, you put in dual power supplies, put in dual network links to the machine, replicate data in the NameNode out to a NAS filer – and pray.
"You could guard against a lot of failures, and these machines are very reliable," says Trajman. The metadata for HDFS was always replicated, but the block reports for HDFS are stored in the NameNode main memory, and if that machine crashes, those block reports are still gone.
Because of the way the NameNode works, you can't just fire up a Linux system clustering package and replicate to a secondary NameNode server. If it were that simple, it would have been done by now. What you can do is set up a standby NameNode and "hot tail" the block reports into the machine's main memory.
The CDH4 release also allows for customers to run CDH3 and CDH4 releases on the same cluster, so companies can stage their upgrades over time without taking the cluster entirely down.
The HBase overlay for HDFS that makes it look and feel a bit like a database, with tables and columns, now has permission controls on both tables and columns in those tables, much as relational databases have had row-level access for years.
HBase is also getting support for coprocessors, which is not a GPU or an FPGA, but rather something analogous to a trigger in a relational database; coprocessors allow HBase to operate on data as it changes in real time and from within the HBase data store instead of having to do a transformation from the outside of HDFS.
The fair scheduler in the MapReduce framework also now has an access control list that makes it easier to create a multi-tenant Hadoop cluster and allow different administrators to submit Hadoop jobs to different pools of nodes in the cluster.
Add up all the tweaks in CDH4, and the HDFS file system runs about twice as fast, HBase can process random reads about twice as fast, Flume can ingest data about three times as fast from outside data sources into HDFS, and MapReduce shuffle operations are about 30 per cent faster. Or so we've been told.
Cloudera Manager 4
In conjunction with the wrapping up of the open source Apache Hadoop and related projects into the CDH4 distribution, Cloudera is also trotting out an update to its homegrown and closed-source control freak for Hadoop, Cloudera Manager 4, the tool that makes NameNode HA easier and also allows for point-and-click management of multi-tenant clusters.
Cloudera Manager 4 includes heat maps to visualize what is going on inside of the cluster in terms of jobs and resources consumed – this is important since a Hadoop cluster is a bit of a black box, doing its own thing once you fire it up – and also includes the federated NameNode management, which allows for multiple clusters to be managed from a single console. These clusters cannot pass data back and forth, they cannot share work, and they still top out at around 4,000 nodes for a single HDFS image.
Cloudera Manager 4 now has a bunch of APIs that are exposed so you can integrate it with third-party management and monitoring tools, LDAP authentication for admins, and can store data for itself in Oracle 10g and 11g and PostgreSQL as well as on MySQL, which was the previous default. Debian and Ubuntu Linuxes are also now supported for the Cloudera Manager console in addition to Red Hat Enterprise Linux.
CDH4 can run on Red Hat Enterprise Linux 5.7 and 6.2, CentOS 5.7 and 6.2, Oracle Linux 5.6, SUSE Linux Enterprise Server 11 SP1 or SP2, Debian 6.0.3, and Ubuntu 10.04 or 12.04. You can also deploy it on the cloudy infrastructure from Amazon, Rackspace Hosting, and SoftLayer. If you're going to use Cloudera Manager, then you need the version 4 to manage CDH4, but you can use either version 3.7 or 4 to manage CDH3u3 if you still have that in your shop.
Cloudera Enterprise 4 is what you call CDH4 plus Cloudera Manager 4 bundled with production-grade tech support, and it costs $4,000 per node per year. If you are a cheapskate – or just getting started and not ready to spend your company's money – you can grab the CDH4 code and a freebie edition of Cloudera Manager that scales up to 50 nodes and provides basic Hadoop cluster management. ®
