This article is more than 1 year old
Nvidia's Kepler pushes parallelism up to eleven
Hyper-Q and Dynamic Parallelism make GPUs sweat
GTC 2012 When Nvidia did a preview of its next-generation "Kepler" GPU chips back in March, the company's top brass said that they were saving some of the goodies in the Kepler design for the big event at Nvidia's GPU Technical Conference in San Jose, which runs this week. And true to its word, the Kepler GPUs do have some goodies that will make them considerably more useful for graphics and HPC compute workloads.
The two big innovations baked into the Kepler GPU are called Hyper-Q and Dynamic Parallelism, and they are integral to the company's plans for the Kepler GPUs to have somewhere between three and four times the performance per watt compared to the prior generation of Fermi GPUs.

Die shot of the Nvidia "Kepler1"
GK104 GPU (click to enlarge)
The first architectural change that Nvidia made is a tradeoff between clock speed and core counts that all CPU and GPU makers are wrestling with every day. Power consumption rises with the clock speed, so reducing the frequency can have a dramatic impact on overall power consumption on a component.
And so concurrently with the shrink from the 40 nanometer processes used with the Fermi GPUs to the 28 nanometer processes used to etch the Keplers, Nvidia is cranking up the core counts and slowing down the clock speeds, increasing the parallelism and the overall performance of GPU while significantly lowering its power draw and heat dissipation.
There are two different Kepler GPUs in development. The Kepler1 chip, also known as GK104, is aimed at graphics cards and Tesla GPU coprocessors, where single-precision floating point math is what matters most.
Until now, Nvidia has not said much about the Kepler2 GPUs – also known as GK110 internally – except that they will be tuned for double-precision floating point math and will support more GDDR5 memory, will have ECC scrubbing on that memory, will have different packaging aimed at servers, and will cost more money than Tesla cards based on the Kepler1 units. A little more info on the Kepler2 GPUs was divulged today at the GTC 2012 event, thankfully.

Nvidia's SMX architecture for the Kepler GPU
The Fermi GPU had 512 cores, and grouped 32 cores into something called a streaming multiprocessor, or SM. The SM had 64KB of L1 cache and a 768KB L2 cache shared across the multiple SMs. The Fermis were the first GPUs that Nvidia added cache memory to, making the SMs look a lot more like standard CPUs in terms of their memory hierarchy. A Fermi GPU had 16 of these SMs and either 3GB or 6GB of GDDR5 memory that they all shared.
The initial Fermis only shipped with 448 cores activated in the top-end models, but as yields improved at Taiwan Semiconductor Manufacturing Corp on its 40 nanometer process, Nvidia was able to ship chips with all 512 cores running.
The Fermis burned between 225 watts and 250 watts in a discrete graphics card and Tesla coprocessor cards; they originally ran at 1.15GHz with the 448 core version and were boosted to 1.3GHz with the 512 core variant. The 512 core Fermi GPU could do 665 gigaflops of double-precision floating point math and 1.33 teraflops at single precision.
With the Keplers, Nvidia is moving on to what it calls an SMX, or streaming multiprocessor extreme, architecture. With the Kepler1 chips, Nvidia is putting 192 cores into a streaming multiprocessor group with slightly modified CUDA cores. Eight of these SMX units are on a single GPU chip for a total of 1,536 cores.
The cores have a base speed of 1006MHz with a turbo boost speed of 1058MHz (no, that is not much of a boost), and even given the fact that the GPU has three times as many cores, dropping the clock speed by a third means it only burns 195 watts. It therefore offers much better performance per watt - about three times, according to Sumit Gupta, senior product manager of the Tesla line at Nvidia, who spoke to El Reg ahead of the GPU Technical Conference.
The Kepler GPUs are not just about shrinking the cores and adding more of them running at a lower speed to a GPU to boost performance. That would probably not be enough to take on the exascale computing tasks that Nvidia is wrestling with as it positions its Tesla GPU coprocessors as the preferred compute engines for future supercomputers, even if this would probably be good enough to make graphics chips that could compete against whatever Advanced Micro Devices could come up with.
One new technology that is going to make the Keplers much better than the Fermis is called Hyper-Q, and as the name suggests, it creates a queue for message passing interface (MPI) tasks running on parallel and hybrid CPU-GPU clusters so multiple MPI tasks can be dispatched from the CPU to the GPU in parallel.
This is so obvious in hindsight that you might have already been thinking that this has already happened, but Gupta says that the Fermi GPUs could only handle one MPI task at a time.
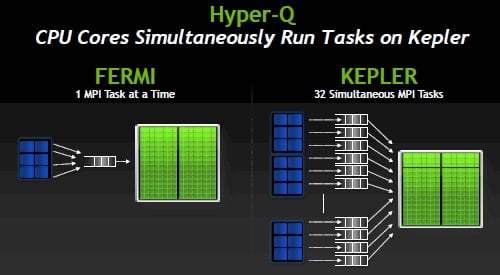
Nvidia's Hyper-Q feature for Kepler GPUs
The Kepler GPUs, by contrast, can have up to 32 distinct MPI tasks beamed to them from the CPU and dispatch them to different segments of the GPU to have them run on isolated chunks of the cores.
It is not clear what the granularity is on the Hyper-Q function, but it is probably no coincidence that there are eight SMX units with 192 cores, and it would not be surprising that Nvidia is allowing for 48 cores to run 32 different tasks at once, effectively partitioning an SMX into four units. Those 48 cores are 50 per cent larger than an SM block on a Fermi GPU, which had 32 cores that ran about 35 per cent faster. So the net performance on this SMX sub-block and the SM block would be more or less the same.
