This article is more than 1 year old
IBM's DB2 database update does time travel, gets graphic
'Continuous data ingest' gorges on bits, compression crunches 'em
With the launch of DB2 10.1, Big Blue is adding a slew of new features that make DB2 more useful for modern, big-data workloads.
Depending on how you want to count it, IBM is either the world's number-two or number-three seller of database management systems, and it has a lot of secondary systems and services business that are driven off its DB2 databases.
Notice that we said DB2 databases. IBM has three different DB2s, not just one. There's DB2 for the mainframe, DB2 for its midrange IBM i (formerly OS/400) platform, and DB2 for Linux, Unix, and Windows platforms.
It is the latter one, known sometimes as DB2 LUW, that was revved up to the 10.1 release level on Tuesday. Concurrent with the database upgrade, IBM is also upgrading its InfoSphere Warehouse – a superset of DB2 designed for data warehousing and OLAP serving – to the 10.1 level.
At a very high level, explains Bernie Spang, director of product strategy for database software and systems at IBM, the DB2 10.1 release is focused on two things: the challenge of coping with big data, and automating more of "the drudgery of the mechanics of the data layer" in applications.
The update to DB2 and InfoSphere Warehouse, which both ship on April 30, is the culmination of four years of development by hundreds of engineers working around the globe from IBM's software labs. The new database also has several performance enhancements, a new data-compression method, and increased compatibility with Oracle databases to help encourage Oracle shops to make the jump.
On the big-data front, IBM has juiced the connector that links DB2 to Hadoop MapReduce clusters running the Hadoop Distributed File System (HDFS). Spang says that the prior Hadoop connector was "rudimentary", and so coders went back to the drawing board and created a much better one that allows for data warehouses to more easily suck in data from and spit out data to Hadoop clusters, with less work on the part of database admins.
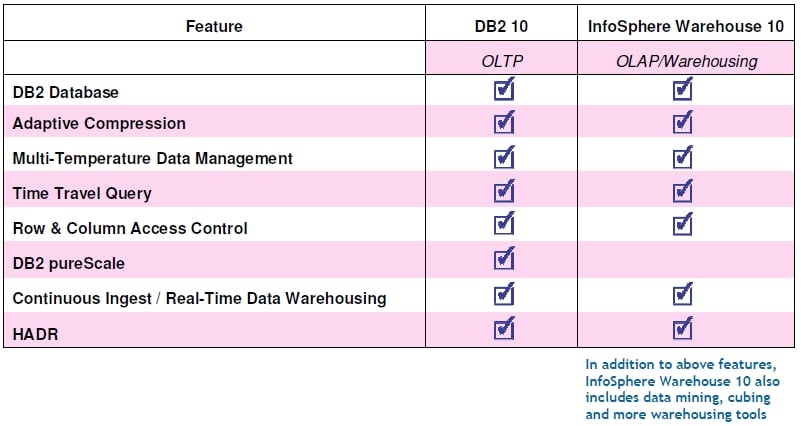
IBM's DB2 10 versus InfoSphere Warehouse 10 (click to enlarge)
The new DB2 also supports the storing of graph triples, which are used to do relationship analytics, or what is sometimes called graph analytics.
Rather than looking through a mountain of data for specific subsets of information, as you do in a relational database or a Hadoop cluster, graph analytics walks you through all of the possible combinations of data to see how they are connected. The links between the data are what is important, and these are usually shown graphically using wire diagrams or other methods – hence the name graph analysis.
Graph data is stored in a special format called Resource Definition Framework (RDF), and you query a data store with this data using a query language called SPARQL.
The Apache Jena project is a Java framework for building semantic web applications based on graph data, and Apache Fuseki is the SPARQL server that processes the SPARQL queries and spits out the relationships so they can be visualized in some fashion. (Cray's new Urika system, announced in March, runs this Apache graph analysis stack on top of a massively multithreaded server.)
Just like they imported objects and XML into the DB2 database so they could be indexed and processed natively, IBM is now bringing in the RDF format so that graph triples can be stored natively.
As IBM explains it – not strictly grammatically, to some English majors – a triple has a noun, a verb, and a predicate, such as Tim (noun) has won (verb) the MegaMillions lottery (predicate). You can then query all aspects of a set of triples to see who else has won MegaMillions – a short list, in this case.
In tests among DB2 10.1 early adopters, applications that used these graph triples ran about 3.5 times faster on DB2 than on the Jena TDB data store (short for triple database, presumably) with SPARQL 1.0 hitting it for queries.
DB2 10.1 for Linux, Unix, and Windows platforms also includes temporal logic and analysis functions that allow it to do "time travel queries" – functions that IBM added to the mainframe variant of DB2 last year. By now supporting native temporal data formats inside the database, you can do AS OF queries in the past, present, and future across datasets without having to bolt this onto the side of the database.
"This dramatically reduces the amount of application code to do bi-temporal queries," says Spang, and you can do it with SQL syntax, too. You can turn time travel query on or off for any table inside the DB2 database to do historical or predictive analysis across the data sets. RDF file format and SPARQL querying are available across all editions of DB2 10.1.
Like other database makers, IBM is fixated on data compression techniques not only to reduce the amount of physical storage customers need to put underneath their databases, but also to speed up performance. With DB2 9.1, IBM added table compression, and with the more recent DB2 9.7 from a few years back, temporary space and indexes were compressed.
With DB2 10.1, IBM is adding what it calls "adaptive compression", which means applying data row, index, and temp compression on the fly as best suits the needs of the workload in question.
In early tests, customers saw as much as an 85 to 90 per cent reduction in disk-capacity requirements. Adaptive compression is built into DB2 Advanced Enterprise Server Edition and Enterprise Developer Edition, but is an add-on for an additional fee for Enterprise Server Edition.
Performance boosts, management automation
On the performance front, IBM's database hackers have tweaked the kernel of the database to make better use of the parallelism in the multicore, multithreaded processors that are common today, with specific performance enhancements for hash joins and queries over star schemas, queries with joins and sorts, and queries with aggregation.
Out of the box, IBM says that DB2 10.1 will run up to 35 per cent faster than DB2 9.7 on the same iron. With all of the data compression turned on, many early customers are seeing a factor of three better performance from their databases. Which means – sorry, Systems and Technology Group – many DB2 customers are going to be able to get better performance without having to buy new iron.
On the management front, DB2 now has integrated workload management features that can cap the percentage of total CPU capacity that DB2 is allowed to consume, with hard limits and soft limits across multiple CPUs that are sharing capacity. You can also prioritize important DB2 workloads with different classes of service level agreements.
Database indexes now have new features such as jump scan, which optimizes buffer usage in the underlying system and cuts down on the CPU cycles that DB2 eats, as well as smart prefetching of index and data to boost the performance of the database, much as L1 caches in chips do for their processors.
DB2 now also has a multi-temperature data management feature that knows the difference between flash-based SSDs, SAS RAID, SATA RAID, and tape or disk archive, and can automagically move database tables that are hot, warm, cold, and downright icy to the right device.
Access control is a big deal, and DB2 10.1 now sports fine-grained row and column access controls so each user coming into a system can be locked out of any row or column of data. Now, employees only see the data they need to know, and you don't have to partition an application into different classes of users. You just do it at the user level based on database policies. This feature masks just the data you are not supposed to see.
IBM continues to ramp up its compatibility with Oracle's PL/SQL query language for its eponymous databases, and says that with the 10.1 release, early access users are seeing an average of 98 per cent compatibility for Oracle PL/SQL queries running against DB2. That's not 100 per cent, but it is getting closer.
Finally, as far as big features go, the other new one is called "continuous data ingest", which allows for external data feeds to continuously pump data into the database, or for the database to continuously pump into the data warehouse, without interrupting queries running on either box. This ingesting relies on bringing the data into the database and warehouse in a parallel fashion, with multiple connections, but exactly how it works is not clear to El Reg as we go to press. It seems a bit like magic.
DB2 Express-C is free and has the time travel feature; it is capped at two processor cores and 4GB of main memory. DB2 Express adds the row and column access control, label access control (an existing feature) high availability clustering features (new with this release), and has a memory cap of 8GB and can run across four processor cores; it costs $6,490 per core.
Workgroup Server boosts the cores to 16 and the memory to 64GB, and doesn't have the HA features. Enterprise Server has the multi-temperature data management feature and costs $30,660 per core. The top-end Advanced Enterprise Server has all the bells and whistles, including optimizations and tools to make DB2 play better in a data warehouse. Pricing for the Workgroup Server and Advanced Enterprise Server were not available at press time. ®
