Original URL: https://www.theregister.com/2013/04/16/teradata_infiniband_appliances_sql_h/
Teradata cranks appliance iron, adopts InfiniBand as cluster backbone
SQL-H to link Hadoop to both Teradata and Aster databases
Posted in SaaS, 16th April 2013 18:03 GMT
Another database and data warehousing vendor has adopted InfiniBand as its backbone for data transmission. While upgrading the x86 iron inside its Active Enterprise Data Warehouse appliance and rolling out a new data mart server, Teradata said it was ditching its proprietary networking hardware and moving its homegrown Bynet networking stack to run atop of 40Gb/sec InfiniBand switches and adapters.
The data warehousing juggernaut and NoSQL database and Hadoop wannabe also outlined its plans to allow the SQL-H extensions to the ANSI SQL query language to work with Teradata's distributed relational database at the heart of its data warehouses. It can already pull data from the Hadoop Distributed File System and suck it into the Aster NoSQL database.
Making the switch to InfiniBand
The data warehouses created by Teradata many years ago were based on its own Bynet networking hardware and a software stack that provided a point-to-point interconnect with high bandwidth and low latency that also had fault tolerance in those links.
This is just what you need in a parallel database machine that cannot lose connections to nodes to do complex queries. In the wake of Teradata's acquisition of Aster, the company created some data appliances that used 10 Gigabit Ethernet as a backbone, and last fall the company created an Aster appliance that used 40Gb/sec InfiniBand as the backbone between the server nodes in its clusters, which are sourced from Dell and Intel, depending on the machine and customer.
With today's update, Teradata is announcing that it has ported its Bynet 5 communications stack used in the Teradata database machines to run on top of 40Gb/sec InfiniBand. The company is using the 36-port IS5030 switch from Mellanox technologies across the appliance line to link nodes to each other, plus the ConnectX-3 server adapters, also from Mellanox. Teradata called this a "fabric-based hyper-speed nervous system," but was being overly dramatic.
Both IBM and Oracle use similar Mellanox switches at the heart of their Exadata and PureScale database appliances. The choice is no surprise, with Mellanox saying that the InfiniBand allows for as much as 20 times faster communication between the nodes thanks to the low latency built into the alternatives to Ethernet and Bynet hardware and software.
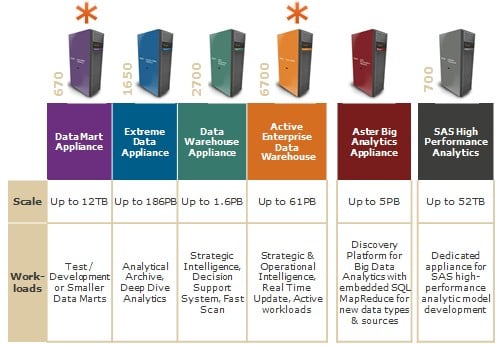
Teradata has refreshed its Active EDW and added a data mart
With 40Gb/sec InfiniBand available for Aster and Teradata machines and 10Gb/sec Ethernet available as an option for Aster machines - and as the default on Hadoop machines - Teradata can support all of the three key workloads that a data center needs and do so on substantially the same server iron. Or, more precisely, that is now true with the debut of the Active Enterprise Data Warehouse 6700, which also debuts this week. The Hadoop machines run on the same physical Xeon E5 iron as the Aster appliances that came out last fall.
The EDW 6700 comes in two flavors. The EDW 6700C comes with spinning disk only and uses six-core Xeon E5 processors spinning at 2GHz as the main processing engines in each two-socket server node. The machine has 128GB of main memory and uses 2.5-inch drives spinning at 10K RPM that come in 300GB, 450GB, and 600GB capacities.
Without compression, each node in the EDW 6700C cluster can provide from 12TB to 30TB of user data space, and you can put two nodes in a cabinet. This machine has a relative query performance rating of 91 TPerfs per node, according to the Teradata data warehouse performance scale.
If you want a faster version of this data warehouse, then you opt for the EDW 6700H, which moves up to eight-core Xeon E5 processors running at 2.6GHz and doubles up the node main memory to 256GB.
This system has a mix of 400GB solid state drives that you mix with the 10K RPM drives used in the other variant of this EDW for a total user data space that ranges between 7TB and 29TB per node - depending on the disk capacity and the number of SSDs chosen. The SSD-juiced machine has a relative performance of 167 TPerfs, which is 83.5 per cent more query oomph for the EDW 6700H compared to the 6700C.
In addition to this new EDW box, Teradata is rolling out a single-node version of the two EDW 6700 machines and calling them the Data Mart Appliance 670s. The purpose of this machine is to be a local (and relatively modest) data mart that is compatible with the bigger cluster. It can also be used as a development machine that programmers can mess around with, as it is running the same stack as the EDW but, crucially, is not a production machine with live data on it.
The DMA 670C is the disk-only node with the slower Intel Xeon E5 processors, while the DMA 670H has the faster processors and the SSDs. With storage, switching, and server components, this machine occupies about a third of a rack.
All of this iron runs SUSE Linux Enterprise Server 10 and supports the Teradata 13.10 parallel database. Pricing for these systems was not divulged.
Three (datastores) is the magic number
The fact that the Teradata database can now use the SQL-H extensions for Hadoop is a very big deal, particularly for sites with data warehouses that want to use Hadoop as a warm data store for information - stuff that has been stashed away in a data warehouse but which is too expensive to keep on that platform for long periods of time. Certain kinds of operational data that is unstructured - such as log data and clickstream data to name just two - is more easily and more inexpensively stored on Hadoop. But joining this data to data warehouses and other databases is no trivial matter.
That's why Teradata cooked up SQL-H, which was launched last summer as a means of seamlessly integrating Teradata's Aster NoSQL parallel database into Hadoop, using the metadata in the HCatalog layer for the Hadoop Distributed File System to put unstructured data into something that looks like tables and can be joined with Aster database tables. Now, you can do the same SQL-H trick with the Teradata database, and in either case the important thing is that you don't have to know jack about Hadoop to do it.
"We are not trying to keep data scientists from getting jobs," Chris Twogood, director of product and services marketing at Teradata, tells El Reg, "but the fact is that there are simply not enough of them." And so, you automate.
Moreover, any business intelligence tools that rely on SQL to extract data from data warehouses or production relational databases can now reach through SQL-H running in conjunction with Aster NoSQL or Teradata parallel relational databases and pull out Hadoop data in a tabular format that they know how to deal with.
In all cases, you use SQL-H to extract the data, which is now much faster thanks to the InfiniBand fabric on all of the clusters Teradata sells, and you run the queries on the Teradata data warehouse or the Aster NoSQL machine.
And finally, with the SQL-H approach, you don't have to give users direct access to the underlying Hadoop systems or make them learn Java and write MapReduce routines or use Pig, Hive, or HBase and worry about the security in these various features.
If users have access to a Teradata or Aster machine and you extend them the right to query data in HDFS through SQL-H, all of the same fine-grained security and data access rules that apply to Teradata and Aster machines will be extended to the Hadoop cluster.
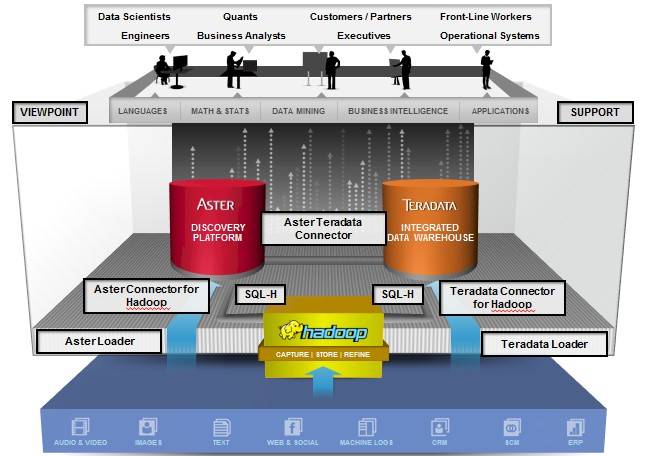
Three different data stores is better than one, says Teradata
With SQL-H, users only bring the data they need into the the Teradata or Aster machine to do a query, rather than pumping in big chunks of data raw or having to do a MapReduce run (or perhaps multiple ones) to much on big data sets and condense them.
At the moment, SQL-H is only supports the Hortonworks Data Platform 1.0 variant of Hadoop, which has the HCatalog metadata service on the Hadoop NameNodes. But Teradata is working with Cloudera to get the HCatalog functionality added to its CDH4 distribution so SQL-H will work there, too. The SQL-H query extensions for HCatalog are not open source, and Twogood said that the company had no intention of opening it up, either.
SQL-H is for importing data out of Aster or Teradata databases on an ad-hoc basis, but sometimes you want to browse the Hadoop data, poking around, and then do some importing of data from HDFS to Teradata . Or, you might want to download big gobs of bits from the data warehouse into Hadoop's HDFS. For this task, Teradata is launching a different tool, called Smart Loader for Hadoop, which works with its Teradata Studio data browser. This tool is like BigSheets in IBM's BigInsights variant of Hadoop, which organizes HDFS data into a big wonking spreadsheet that users can browse.
With Teradata Studio, both Teradata database and Hadoop HDFS data are revealed to business users as a series of tables and they can issue commands to move tables from one machine to the other with a simple point and click. Smart Loader is the feature that integrates with either HDP 1.0 or 1.1 or CDH4 to show HDFS data in table formats. It is being certified on HDP 1.2 now.
Teradata still has high-speed, bulk connectors, called Hadoop Connectors as you might expect, and it will continue to sell these for the really big data movement jobs. And there is another high-speed connector so you can move data between Aster and Teradata databases, too.
The new appliances from Teradata are available now, and so is Smart Loader for Hadoop, which is free. SQL-H has been shipping for the Aster appliances since the end of last summer and will ship on the Teradata appliances at the end of the second quarter. ®