Original URL: https://www.theregister.com/2013/04/03/ibm_puredata_hadoop_appliance_biginsights/
IBM readies PureData Hadoop appliance for the summer
Bolts Big SQL query onto its BigInsights Hadoop distro
Posted in SaaS, 3rd April 2013 23:46 GMT
IBM wants to make it easier for companies to consume and use Hadoop, just like everyone else who is chasing that yellow elephant that likes to munch big data.
Big Blue hosted a big data shindig at its Almaden Research Center in San Jose, the home of the RAMAC disk drive (really a disk drum) from 1956 and also the place where the company created the first relational database and the SQL programming language to ask it hard questions.
It is no surprise, then, that the bigwigs in IBM's Information Management division of Software Group, which also brought out the Flex System modular servers and various PureSystems system stacks aimed at particular processing workloads, would pick the IBM Research center in Almaden to host a day-long dog and pony show about how Big Blue understands big data better than anyone else, and how its myriad products can be mashed up to give the best results.
Everyone says the same thing, of course.
A new columnar data store and data compression technology called DB2 BLU Acceleration was announced at the event, which El Reg has covered separately. This is a columnar data store that is built into the DB2 10.5 database that
It is a wonder that this has not happened already, and in fact El Reg was guessing that it was already going to happen when the several different PureData appliance servers were launched last October and then again were refreshed with Power7+ processors back in February. But for whatever reason, IBM is only now talking about getting a PureData appliance with its own Hadoop distro out the door.
The announcement letter talking about the PureData System for Hadoop H1001 appliance is absolutely devoid of any useful information. It basically says it will run IBM's own InfoSphere BigInsights Hadoop distribution and will ship to customers so they can get a Hadoop cluster up and taking in data within a matter of hours. BigInsights also includes IBM's BigSheets visualization tool.
BigSheets was part of IBM's original BigInsights Hadoop release back in May 2010 and it presents summary information about the unstructured data stored in the Hadoop Distributed File System as cells in a spreadsheet, making it easier for data scientists to navigate.
IBM will also set up the HBase data warehousing layer for HDFS and will allow for information to be sucked out of HBase and displayed using BigSheets.
The BigInsights distro also has various kinds of "application accelerators," as IBM calls them, which means preconfigured data munching routines that its researchers have ginned up to chew on social media data for sentiment analysis, or sift through machine-generated data for patterns, or do text analysis or risk analysis.
The PureData appliance will be based on x86 server nodes of some kind (the announcement letter actually says System x brand) and will have a single console to manage the entire Hadoop cluster and the underlying hardware. That probably means it will not be based on proper PureFlex x240 or x440 server nodes, mainly because IBM has not created fat server nodes with lots of internal disk.
The way the PureFlex iron is architected, the server nodes have only two local disks and you are supposed to store everything on external (to the server node, but not to the Flex Chassis) Storwize V7000 arrays.
This is the antithesis of the kind of cheap and fat disk storage that Hadoop requires to give it the price/performance advantage it enjoys. So this will be a PureData machine that is not actually based on the new PureFlex iron, we surmise.

Not much is known about this impending
PureData Hadoop box
Phil Francisco, vice president of big data product management and strategy at IBM, didn't give away much on the PureData Hadoop appliance in his presentation, but said that with the appliance, customers would be able to get Hadoop up and running at least eight times faster than trying to build their own cluster and load up software.
He also said that one of the use cases would be to use Hadoop as a kind of cold data storage for data warehouses, allowing for old data from the warehouse to be offloaded to HDFS and yet still be in a system where it could be queried. (Albeit more slowly and in batch mode instead of in the near-online ad hoc method of a data warehouse.)
Another use case is to use Hadoop as a point of aggregation of data from disparate sources – clickstream data, various social media streams, and so on – which get prechewed so subsets of that data can get passed on to other systems where it can be used for simple analytics and data exploration.
The announcement letter says that the PureData Hadoop appliance will be available in the second half of this year, starting with a full rack configuration and then delivering smaller and larger setups. IBM's press release says the new release of BigInsights, version 2.1, which will run on the appliance and which will also be available as a standalone product, will be available in the second quarter.
IBM will be selling three different editions of BigInsights 2.1, as you can see:
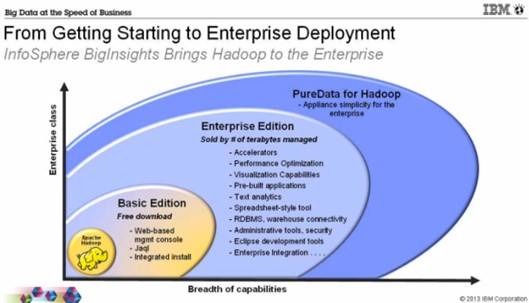
BigInsights 2.1 will come in Basic, Enterprise, and Appliance versions
The hot new feature in this release will be something called Big SQL, which Inhi Cho Suh, vice President of product management for the Information Management division, said in a presentation would provide an ANSI-compliant SQL interface to data stored in Hadoop.
"One of the inhibitors for the adoption of big data has been a lack of skills," Suh explained, and said that giving Hadoop the ability to speak SQL proper would make it easier for companies to adopt since most of them know how to use SQL in both the programming and marketing cubicles.
Exactly how IBM is making Hadoop speak proper SQL is not entirely clear. EMC's Greenplum unit, soon to be part of the Pivotal spinoff of big data and application framework assets from VMware and EMC, has ripped the SQL parser from its parallel database at the heart of its data warehouse and married it to HDFS so it can do SQL queries.
This Greenplum feature for Hadoop is called Hawq, and is it possible that IBM has ripped some of the SQL parsing technologies from DB2 and done much the same thing.
However, only a week ago, RainStor was bragging about how it was working with IBM to put its big data analytics software, which has de-duplication and SQL query functions that it adds to its own database, on top of IBM's BigInsights. This may be how IBM is doing it, and then again, it may not be. IBM was not available for clarification at press time.
The Basic Edition of BigInsights is meant for developers and not production workloads. It does not have the full feature set. The Enterprise Edition has all of the bells and whistles, and will be sold based on the terabytes of data under management; exactly how much, IBM is not saying. And the final edition will be bundled in the PureData Hadoop appliance, which will include all of the add-ons mentioned above.
In other news, IBM said that it would now allow for its BigInsights Hadoop distribution to run on the z/BladeCenter Extension (zBX) blade server enclosures that hang off the internal mainframe networks and are closely coupled to its last two generations of System z mainframes to turn them into a "system of systems." As IBM puts it.
That puts Hadoop under the thumb of the mainframe without having to go so far as to port the Hadoop stack to the mainframe proper. It's just a bunch of Java code, so it could be done, but at hundreds of thousands of dollars per core, a mainframe is a terrible thing to run Hadoop on from an economics standpoint even if it might be an interesting technical stunt.
IBM is also beta testing directly links between Hadoop and its DB2 11 and IMS 12 and 13 mainframe databases. No word on when these Hadoop pipes will go into production, but again, the idea is to get mainframes dumping data into Hadoop or sucking it out. ®