Original URL: https://www.theregister.com/2013/03/22/ge_rdma_gpudirect_denver_gpu_super/
GE puts new Nvidia tech through its paces, ponders HPC future
Hybrid CPU-GPU chips plus RDMA and PCI-Express make for screamin' iron
Posted in HPC, 22nd March 2013 16:27 GMT
GTC 2013 A top General Electric techie gave a presentation at the GPU Technology Conference this week in San José, California, and discussed the benefits of Remote Direct Memory Access (RDMA) for InfiniBand and its companion GPUDirect method of linking GPU memories to each other across InfiniBand networks.
And just for fun, the GE tech also specced out how he would go about building supercomputers using Nvidia's future hybrid CPU-GPU chips based on the "Project Denver" cores that Nvidia has been working on for the past several years.
Don't be at all surprised that GE is fiddling about with Nvidia chippery. The company does a lot of different things, and one of them is make military-specification computing and visualization systems for fighter jets, tanks, drones, and other weapons systems. Given the nature of the systems it creates, GE has become an expert in chips and network-lashing technologies, particularly given the real-time nature of the data gathering and processing that military systems require.
The GE techie who spoke at Nvidia's event was Dusty Franklin, GPGPU applications engineer at GE's Intelligent Platforms division, and Nvidia introduced his session at the conference saying he was one of the world's experts on RDMA and GPUDirect.
Speeding up the access to the memory in GPU coprocessors is important, Franklin explained, because the systems for which GE is building compute components are taking in lots of data very quickly. You have to get the CPU out of the way and just let the FPGA preprocess the data streaming in, and then pass it over to the GPU for further processing and analysis that the application running on the CPU can use.

GE's IPN251 hybrid computing card marries a Core i7, a Xilinx FPGA, and an Nvidia Kepler GPU with a PCI switch
On plain old CPUs, RDMA allows CPUs running in one node to reach out through an InfiniBand network and directly read data from another node's main memory, or push data to that node's memory without having to go through the operating system kernel and the CPU memory controller. If you prefer 10 Gigabit Ethernet links instead, there is an RDMA over Converged Ethernet, or RoCE, wrapper that lets RDMA run on top of Ethernet – as the name suggests.
With GPUDirect, which is something that InfiniBand server adapter and switch maker Mellanox Technologies has been crafting with Nvidia for many years, the idea is much the same. Rather than having a GPU go back to the CPU and out over the network to get data that has been chewed on by another GPU, just let the GPUs talk directly to each other over InfiniBand (or Ethernet with RoCE) and get the CPU out of the loop.
The PCI-Express bus has been a bottleneck since companies first started offloading computational work from CPUs to GPUs. At first, GPUs could only do direct memory access to the system memory on the node they were plugged into over the PCI bus. If you wanted to get data from another PCI endpoint, such as an FPGA or an Ethernet or InfiniBand network interface card, then you had to copy it first into system memory, into user spaces, and then push it out to the GPU.
But with the latest Kepler-class GPUs from Nvidia and its GPUDirect feature (also cooked up with Mellanox), if you use the CUDA 5 development framework GPUs can directly access memory in other GPUs over the network without talking to the CPU or its memory. Equally importantly, other devices hooked to the systems can pump data into and out of the GPUs without asking permission from the CPU, too.
What's the big deal, you say? The latency and throughput improvements with GPUDirect are rather dramatic, and when coupled with PCI-Express switching to link various computing elements, GE and others can create very sophisticated – and scalable – hybrid computing systems.
To prove that point, Franklin and GE's engineering team ran some tests of the combination of RDMA, GPUDirect, and PCI-Express switching between components on a shiny new IPN251 card, which has a little bit of everything on it.
The computing element on this battle-tested embedded computing and visualization system is an Intel quad-core 3rd Generation Core i7 processor, which has 16GB of DDR3 main memory allocated to it. This x86 chip is piped out to a PCI-Express switch, which has a Gen 1.0 link going out to a Xilinx Virtex-6 FPGA (that's the fastest bus link on that chip) and another Gen 3.0 link that hooks into a 384-core Kepler GPU with 2GB of its own GDDR5 graphics memory. The PCI switch also links into a Mellanox ConnectX-3 server adapter chip, which presents one InfiniBand port and one 10 Gigabit Ethernet port to the outside world.
For the real-time applications that GE is targeting with the IPN251, the important thing is to be able to take in signals from remote sensors, chew on them with the FPGA's custom algorithms and then quickly pass that data onto the GPU for rapid signal processing, with information then available for the CPU where the application is running.
Without RDMA and GPUDirect enabled, getting that data from the FPGA through the CPU memory stack and then into GPU is very CPU-intensive. And as the chunks of data ripping through the system get bigger, the latencies get longer and longer as the batch size increases. That PCI-Express 1.0 x8 link coming off the FPGA has its limits, but you can't even come close to pushing it as hard as the 2GB/sec limit it has in theory.
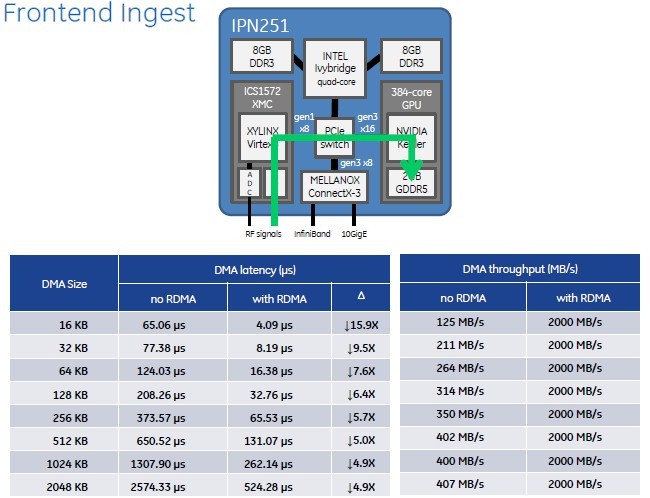
RDMA and GPUDirect really kick up the performance on the IPN251 hybrid card
For a 16KB DMA operation without RDMA and GPUDirect, there is a 65.06 microsecond latency and the data is coming into the GPU at around 125MB/sec. For anything above 256KB, performance flattens out to around 400MB/sec or so into the GPU and latencies climb very fast to 2.6 milliseconds. That is not a real-time system for a lot of mil-spec apps.
But turn on RDMA and GPUDirect and get the CPU monkey out of the middle. Now, regardless of the size of the chunk of data you are moving, GE found that it could pump data out of the FPGA and into the GPU at 2GB/sec, which is the peak load that the PCI-Express 1.0 x8 bus coming of the FPGA can deliver. Latencies on large data transfers are about five times lower, and on small chunks of data they approach 16X.
Not bad, not bad at all – but wait, there's more
This is a big improvement in terms of lower latency and higher throughput, obviously. And it would also seem to indicate that Intel will need to come up with something akin to PhiDirect to offer similar capabilities for its Xeon Phi parallel x86 coprocessor, and indeed, AMD would have to do the same for any FirePro graphics cards it wants to peddle as compute engines in hybrid systems if it wants to squeeze performance and get the CPU out of the memory loop.
RDMA with the GPUDirect feature and PCI-Express switching is not just for mil-spec gear providers such as GE, of course. Server makers have already come up with systems that use PCI-Express switches to gang up multiple GPUs to CPUs to get the ratio of GPU compute to CPU compute more in whack, and to actually enable the GPUs to do calculations according to their inherent capability.
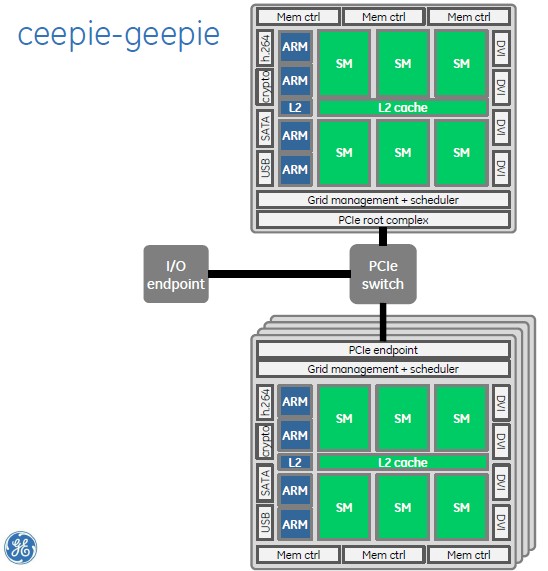
This is a big step from the early days, explained Franklin, when a ceepie-geepie node looked something like this:

Before GPUDirect, each CPU managed a GPU and spent most of its time starting CUDA kernels
The typical node had two CPUs, each with their own main memory block and their own GPU hanging off it; an I/O endpoint hung off the PCI-Express bus that linked the GPUs to the CPUs and both to the other nodes in a parallel cluster. You had to go through the CPU memory stack to move data into and out of the GPU, and between that memory management job and the launching of CUDA kernels on the GPU, the CPUs were so saturated that they had trouble actually running their applications.
You certainly could not hang more multiple GPUs off a single CPU because it would have choked to death. Still, as you can see from the single-precision and double-precision matrix multiplication benchmark results in a typical setup using Xeon E5 and Kepler K20X GPUs, the gigaflops-per-watt of the combination was much better than what you could get from the CPUs alone.
Enter the PCI-Express switch and RDMA with GPUDirect memory addressing. Now, you can hang four GPUs off of a single processor, and according to Franklin, only a fraction of a core is busy launching CUDA kernels as applications run, and the memory overhead is much diminished. And now you can get a significant improvement in gigaflops-per-watt coming out of the resulting system.
But don't stop there. You can daisy-chain PCI-Express switches and push it out like this:
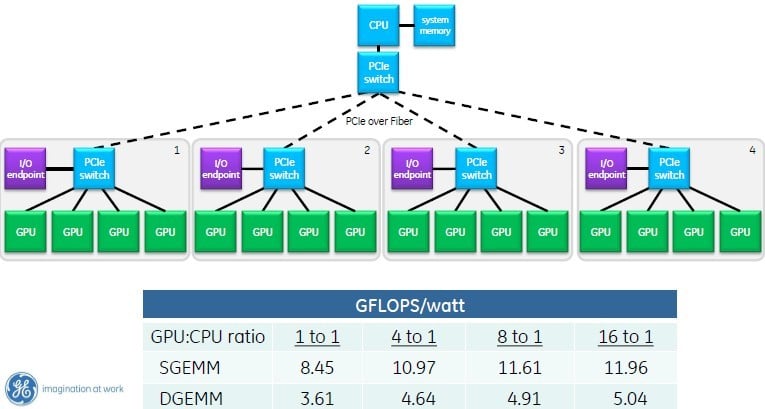
With GPUDirect, RDMA, and nested PCI switches, you can hang up to sixteen GPUs off one CPU (click to enlarge)
The current crop of PCI-Express 3.0 switches top out at 96 lanes of traffic, and you can drive five x16 slots on them. Or you can drive four and leave some lanes to talk upstream in the nested arrangement that Franklin cooked up in the chart above.
Now, instead of getting 8.45 gigaflops-per-watt single precision and 3.61 gigaflops-per-watt double precision, you can push that up considerably – try 41.5 per cent more power efficiency at single precision and by 39.6 per cent at double precision. (These figures include the heat generated by the PCI switches and also take into account the latencies added by the PCI networks.)
So here is the net effect this all has, by Franklin's math, on the cost of the ceepie-geepie computing complex in a 10-petaflops parallel supercomputer with various CPU-to-GPU ratios:
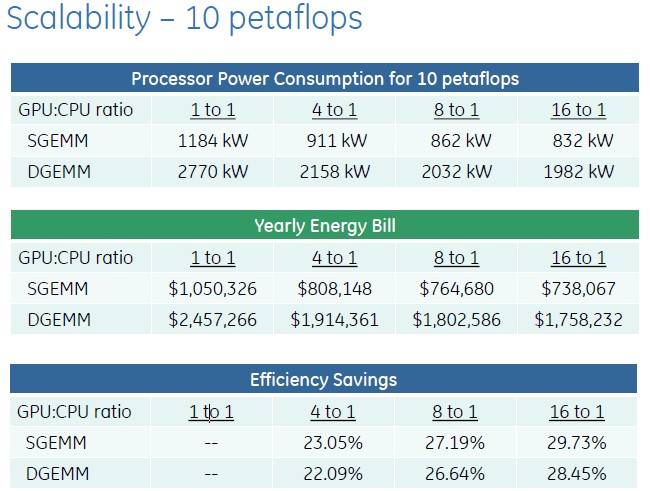
Scaling up the CPU and GPU compute using PCI switching saves energy and money
Franklin called this a "typical machine," which got some chuckles from the peanut gallery of El Reg hacks and their dubious associates seated in the front row.
There's plenty of data to play with in this table, and this just includes the electricity consumed by the CPU, GPU, and PCI-Express switching, if the latter is present, and the cost of that electricity at the national US average of 10 cents per kilowatt-hour for industrial companies (rather than consumers).
Obviously, with fewer CPUs driving the GPUs, you can burn a lot less juice as well as allocate more of the money for GPUs than CPUs. By going with a 16:1 GPU-CPU ratio, Franklin calculates that you can save close to 30 per cent on the electric bill on a 10-petaflops super. Those energy savings can be plowed back into software development or incremental scaling of the cluster. (We know; every one of us would buy more hardware with the savings.)
And here's where it gets really interesting
Nvidia's "Project Denver" is an effort to bring a customized ARMv8 core to market that can be deployed in both Tegra consumer electronics products and in Tesla GPU coprocessors. Nvidia has been pretty vague on the details about Project Denver, with the exception of saying it will deliver the first product using this ARM core mashed up with the "Maxwell" GPU in the future "Parker" hybrid Tegra chips – presumably called the Tegra 6.
But we know that Nvidia will also create higher-end Tesla products aimed at HPC, big data, and visual computing workloads. Just for fun, and presumably based on some insight into Nvidia's possible plans, Franklin ginned up what he thinks a Tesla-class ceepie-geepie system-on-chip might look like. (Admittedly, it could be a system-on-package. We just don't know.)
That theoretical ARM-GPU mashup would have four Denver cores on the die, with their own shared L2 cache memory. This mashup would also have six SM graphics processing units with their own shared L2 caches. Three memory controllers run along the top and have the unified memory addressing that will debut with the "Maxwell" GPUs perhaps late this year or early next.
The chip would have various peripheral controllers down the side and DVI ports on the other side, and then a Grid management and scheduler controller to keep those SM units well fed, and an on-die PCI-Express controller that could be configured in software as either a PCI root complex or endpoint. That last bit is important because you could then do something like this:
How GE techies might build a cluster with Project Denver ARM cores and future GPUs from Nvidia
With PCI-Express on the chip, Nvidia could put a complex of sixteen ceepie-geepie chips on a single motherboard, delivering a hell of a lot of CPU and GPU computing without any external switching. RDMA and GPUDirect would link all of the GPUs in this cluster to each other, and it is even possible that Nvidia could do global memory addressing across all sixteen ceepie-geepie chips. (El Reg knows that Nvidia wants to come up with a global addressing scheme that spans multiple nodes, but it is just not clear when such technology will be available.)
You would then have a networking endpoint of choice coming off this sixteen-way ceepie-geepie cluster to link multiple boards together. I think a 100Gb/sec InfiniBand link is a good place to start, but I would have preferred the Cray Dragonfly interconnect that was developed under the code-name "Aries" that is at the heart of the Cray XC30 supercomputers, and that is now owned by Intel.
At the moment, GPUDirect only works on Linux on Intel iron, so it would be tough to play Crysis on such a theoretical ceepie-geepie supercomputer as Franklin outlines above. But Linux works on ARM, and GPUDirect will no doubt be enabled for Nvidia's chips. All we need is a good WINE hardware abstraction layer – remember, "Wine is not emulation" – for making x86 Windows work on top of ARM Linux, and we are good to go. ®