Original URL: https://www.theregister.com/2012/11/29/amazon_aws_ec2_update_data_pipeline/
AWS fattens EC2 cloud for big data, in-memory munching
Data Pipeline service links data sources, automates chewing and spitting
Posted in Virtualization, 29th November 2012 21:04 GMT
re:Invent Werner Vogels, the Amazon CTO who also knows a thing or two about the Amazon Web Services cloud, kicked off the second day of the re:Invent partner and customer conference in Las Vegas with a long lecture about how cloud computing enables people to think about infrastructure differently and code applications better. Interspersed among his umpteen Cloud Coding Commandments, Vogels actually sprinkled in some news about two new EC2 compute cloud instances and a new data service that will make it easier for AWS shops to both move data around inside the cloud, and to use said data.
The first new EC2 slice is called the Cluster High Memory instance, or cr1.8xlarge in the AWS lingo, and it comes with 240GB of virtual memory and two 120GB solid state drives associated with it.
Vogels did not reveal the amount of EC2 compute units (or ECUs) of relative performance that this Cluster High Memory instance has associated with it, and the online AWS EC2 specs have not yet been updated to reveal its pricing either. But given its name, it is probably just a Cluster Compute 8XL image, which has 88 ECUs of oomph, with extra memory and some SSDs attached to it.
"If you run any app with large-scale in-memory processing, this is the instance type you want to use," said Vogels of the high-memory virtual slice.
The second new instance is also an extreme one, but one that's heavy on the disk drives and moderately heavy on the virtual memory. The High Storage instance, or hs1.8xlarge by feature designation, has 117GB of virtual memory with two dozen 2TB drives for a total of 48TB of capacity associated with it. Given that it is an 8XL derivative, hs1.8xlarge probably has 88 ECUs of performance as well – but again, AWS has not yet said.
This one is obviously aimed at big data/analytics jobs, and Vogels said it was particularly well-suited as an instance on which to build a virtual cluster to run Amazon's Elastic MapReduce service, which runs the Hadoop data muncher as a service.
AWS did not say when these new EC2 instance types would be available, or at what price.
Save everything, waste nothing
One of Vogels' commandments is to put everything – and he means everything – into log files, and to save all of the data you generate.
You would expect someone who is peddling raw capacity and services to chew on it to say that, of course. But his point goes beyond self-interest since you can only analyze the data you keep and the things that you measure.
Amazon has its Relational Database Service (based on MySQL, Oracle, and SQL Server databases) for transactional data, the DynamoDB NoSQL data store for certain kinds of unstructured data, the Elastic MapReduce service and its Hadoop Distributed File System (HDFS) store, and the S3 object storage and EBS block storage services as well.
On Wednesday, AWS launched the Redshift data warehousing service, which will store data in yet another container on the AWS cloud. Companies have their own data sources beyond this. And moving all this data around, and converting it from one form to another, is a real pain in the neck.
And to that end, AWS is rolling out a new service called Data Pipeline to automagically move data between the various Amazon data services and various homegrown and third-party analytics tools.
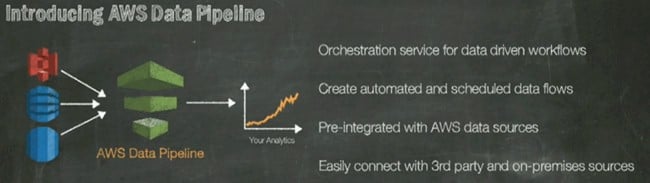
The AWS Data Pipeline service automates data movement and reporting
The service will also connect to third-party data sources and link into data that is stored in your own systems if you run analytics out on the AWS cloud. The Data Pipeline details were a little sketchy, but Vogels said it was an orchestration service for data-driven workflows that would be pre-integrated with Amazon's various data services.
Here's what a workflow looked like that Matt Wood, chief data scientist at AWS, demonstrated working in a live demo:
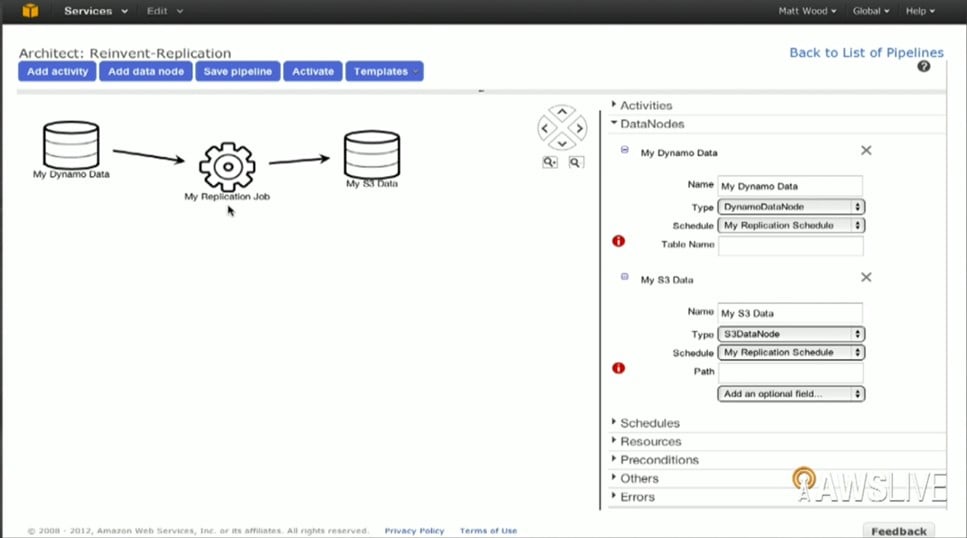
Screenshot of AWS Data Pipeline using Hadoop to move data to S3 (click to enlarge)
In this particular case, a slew of data that was stored in DynamoDB was extracted by the Elastic MapReduce service using the Hive query feature of Hadoop to dump summary data into the S3 object store. This data was then made available to analytics applications and could then kick out reports based on that summary data.
It is not clear how Data Pipeline will do format conversions between all of the data sources, or if Amazon intends to charge for the pipes. It could turn out that Amazon gives the service away for free or a nominal fee with the expectation that companies will make heavier use of EC2 and various data stores if the movement if data between these data stores is automated.
That leaves the Commandments of Cloud Computing, which Vogels brought down from on high in the Seattle Space Needle. They are:
- Thou shalt use new concepts to build new applications
- Decompose into small, loosely coupled, stateless building blocks
- Automate your application and processes
- Let business levers control the system
- Architect with cost in mind
- Protecting your customer is the first priority
- In production, deploy to at least two availability zones
- Build, test, integrate, and deploy continuously
- Don't think in single failures
- Don't treat failure as an exception
- Entia non sunt multiplicanda praeter necessitate (aka Occam's razor)
- Use late binding
- Instrument everything, all the time
- Inspect the whole distribution, not just the mean
- Put everything in logs
- Make no assumptions, and if you can, assume nothing
If you understood all of that, then you are ready to launch your startup on AWS and go chase some VC money. And even if you didn't understand it all, don't let that stop you. ®