Original URL: https://www.theregister.com/2012/11/08/cray_cascade_xc30_supercomputer/
Cray scales to over 100 petaflops with 'Cascade' XC30 behemoth
Aries interconnect, Dragonfly topology crush Gemini toruses
Posted in HPC, 8th November 2012 08:02 GMT
Hot on the heels of the delivery of the 20-plus petaflops "Titan" CPU-GPU hybrid supercomputer to Oak Ridge National Laboratory last week, Cray has launched what is unquestionably a much better machine, the long-awaited "Cascade" system developed in conjunction with the US Defense Advanced Research Projects Agency and sporting the new "Aries" interconnect.
The Aries interconnect is so important to hyperscale and parallel computing that Intel shelled out $140m back in April to get control of the people who created the Aries and predecessor "Gemini" interconnects, the chip designs themselves, and the 34 patents associated with them.
Cray retained exclusive rights to the use of Gemini and Aries, so you are not going to be able to buy an Aries chip at Newegg and build your own XC30 supercomputer. (Sorry.) Further down the road, Cray and Intel are working on a common supercomputer design called "Shasta," which may or may not use an interconnect similar to the fifth generation "Pisces" interconnect that Cray was kicking around as an idea two years ago.
What we do know is that Intel will be footing most of the bill for whatever the Shasta interconnect is, which suits Cray fine, apparently.
Now that Cascade is launched, Cray is willing to talk about a few things that were not disclosed about the project. Barry Bolding, who is currently vice president of storage and data management at Cray, worked at Cray Research two decades ago, then left to work for IBM for a while. Bolding came back to Cray when Peter Ungaro, who used to run the HPC biz for Big Blue, asked him to return to Cray and, specifically, to handle Cascade.
"This project was my baby for a while, and it was a very tough time on us," Bolding tells El Reg. But as the Gaffer says in Lord of the Rings, "All's well as ends better."
First, and this was a bit surprising, DARPA does not actually get its own Cascade machine for all of the money that it spent on Cascade development, but rather has access to a machine installed elsewhere for a number of months. Then if DARPA thinks the machine passes muster, the branches of the US military can decide on their own whether to buy a machine or not.
Cray gets to monetize all of DARPA's investments, as it did with prior systems funded by the government. It's good work, if you have the nerves of steel to keep your wits in the low-margin, high-stakes supercomputer racket.
In phase one DARPA's High Productivity Computing Systems program in 2003, Cray originally received $43.1m to begin work on the Cascade line of machines, which sought to converge various machines based on x86, vector, FPGA, and MTA multithreaded processors into a single platform. (GPU accelerators were not yet on the scene.)
In phase two of the HPCS effort, Cray received a $250m award in 2006 to work further on Cascade and also to create its Chapel parallel programming language, which is available now and open source.
IBM got $244m to work on its PERCS system, which was similar to but not the same as the ill-fated "Blue Waters" Power7-based 20 petaflopper that Big Blue pulled the plug on at the University of Illinois last year, leaving Cray wide open to win a $188m deal with an XK7 Opteron-Tesla hybrid machine.
Anyway, in January 2010, DARPA scaled back the Cray Cascade funding by $60m, and neither DARPA nor Cray ever explained why.

The XC30 supercomputer, formerly known as Cascade
Now, we know. According to Bolding, Cray was going to take the work it had done on its multistreaming vector processors and massively multithreaded ThreadStorm processors and create a new processor of its own to go along with the Aries interconnect.
"We eventually made the tough decision to focus on the interconnect," says Bolding. And that has clearly paid off, and as it turns out, has made it easier for Cray to embrace GPU and x86 coprocessors like Nvidia's Tesla and Intel's Xeon Phi as adjunct and more efficient compute engines alongside x86 processors inside its systems.
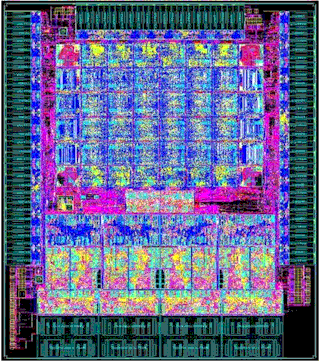
Die shot of the Aries interconnect chip
You can't blame Cray or DARPA or both for backing out of Cray's idea to create its own processor, particularly after Cray hitched its entire wagon to the Opteron processors from Advanced Micro Devices with the "SeaStar" XT and Gemini XE interconnects used in the similarly named XT and XE series of parallel supers.
Look at all the woe that comes from designing and fabbing processors, and how the Opteron delays time and again whipsawed Cray's revenues and profits. Worrying about interconnect chips was hard enough. And now, after Intel's shrewd move, that is Chipzilla's problem.
However, with Cray not doing interconnects or processors, that does call into question what its value-add will be during the Shasta generation of machines due around 2016.
Those XT and XE interconnects plugged directly into the HyperTransport ports of the Opteron processors. With the Aries XC interconnect, which is apparently short for Extreme Computing, Cray is plugging directly into the on-chip PCI-Express 3.0 controllers on the Xeon E5-2600 processors, which have plenty of bandwidth and which gives Cray the option of letting Aries speak directly to any other device – be it a CPU, a GPU, or some other kind of computing or storage element – that has a PCI-Express 3.0 port.
The way I have heard it described in the past, Gemini was not initially in the roadmap, but the US government wanted something between SeaStar and Aries as an interim device, offering somewhere between the scalability of the two while retaining the 3D torus interconnect that prior XT machines had used.
So Gemini is a less-capable high-radix router that implements the 3D torus interconnect familiar with the XT machines instead of the new "Dragonfly" topology of the Aries interconnect and used in the XC machines.
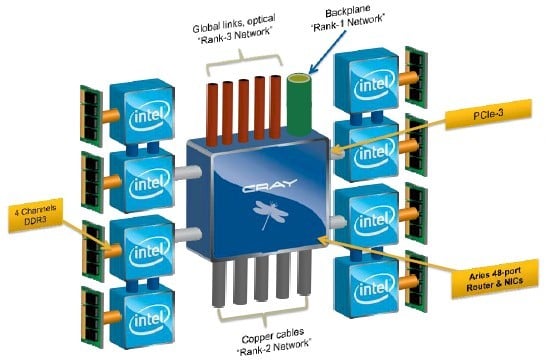
Schematic of the Aries interconnect and Cascade nodes
Let's go over the Aries interconnect itself first and how it compares to Gemini, then discuss the Dragonfly topology.
The Gemini interconnect, as El Reg detailed in May 2010 when it launched, had a 48-port high radix router called Yarc-2 (which was short for Yet Another Router Chip and also Cray spelled backwards) This router was used to virtualize links to the processors through four HyperTransport links to two pairs of Opteron processors.
The Gemini router had 168GB/sec of aggregate bandwidth and created two virtual network interfaces for each two-socket Opteron node hanging off the HyperTransport on one side of the chip and routed traffic out to other nodes in an XE6 all-Opteron and now XK7 Opteron-Tesla hybrid system through six ports on the other side of the router.
As you can see in the schematic above, the Aries chip is a 48-port routers as well, but it is implemented in a different way. Aries has four PCI-Express 3.0 pipes that link each two-socket Xeon E5 node into the chip.
The router's ports are bundled up to provide three different kinds of connectivity, linking nodes to a XC30 system chassis backplane for local hops, to copper cables that lash six enclosures (two racks) of machines to each other through standard copper cables, and to optical cables that link multiple racks together in a single XC30 system. Cray calls the backplane network Rank 1, the rack link network Rank 2, and the cross-rack optical links Rank 3.
Cray forges Aries in the war for on toruses
The Aries chip has 217 million gates and Cray has chosen Taiwan Semiconductor Manufacturing Corp as the foundry to build it, and uses its 40 nanometer processes for etching. Cray has used IBM as a foundry in the past for interconnect chips, but being rivals in the supercomputer racket, Cray is no doubt more comfortable with TSMC these days.
The Aries chip has 184 SERDES lanes, with 30 being optical links, 90 being electrical, and 64 being PCI-Express. Cray has reserved the right to tweak the Aries chip if needed as part of its deal with Intel, and enhanced versions could come out between now and 2016. But Cray is making no promises.

The Cascade chassis sticking its blade tongue out
The XC30 system has half-width, full-depth horizontal blades that contain a base with a single Aries interconnect on the back of the blade. This Aries chip links into the chassis backplane and the four server nodes on the blade.
These blades are implemented on what Cray calls a processor daughter card, and the all-CPU version has two of these processor daughters(two two-socket nodes) that sit side by side in the chassis and link to the Aries interconnect via PCI-Express pipes, for a total of four nodes per blade.
Incidentally, with the XE6 machines, you needed two Gemini chips on each blade to connect four two-socket Opteron nodes into the Gemini interconnect. But with the Aries machines, with their different Dragonfly topology, you only need one Aries chip for the four nodes on the blade. This will be a big cost savings for Cray.
Those processor daughter cards have four Xeon E5 sockets (linked in pairs by Intel's C600 chipset) and have four memory slots per socket.
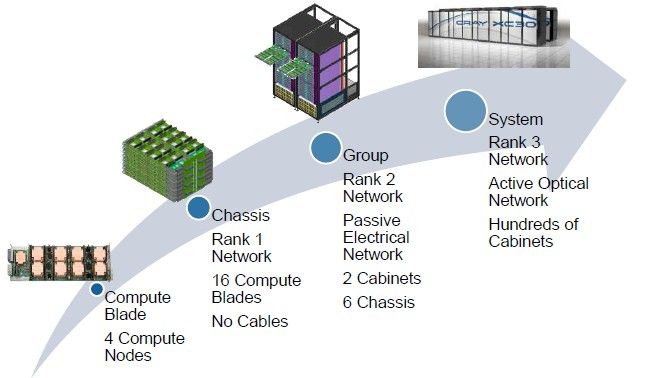
How the Cascade system is built up
Cascade uses custom cabinets that are slightly bigger than industry standard, which is something you can get away with when you are selling supercomputers that cost tens to hundreds of millions of dollars and data centers are built around them.
There are four nodes on each Cascade blade, and you put sixteen of these into a chassis. The cableless Rank 1 network is used to link the blades in the chassis together. You put three enclosures in a rack and two racks side-by-side, and this is a Cascade group.
This uses a passive electrical network to link the nodes together through the Aries interconnect controllers. Using current Xeon E5 processors and no x86 or GPU accelerators, these two cabinets yield around 120 teraflops of peak computing performance.
An XC30 system has hundreds of cabinets and uses an active optical network, which also hangs off those Aries chips, to link nodes to each other. A top-end system would have close to 200 cabinets, the same size as the "Jaguar" and now "Titan" supercomputers at Oak Ridge, but offer twice the number of x86 sockets per cabinet due to more dense packaging.
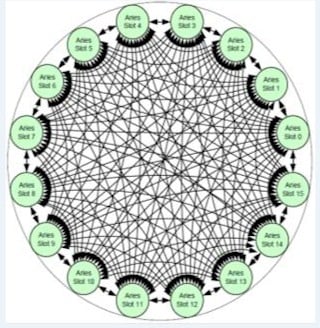
The Dragonfly topology implemented by the Aries chip
Bolding says that Titan at 200 cabinets and "Blue Waters" at the University of Illinois, which is slated to eventually have 276 cabinets, pushes the limits of the Gemini interconnect. And as you scale up, adding more dimensions to the torus perhaps, you reach some limits.
Cray is very fond of the 3D torus that SeaStar and Gemini did, but it shifted to the Dragonfly interconnect, designed by former Cray CTO Steve Scott (now at Nvidia as Tesla CTO) and Bill Dally, a hot-shot compsci expert at Stanford University who does double duty as Nvidia chief scientist.
"Torus is something we really like, but it's expensive," explains Bolding. "Dragonfly gives you all of the bandwidth of fat tree, but at the cost of a torus. And Dragonfly is free from the locality of the torus, too."
That is because the new Dragonfly interconnect allows all of the nodes talk directly to each other, which means you don't have to try to have nodes physically adjacent to each other that are doing computationally adjacent work to avoid a heavy latency penalty.
Not every node is only one hop away, of course. On a fully configured system, you are five hopes away maximum from any socket, so there is some latency. But the delta is pretty small with Dragonfly, with a minimum of about 1.2 microseconds for a short hop, about 1.5 microseconds for an average number of hops (three-ish), and a maximum of 1.7 microseconds for the five-hop jump, according to Bolding.
That latter bit of magic – low latency for five hops – is made possible by the adaptive routing coded into the Aries interconnect. "There are multiple routes from any node, and we can re-route to avoid congestion," says Bolding. "So it doesn't matter where you place jobs. In fact, a random assignment of jobs is probably better, unlike a torus interconnect, which wants jobs to be localized."
Cray is still putting together the performance specs of Aries, but Bolding dropped a few hints. The injection rate out of any PCI-Express 3.0 port on real workloads into the Aries interconnect is on the order of 8GB/sec to 10GB/sec. The more you load up the XC30 machine, the better it performs compared to the XE6 machine.
At a chassis level, the loaded injection bandwidth is on the order of 2X of that on the XE machine, and on a big box with ten cabinets or more where the whole system is used, its more on the order of 3X. The Dragonfly topology and Aries interconnect has 20X the global bandwidth as the 3D torus-Gemini combo, too.
The other thing that is important about the Dragonfly topology is that it is easier to build up. On the Blue Waters machine that Cray is building, you can't just add one cabinet to the box because you have to build on the 3D torus in a way that everything can still route to everything else.
In fact, you have to add a row of a dozen cabinets at a time to keep the shape of the torus. With Aries, you can add a single group at a time, which is only two cabinets.
Assuming a certainly level of CPU performance enhancements and the addition of GPU or x86 coprocessors, Bolding says that the Aries machine will be able to scale well above 100 petaflops over the next three to four years.
To add support for Intel's Xeon Phi x86 coprocessor or Nvidia's Tesla K20 coprocessor, you just take out half one of the processor daughter cards with CPUs and add a new one in with accelerators. The CPU cards link to the accelerators over PCI-Express, and then on the other side the CPUs link to Aries through PCI-Express links.
Cray did not announce pricing on the XC30 system, but Bolding said that the intent of the design was to bring more scalability at about the same cost per socket as the XE6 systems.
Cray has shipped six early Cascade systems already – HLRS in Germany, Kyoto University in Japan, NERSC in the US, CSC in Finland, Pawsey in Australia, and CSCS in Switzerland, all deals that El Reg has covered – and will make the machines generally available in the first quarter of 2013, as planned.
Cray did not announce any intent to support Opteron processors with the XC30 systems, as it has not for several years now, and that stands to reason considering how tightly Cray's future is linked to Intel. But equally importantly, the Opteron chips, even the Opteron 6300s announced this week, do not support PCI-Express 3 links either through the chipset or the CPU itself. That's a problem right there.
As for the future, what Cray would say is that it is working on a midrange Cascade system that would offer from tens to thousands of processors and use a lower-cost cooling system than the XC30s.
This machine is not going to be called the XC30m, says Bolding, in keeping with past naming conventions (for reasons Bolding did not explain) and it will be available in the second quarter of 2013.
Blowing in one side of the aisle and out the other
One of the other innovations with the Cascade machines is a new transverse cooling system that blows air through a row of racks, and that magically has the output temperature at one end of the row the same as the intake temperature at the other end.
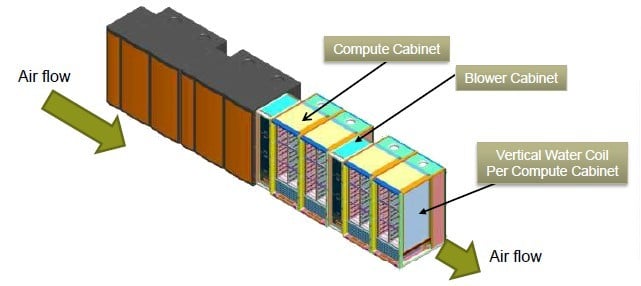
The transverse cooling of the XC30 supercomputer
With this design, there are hot-swap blowers on the left side of each cabinet and vertical water chillers inside the cabinet on the right side. The cold air from the data center enters the blowers, goes across the blades and chills them; then the vertical chillers in the cabinet cools the air back down to ambient data center temperature and passes it to the next set of blowers in the row of machines.
By doing it this way, you don't create hot or cold aisles. Bolding also says that the blowers are super quiet, and you don't need water or R134 coolant.
When El Reg asked why it took Cray so freaking long to come up with this relatively simply idea (which we didn't think of either), Bolding had a good laugh and did not say we were wrong when we suggested that engineers sometimes keep ideas in reserve for emergencies and continued employment. ®