Original URL: https://www.theregister.com/2012/10/29/oak_ridge_titan_supercomputer/
Oak Ridge lab: Behold, I Am TITAN, hear my 20 petaflop ROAR
One giant leap for a GPU, one small step for exascale
Posted in HPC, 29th October 2012 15:03 GMT
Oak Ridge National Laboratories is really eager to talk about the "Titan" supercomputer, which weighs in at more than 20 petaflops of performance and which has just been activated this month. In fact it's too eager to wait until the SC12 supercomputing trade show in November to give out all the feeds and speeds. Cray and Nvidia, which want to sell baby clones of Titan as fast as they can, are similarly impatient. And so, with Titan actually up and running, they are unveiling Titan super now rather than later.
The top techies from Cray, Nvidia, and Oak Ridge were in the Big Apple ahead of today's launch and discussed the new machine over breakfast with El Reg. And you can understand the eagerness of Oak Ridge to talk about the big, bad box, which the US Department of Energy hopes will facilitate significant breakthroughs in research in the physics, combustion, materials science, nuclear energy, and combustion.
Titan is not a brand new machine, but is rather an upgrade of the existing "Jaguar" supercomputer at Oak Ridge, which is a tricky bit of work to performance as researchers are continuing to run jobs on the system.
Jaguar came onto the scene in the fall of 2009 and was based on Cray's XT5 systems using the "SeaStar+" interconnect across its nodes. Jaguar was the top-ranked machine on the November 2009 and June 2010 editions of the Top 500 supercomputer rankings, with 2.33 petaflops of peak theoretical performance. After an upgrade earlier this year - moving to the "Gemini" XE interconnect and the sixteen-core "Interlagos" Opteron 6274 processors in half the sockets in the nodes and 960 of Nvidia's Tesla M2090 GPU coprocessors - the Jaguar system was upgraded to 298,592 x86 cores and a total 2.63 petaflops across those CPU and GPU processors.
The Jaguar and Titan machines both have 18,688 compute nodes, but with the Titan machine, each sixteen-core Opteron compute node is getting twice as much main memory (32GB per compute node) and is also being paired up with a Tesla K20 "Kepler" GPU coprocessor (which has 6GB of its own GDDR5 memory). The Titan machine has a total of 299,008 Opteron cores, and total system memory is boosted to 710TB across this system (up from 300TB in Jaguar), and the number of login and I/O nodes has also been doubled to 512 nodes.
With all of those Tesla K20 coprocessors, the total number-crunching capacity of the machine is expected to be more than 20 petaflops, says Jeffrey Nichols, associate laboratory director at Oak Ridge, which means that the K20 GPU coprocessors are delivering at least 17.4 petaflops of that raw computing performance since the Opteron side of the nodes is delivering around 2.63 petaflops.

Nichols says that Oak Ridge started working on the design of the Titan machine back in the spring 2009, and that is one of the reasons why the lab is so eager get its hands on Titan and put it through its paces. The machine is being put through its reliability and stability acceptance tests now, which is why formal performance specs for the box have not been released yet. (You can bet there will be a Linpack result for the machine to be included in the November 2012 Top 500 list, which will come out during the SC12 event.)
The computing side of the Jaguar machine burned 6.95 megawatts to deliver that 2.33 petaflops of peak performance, which came in at 1.76 petaflops on the Linpack parallel Fortran benchmark test. Just based on peak performance, that works out to 335.4 megaflops per watt. To ramp the Jaguar machine up to more than 20 petaflops just using Opteron processors and the Gemini interconnect, if you could do it, would consume an estimated 30 megawatts and take more than 800 cabinets. This is obviously not feasible, even for Oak Ridge, which buys its juice from the local Tennessee Valley Authority.

The Titan supercomputer at Oak Ridge
Nvidia has not given out precise performance specs for the K20 GPU coprocessor, except to say it will have more than 1 teraflops of double-precision oomph. So it is hard to say what the power efficiency of the Titan supercomputer would be. All Nichols would say is that the machine would deliver "well north" of 20 petaflops. What Nvidia did say in its announcement for Titan (but not during the meeting with El Reg) is that the new super is more than 10 times faster and is five times more energy efficient than Jaguar. To get to that 10X raw performance, the K20 GPU has to deliver around 1.1 teraflops of double precision performance.
With the Titan machine burning 9 megawatts of juice, according to Oak Ridge, this machine will offer a considerably improved 2,576 megaflops per watt if it reaches 23.1 petaflops of performance. Our math shows higher performance per watt than Nvidia's press release. Go figure.
The important thing as far as Cray, Nvidia, and Oak Ridge are concerned is that this performance is on par with the power efficiency of the BlueGene/Q PowerPC-based massively parallel supercomputer from IBM, which has been the most efficient super available up until now. However, until Linpack is run and we see how the architectural improvements in the K20 GPU coprocessors, such as dynamic parallelism and Hyper-Q, pan out we won't be able to see which type of machine, BlueGene or x86-Tesla hybrid, has the edge in power efficiency on Linpack or other workloads.
Up until now, GPU-accelerated machines have been able to deliver cheaper flops and very good bang for the buck, too, but a lot of the raw computing capabilities of the GPU were not used by applications and the power efficiency of ceepie-geepie hybrids was not spectacular.
The storage side of the Titan machine will be upgraded as well, says Nichols, with the current setup having 10PB of storage and about 280GB/sec of aggregate I/O bandwidth coming out of the storage into the supercomputer. The RFP for the future storage system to match Titan has just been sent out, according to Nichols, with Oak Ridge expecting to double up or triple up the storage capacity and pushing up to 1 TB/sec of aggregate bandwidth into the system.
Nichols says that the role of flash memory in the future file system, if any, has not yet been determined, but says that obviously by putting high speed flash right into compute nodes, you could dramatically speed up checkpointing operations on clusters because of the higher I/O rates flash have over disk storage. With checkpointing, you are saving a state of a node and its work at a given recovery point. You don't need to store the raw data there, which is on the parallel disk array.
The push to exascale and out to zettascale
"Titan is validation that accelerated computing is here," says Nichols, who is not as excited about hardware as he is about doing science with the hardware. The important thing is that Oak Ridge started working with Cray and Nvidia on porting applications from Jaguar's parallel x86 architecture to the hybrid CPU-GPU architecture 18 months ago. "We want to be able to do science on day one."
A number of different codes have already been ported to run on Titan, as you can see below:
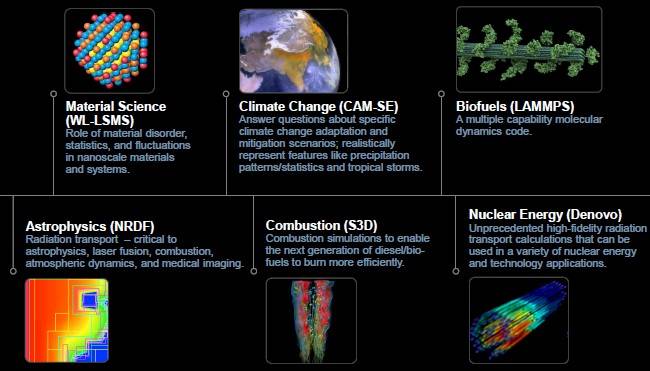
Key workloads on the Titan supercomputer
These run the gamut, and they all have one thing in common. Researchers are already planning how they might use a machine with around ten to fifteen times the performance of Titan. This future box, which is in the planning stages right now for delivery in around 2016, was known as OLCF-4 in the Oak Ridge planning documents we saw a year ago and was based on the future "Cascade" machines with the "Aries" interconnect from Cray.
That was theory, not contract, and Nichols says that Oak Ridge is talking to Cray, Intel, IBM, Appro International, and others for this future procurement. Nichols tells El Reg that something on the order of "200 to 300 petaflops was a good stretch goal" for the performance of this machine.
The problem is not adding machines and cabinets to a cluster to build a bigger badder box to push up to exascale, but that an exascale machine in 2019 or 2020 is expected by Nichols to cost somewhere around $200m to $250m using extrapolated current technology. Oak Ridge gets about $100m a year to fund its computing lab, with roughly a third for systems; a third for electricity for power, cooling, and computing; and a third for staff salaries. So an exascale machine in 2020 or so is now currently more expensive than Oak Ridge has been paying for each successive computer. But an exascale-class machine is needed to fully simulate an internal combustion engine (something that is near and dear to the US Department of Energy, which funds Oak Ridge) or to do a whole earth weather simulation at a 1km resolution, just to name two applications.
Steve Scott, who left the CTO job at Cray in August 2011 to become CTO for the Tesla line at Nvidia, acknowledges the challenges in getting to exascale, but is optimistic that we can reach that level of performance and push on. "Five years from now, we will be talking about zettascale. I am pretty bullish that we can get there," says Scott.
Everybody wants that, but there are considerably engineering challenges to get an exascale system into a 20 megawatt power envelope, which most people say is the practical upper limit for an exascale machine. It would be nice if it didn't cost so much, too.
Parallel program for inciting researchers to program in parallel
The US Department of Energy shares the supercomputers it builds at Oak Ridge and at Argonne National Laboratory. The supers have their jobs allocated to them through the Innovative and Novel Computational Impact on Theory and Experiment (Incite) program, which made its first awards to academia in 2004 to let them run their jobs.
Under the Incite rules, you can't get time on the system unless you can demonstrate that your job will scale across at least 25 per cent of the system. This stands in stark contrast to the machines funded by the National Science Foundation, which have thousands of users getting much smaller time (and often core) slices of the boxes.
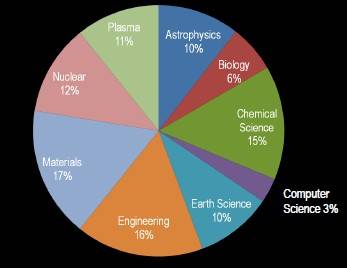
How the DOE allocates computing resources
at Oak Ridge and Argonne
In addition to Titan at Oak Ridge, the Incite program slices up time on two IBM machines: the "Mira" 10 petaflops BlueGene/Q machine and the "Intrepid" 557 teraflops BlueGene/P box.
As part of the rollout of Titan, the DOE announced that in 2013 it will allocate 4.7 billion core-hours to 61 science and engineering projects through Incite. About 1.84 billion core-hours will be allocated on Titan with 2.83 billion core-hours will be given away on the Mira and Intrepid machines. The average award on Titan is 58 million core hours, which works out to running a job across the entire machine for eight days. (Not that it is necessarily allocated that way.) The average award on Mira is 78 million core hours, according to the DOE.
Roughly speaking, according to Nichols, about half of the capacity managed by Incite goes to DOE research and half to outside academics. There are three times as many applicants to the program than awards.
And there's a lot more capacity to play with. Back in 2004, the original Incite awards granted 5 million core-hours, and there is now a three orders of magnitude increase in capacity available. To date, over 10 billion core-hours of computing have been run through Incite. You can read all about the 2013 Incite awards on these three supercomputers here. ®