Original URL: https://www.theregister.com/2012/10/25/vmware_project_serengeti_hadoop/
VMware helps Hadoop roam the Serengeti a little easier
Virtual elephants chomping on real data
Posted in Virtualization, 25th October 2012 18:15 GMT
Hadoop World VMware wants every workload to be virtualized, even high performance computing, data warehousing, and Hadoop data munching workloads. The server virtualization juggernaut will get around to HPC and data warehousing at some point, but it already has a start on Hadoop with Project Serengeti. That project got some tweaks this week.
The Serengeti effort was launched in June, and it takes the Spring Java application framework and tunes it up to corral Hadoop server nodes onto virtual machines. The upshot is a system that makes it easier for Java developers to create Hadoop applications, and that allows for Hadoop nodes to be virtualizes and run inside of virtual machine containers.
All of the elements of a Hadoop cluster, including Hadoop management, query, and data abstractions tools, can be wrapped in virty layers, and replicated and failed-over just like any other infrastructure running on a cloud. Moreover, the Serengeti code allows for an entire virtual Hadoop cluster to be installed on a single physical machine for application development and testing.
But VMware has higher aspirations for Serengeti, as Richard McDougall, application infrastructure CTO and principal engineer at VMware, explains in a blog post announcing the updates to Serengeti that came out during this week's Hadoop World 2012 extravaganza in New York.
The idea is fairly simple, even if the implementation will be somewhat complex. By virtualizing Hadoop and other workloads, you will be able to make server clusters do other kinds of work right beside Hadoop, such as analytics or parallel supercomputing. You dial up one set of VMs for Hadoop, run jobs, and dial them back, letting a risk analysis or some other kind of job then take over the iron do its work.
This is the argument that many of us were making for the adoption of ESX Server when it was a newbie product a decade ago, but the sophisticated automation and management tools that turn virtualization into a cloud were not available. (No one even called it a cloud then, but many of us tried to steer the language toward a more accurate metaphor: a utility. But, alas, the marketing people won.)
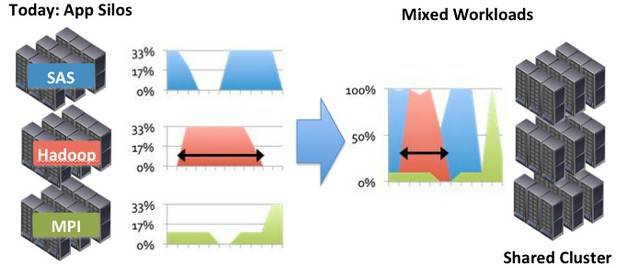
VMware Project Serengeti argues for shared clusters
Now, a decade later, ESXi is a much more scalable hypervisor and those management and automation tools are available, even if they are a bit shiny and untested by most companies.
The beauty of going virtual for parallel workloads of all kinds is that you can configure all of the pieces of a particular stack independently from each other and update them accordingly. And in a virtual environment, if you take snapshots you can easily rollback to a prior state, or only update a current state of a machine and not roll it into production until after you have tested it.
You can also finely control how much processor, memory, and I/O resources each virtual instances gets supporting a portion of the Hadoop cluster, and you can isolate portions of the Hadoop cluster so it can be used to test new algorithms or new add-on functionality without messing up the remaining parts of the Hadoop cluster that are in production.
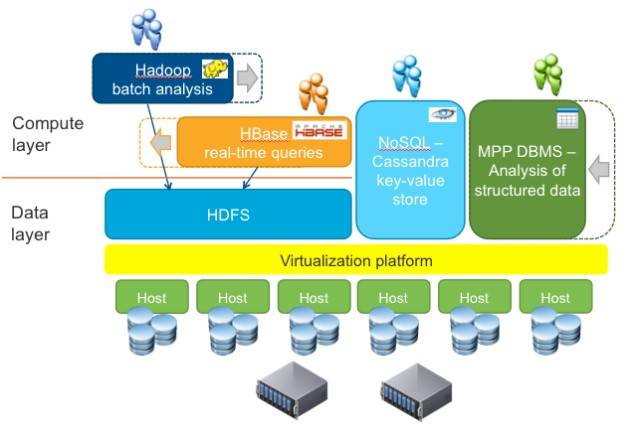
Block diagram of Project Serengeti
As MacDougall correctly points out, Serengeti is not the only game in town for running multiple jobs on Hadoop clusters. The YARN scheduler for Hadoop, which is still not in production in most Hadoop distributions, allows for calculation methods other than MapReduce to be embedded inside of Hadoop and spread around the cluster nodes. The Apache Mesos cluster manager is another alternative, allowing for Hadoop and supercomputing jobs using the Message Passing Interface (MPI) protocol to parcel out work to run on the same cluster.
But the Serengeti approach has the virtues of being based on ESXi and Spring, and of keeping separate things separate rather than to trying to make Hadoop into a more general purpose platform.
Moreover, the virtual machine approach allows for the compute (Task Tracker) and storage nodes (Data Nodes) in a Hadoop cluster to be put into separate VM containers, and now they can be scaled independently. (Presumably this still requires the Task Tracker and Data Node code to be resident on the same physical machine.)
The other neat thing you can do would be to create multiple virtual Hadoop clusters with their own Job Trackers and Task Trackers and presumably a shared Name Node, that can access different virtualized Data Nodes. In effect, you can interleave two entirely distinct Hadoop clusters, using the same data, atop the same physical hardware. Now you don't move data between two Hadoop clusters to do two jobs for two different departments; you just keep adding virtual Hadoop clusters atop an ever-embiggening single Hadoop Distributed File System, and every department just thinks it has its own Hadoop cluster.
You also pay a hell of a virtualization performance penalty with the VMware approach, El Reg would expect, but no one has provided any statistics on that and it may be more than made up for by the flexibility this way of doing things offers. VMware has said in the past that in some circumstances, performance on a virtualized cluster is better than on a physical one because you can get the utilization up higher and pack more work onto it.
The new features in Serengeti 0.7.0 aim to move VMware in the directions outlined above. You can read the latest Project Serengeti release notes here and download the Serengeti virtual appliance for ESXi here.
The latest release supports the new ESXi 5.1 hypervisor and has a new Virtual Hadoop Manager that snaps into vCenter Server to allow it to power up and power down nodes on a Hadoop cluster. The new release also adds support for a number of Hadoop distributions, including Cloudera's CDH3 Update 3, Greenplum HD 1.2.0, and Hortonworks HDP 1.0.7. The latest open source Apache Hadoop 1.0.1 can also be control-freaked by Serengeti 0.7.0. ®