Original URL: https://www.theregister.com/2012/10/09/hp_appsystem_for_sap_hana/
HP doubles up SAP hard-hearted HANA appliances
Scaling out and adding failover clustering
Posted in Systems, 9th October 2012 01:45 GMT
Everybody – especially server makers without much of a software business – wants to peddle SAP HANA in-memory databases, and HP is no exception: they're taking its AppSystem for SAP up another notch with a disaster-tolerant configuration for supporting HANA.
In a blog posting, Mary Kwan, global business manager for SAP Solutions in the company's Business Critical Systems division, announced that HP's techies had worked with HP to cook up a clustered setup that mixes various servers based on Intel's Xeon E7 processors to run SAP's HANA, which is short for High-Performance Analytic Appliance. (I know, that's actually HPAA. Maybe that works better in High German).
If you can get by with a single-node configuration for HANA processing, then HP suggests that you use a four-socket ProLiant DL580 G7 server based on the E7-4800 or the eight-socket DL980 based on the E7-4800s.
You might be wondering why HP hasn't put out Gen8 versions of these machines, and that's because Intel is not going to do a "Sandy Bridge-EX" Xeon E7-7600 processor family and is going to skip right to the "Ivy Bridge-EX" processors sometime next year.
IBM and Dell have HANA appliances, and their various SKUs are all based on the Xeon E7 processors. This is a bit surprising, given the very good specs that the E5-4600 quad-socket boxes from HP, Dell, and IBM deliver, but the E7's still have the edge on resiliency, core count, and error correction – and when you are dealing with an in-memory database, this really counts.
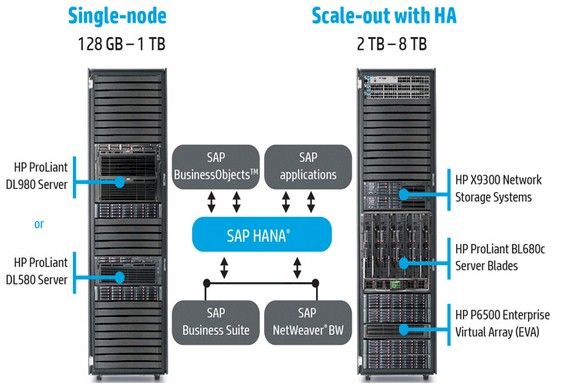
HP AppSystems for SAP HANA in-memory databases
The single-node setups come with between 128GB and 1TB of main memory and a suitable amount of disk capacity to drive the HANA database and feed queries into SAP business and analytics software.
If you need to scale out further, it's going to take more iron, and HP is pushing its BladeSystem blade servers and more sophisticated storage arrays to feed data into a multimode setup that can also be split in two and replicated across geographic distances for high availability using clustering and replication in the disk arrays.
HP is not terribly specific about the configurations, but the HANA server nodes are based on four-socket BL680c G7 servers, which sport the E7-4800 processors. Each blade scales to up to 2TB of memory, and the system scales from one to four nodes for a total of 8TB in the HANA setup.
If you want to keep all of your HANA processing local, you can store the data on the HP P6500 Enterprise Virtual Array (EVA) disk arrays. Every node in the scale-out configuration uses the X9300 IBRIX NAS array to "see all of the storage in the cluster," according to HP, which says further that the X9300 is a cluster that virtualizes the P6500 storage and presents it to the HANA database cluster via NFS.
If you want to replicate data across HANA nodes, HP says to crank up the continuous access (CA) feature of the P6500s to replicate to a mirror that can be separated by 30 miles (50 kilometers) using synchronous replication between the arrays. HP is cooking up a variant of the HANA cluster that uses asynchronous replication, and that will be able to separate halves of the setup that can be as much as 300 miles (or 500 kilometers) distant from each other.
No word on what any of this stuff costs. ®