Original URL: https://www.theregister.com/2012/09/27/quantcast_hadoop_qfs_file_system/
Quantcast gives the boot to Hadoop's HDFS
Boots up – and opens up – homegrown QFS alternative
Posted in Storage, 27th September 2012 14:12 GMT
There's no shortage of complaining about the limitations of the Hadoop Distributed File System that underpins the MapReduce algorithms of the Hadoop Big Data muncher, which is why quite a few companies have come up with alternatives. And now there is a new HDFS alternative from internet click counter Quantcast called – you guessed it – the Quantcast File System.
Quantcast was founded in 2006 in San Francisco, and is hired to do sampling of data by either web content publishers or the advertising agencies that are paying the bills. In either case, Quantcast founder and CEO Konrad Feldman tells El Reg that over 100 million "web destinations" are being tracked by Quantcast's giant Hadoop clusters. And as you might imagine, this generates quite a bit of data, which the company then dices and slices to provide demographics for websites and advertisers. (Who, once again, pay most of the bills around here on the Intertubes, whether we like it or not.) To get Quantcast going, a whole team of backers – including Revolution Ventures, Founders Fund, Polaris Venture Partners, Cisco Systems, and Glynn Capital Management – have paid most of the start-up's bills through three rounds of venture funding totaling $53.2m.
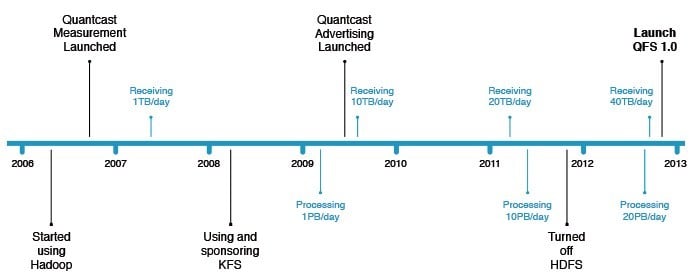
Quantcast was an early practitioner of Hadoopery, and it cranked up its first clusters in 2006 ahead of the launch of its Quantcast Measurement system for websites. Just six months later, it was receiving 1TB of data a day from the tracking tags that it has spread around the internet through content suppliers.
About a year later the company started running up against the limits of HDFS, following in the footsteps of Yahoo!, Facebook, and other big properties on the web before it, says Jim Kelly, vice president of research and development at Quantcast. In early 2008, the company started using the Kosmos File System (KFS) developed by Sriram Rao and eventually hired him to continue development of the KFS alternative to HDFS. (Rao now works as a research scientist at Microsoft.) KFS was used in some secondary systems in 2008 to boost performance, but eventually Quantcast decided to do a big development effort and significantly revamp KFS so it would scale a lot further and deliver more performance.
Timeline of Hadoop usage at Quantcast (click to enlarge)
The company really had no choice. In early 2009, when it launched Quantcast Advertising, embedding its tags in ads as well as content, it was receiving 10TB of new data per day and processing over 1PB of data a day, dicing and slicing, mapping and reducing. And as the business grew, so did the data load. By early 2011, Quantcast was receiving 20TB a day and processing 10PB per day. Late last year, the QFS kicker to KFS was more or less done and ready for primetime, and the company spent weeks moving its production Hadoop clusters off HDFS and onto QFS. And as far as Feldman is concerned, it is a good thing the company did, because its data load has doubled again to 40TB inbound each day and its Hadoop clusters have to chew through 20PB a day for clients who want to know what you are doing out there on the intertubes.
Instead of keeping QFS all to itself, which it could have done because it is providing a service, not marketing it as a product, Quantcast is opening up QFS with its 1.0 production release and distributing it at GitHub under an Apache V2.0 license (which is the same license that KFS was under). "As we have grown our business, we have used a significant amount of open source software, and our developers want to give something back," says Kelly.
And neither Feldman nor Kelly has any intention of providing commercial support for Quantcast, but they are cool with someone else doing so. What they want is a community of developers who are hitting the ceiling with HDFS and who will help solve the petascale problems that it has.
Like HDFS, QFS is a distributed file system, but instead of implementing it in the Java language as is done with HDFS, Quantcast compiled it down much closer to the iron in a good old C++ compiler, which boosts its performance significantly. The file system is 100 per cent compatible with Hadoop, which doesn't know or care that it isn't using HDFS. The big difference is that the architecture and error recovery mechanisms for QFS are perhaps better suited to modern clusters than HDFS.
"When Hadoop was built, networks and disks were vying for the slowest things in the data center," says Kelly. "But now, networks are 10 times faster and disks are as slow as ever. So it makes sense to do a different optimization for a file system for Hadoop."
With Hadoop, because networks and disks were slow, the MapReduce algorithm dispatches work to a node where the NameNode in the Hadoop cluster knows a particular set of data exists. For throughput and data availability reasons, Hadoop keeps three copies of all data sets and spreads them out across a cluster. The assumption is that networks are slow, so chunk up the data and the chewing so you don't have to pass data over the network to processors.
With QFS, rather than making three copies of the data sets and spreading them around the cluster, the data is encoded using the Reed-Solomon algorithm, which is used to encode CDs and DVDs, among other things. This algorithm breaks data into 64KB stripes and then it generates three different parity stripes for every six data stripes. Each one of the nine resulting stripes is put on a different physical drive by the file system, and ideally every stripe is in a different rack (not disk or server node, but rack) in the cluster. I know that sounds insane, because you are going from local access of data over a PCI bus to a compute job – where by definition all of the data has to come in across the network. But every write is parallelized across nine disks and every read is parallelized across six drives, and when you move from Gigabit Ethernet up to 10GE or 40GE links or QDR or FDR InfiniBand links, the net effect is that QFS is faster than HDFS.
How much you ask? Well, take a gander:
Relative performance of HDFS and QFS
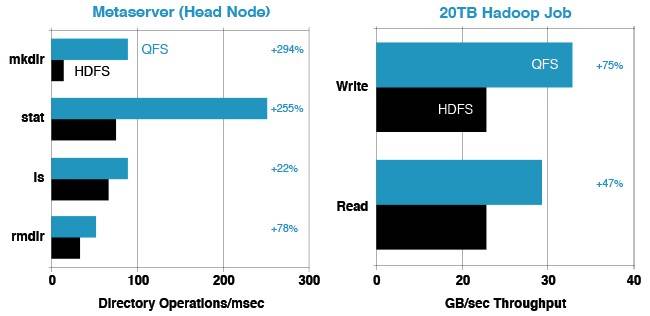
The benchmark tests shown above were run on a production system with real Quantcast workloads on a cluster with over 1,000 nodes and a total of 6,500 disk drives. The metaserver (akin to the NameNode in a Hadoop HDFS setup) can build, inspect, or deconstruct a balanced tree with up to 75.7 million directories. Listing is not much faster, but both the stat command, which looks up the file size and timestamp on a chunk of data, and the making directories are clearly running a lot faster in QFS than in HDFS. (This test was done on the Cloudera CH4 distro of Hadoop.)
And on a 20TB Hadoop job, done on the open source Apache Hadoop 1.0, QFS can read data about 47 per cent faster and write it about 75 per cent faster. This makes sense when you consider that for 20TB of data, you have to write it three times in HDFS, but only by a factor of 1.5 through the Reed-Solomon algorithm. And when you do a 20TB read operation, you have to do the read on the whole data set, but the parallelism in having the read parallelized across six drives more than makes up for the network latencies.
Obviously, QFS is not for everybody. If you have a small Hadoop cluster and you are taking in dozens of gigabytes of data each day and chewing on dozens of terabytes each day on dozens of server nodes, then the open source Apache Hadoop or the commercial-grade distros from Cloudera, HortonWorks, MapR, IBM, or Greenplum/EMC will probably do you just fine.
Other potential QFS users are those who won't mind spending on networking hardware in exchange for not having to buy so many disk drives. Storage is a huge component of the cost of a Hadoop cluster, and being able to cut the drive count in half is a big deal on big clusters. It could even be as big a deal as getting better performance, in fact. ®