Original URL: https://www.theregister.com/2012/08/31/ibm_power7_plus_processors/
IBM to double-stuff sockets with power-packed Power7+
Big boost in clock speed, smart accelerators
Posted in Systems, 31st August 2012 23:03 GMT
Hot Chips Power Systems users, start your engines. Or, more precisely, start your budgeting cycle so you can get ready for Big Blue's impending Power7+ RISC processors to run your AIX, Linux on Power, and IBM i (formerly known as OS/400) workloads.
At the Hot Chips conference this week in Silicon Gulch, Scott Taylor – one of the chip architects who worked on both the Power7 and Power7+ design and currently the lead engineer on the juice-sipping features of the Power7+ circuits – divulged many of the details of the next-generation 64-bit Power chips destined for Power Systems machines before the end of this year.
El Reg has been uncovering many of the details of the Power7+ chip over the past several months, and Taylor confirmed many of the specs that we had already caught wind of. But he also revealed a whole bunch of other stuff, showing that IBM is still deadly serious about the high-end processor business and is doing everything it can to boost the performance of workloads running on its homegrown RISC chips and operating systems.
As we already revealed, the Power7+ chip is an eight-core processor, just like its predecessor, the Power7 chip that debuted in February 2010 and was rolled out into low-end and high-end systems as the spring and summer rolled on.
IBM is using a 32-nanometer copper/silicon-on insulator process with high-k metal gates to etch the Power7+ chips in its East Fishkill, New York foundry. The chip has 13 different metal levels (IBM has 15 in the z12 chip) and crams 2.1 billion transistors onto the die. The 32nm process allows for the logic transistors to have three different threshold voltages, allowing for IBM to optimize each part of the Power7+ chip for power and performance.
As was the case with the Power7 chips – and the z11 and z12 mainframe processors that borrow many of the same technologies – the Power7+ does not use static RAM (SRAM) for its L3 cache shared across the cores, but rather embedded DRAM memory, which is somewhat slower but a lot less dense in terms of the number of transistors needed to make a bit. The slowness of the eDRAM is more than offset by the reduction in chip size (which reduces power draw and improves chip yields) and the very large amount of memory that is possible to put on a die with eDRAM – which boosts performance more than you might think.
That was certainly the case with the jump from the Power6 and Power6+ processors to the Power7 chips back in 2010. The clock speeds of the chips were actually lower, but the huge gobs of L3 cache memory, changes in the pipeline, and other factors allowed IBM to use the shrink from 65 nanometers to 45 nanometers to double the raw performance per core while moving from two to eight cores on a die.
By the way, we have always contended that IBM wanted Power6+ to be a quad-core chip, or at least to double-stuff sockets with two shrunken Power6+ chips to boost throughput per socket in 2008 or 2009, but IBM never admitted to this.
A big chunk of the shrink from 45nm to 32nm with the Power7+ chip was used to boost the on-die L3 eDRAM cache, specifically by a factor of 2.5 times to 80MB. This is four times the amount of L3 cache that Intel can bring to bear with its eight-core Xeon E5 chips, which top out at a total of 20MB, or 2.5MB per core.
IBM is delivering 10MB of L3 cache per core for the Power7+ chips, and is even offering 48MB across six mainframe cores in the just-announced System zEnterprise EC12 mainframes, which came out during Hot Chips unexpectedly and about six weeks early. Those mainframes use six-core z12 engines and have 48MB of L3 cache, or 8MB per core when all of them are activated.
Big Blue clearly believes in big L3 caches – and in fact with the mainframes there is an off-chip L4 cache hooked into the SMP hub that provides 384MB of additional cache that feeds into each L3 cache on each z12 processor.

Die shot of the Power7+ chip from IBM
Taylor said during his presentation that if IBM had stuck with SRAM-based L3 caches for the Power7+ design, it would have taken 5.4 billion transistors to etch the Power7+ chip – which would obviously have made it much larger than its 567 square millimeters.
New with the Power7+ is power gating for the cores, the L2 caches associated with cores, and the L3 cache. The caches are power-gated by regions, not in an all-or-none fashion, which is how it should be and which allows the processor to scale-up cores and cache segments as necessary to support workloads running on a server and to scale them back down again when the server is less busy.
While some of the shrink to 32nm was burned up running L3 caches around the outside of the chip and stuffing it into any empty space IBM could find, some of that shrink was also used to make the circuits on the core smaller and thus able to run at a higher clock speed in the same thermal envelope.
IBM execs had said to expect a clock speed boost of around 10 to 20 per cent a few weeks ago in the Wall Street Journal, but Taylor said the chip could actually run 25 per cent faster than the Power7, even with all the L3 cache added. The top-bin Power7 chip with all eight-cores fired up is in the big iron Power 795, which supports up to 32 processor sockets and clocks at 4GHz. A 25 per cent bump pushes that up to 5GHz. That extra clocking is also enabled by better power management.
Taylor added that single-precision floating point performance on the Power7+ chips will be double that of the Power7 chip. He did not elaborate, but clearly this will be done with a mix of clock-speed enhancements and changes to the floating point units in the Power7+ chips.
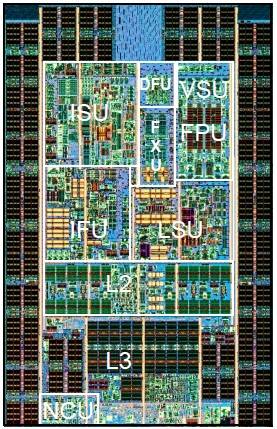
IBM Power7+ core shot
The Power7+ core is largely the same as the Power7 chip, but there are enough enhancements to make it worthwhile to muck about among the transistors. The chip is wrapped in the eDRAM L3 cache memory blocks, and there is a new element called an NCU that I'm still hunting down to see what it does. The Power7+ core has 256KB of L2 cache memory, two load store units (LSU), a condition register unit (CRU), a branch register unit (BRU), and instruction fetch unit (IFU).
Each Power7 and Power7+ core has 32KB of L1 instruction cache and 32KB of L1 data cache, so no changes there. The instruction scheduling unit (ISU), which is where the out-of-order execution in the chip gets handled, is on the top-right portion of the core inside the ring of L3 cache, and up near it are four double-precision vector-math units. In the middle of the top of the core are two fixed-point units (FXUs), and above them is the decimal fixed unit (DFU) that does two-digit money math.
There are twelve execution units per core, and each core has four virtual execution threads enabled by simultaneous multithreading. IBM offered four-way SMT with the Power7 chips, too, and as with those chips the SMT can be dialed up and down on command or dynamically as workload conditions dictate.
IBM still supports a maximum of 32 processor sockets in its largest system, but with the Power7 chips as with the Power5+ chips from 2005 and the Power6+ chips from 2009, Big Blue creating special variants of the Power7+ chips that have their clocks turned way down so two whole processors can be crammed into a single Power server socket.
The Power7 and Power7+ processors will plug into the same physical socket, but in the past IBM has hinted that customers will have to upgrade their system boards to get Power7+ support. This may have to do with features necessary to double-stuff the sockets, the move to PCI-Express 3.0 peripherals, or both.
By the way, IBM would not confirm if the forthcoming Power7+ servers would support PCI-Express 3.0 peripheral slots, but with Intel, Oracle, and Fujitsu doing so with their latest or impending chips, Big Blue had better move to PCI-Express 3.0 as well
The on-chip local SMP links that hook the eight cores together share space in the center top of the Power7+ chip with the various accelerators IBM has been hinting were on their way.
That local SMP bus has 360GB/sec of SMP bandwidth. The remote SMP links, which allow up to 32 sockets to be lashed together into a coherent, single system image, are at the bottom center of the chip, and this is also where remote I/O links are located. There are two DDR3 memory controllers on-chip.
The eight-core Power7+ can handle 20,000 concurrent, coherent operations ricocheting around inside its transistors, and is binary compatible with Power6, Power6+, and Power7 processors – which may seem to hint that Power4, Power4+, Power5, and Power5+ chips are not binary compatible with it, but as far as I know, binary compatibility goes all the way back to Power4 in 2001, regardless of what Taylor's presentation implies.
Taylor says that a single-socket Power7+ implementation is aimed at customers who want the best single-thread performance, while the double-stuffed Power7+ sockets are aimed at workloads that need more cache per clock cycle and more threads per system.
Anyway, with a double-stuffed machine, you can in theory get 512 cores into a single system image, but it is not clear if AIX and Linux will be able to see more than 1,024 threads as they currently do; the IBM i operating system tops out at 128 threads in a single image at this point, with a special patch to boost it to 256 threads, and is woefully overdue for the same loving that AIX and Linux have gotten since 2010 to at least see 1,024 threads.
Giving workloads and algorithms their own special sauce
IBM's roadmaps have said that the company would use some of the Power7+ transistor budget to bolster the throughput of the chip on very precise algorithms, and Taylor showed off a bunch of them at Hot Chips.
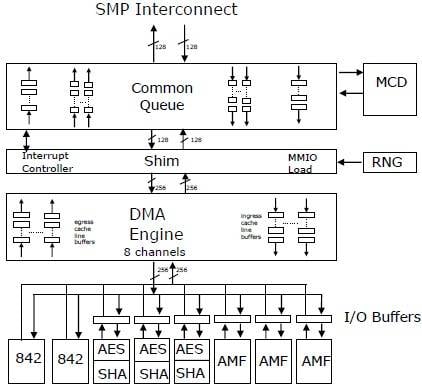
How various accelerators hook into the Power7+ chip
Each chip has three Asymmetric Math Function (AMF) accelerators, which implement math functions used in RSA and ECC cryptography. The AMF units do RSA encryption at 512, 1024, 2040, and 4096 bits, and there are ten bit levels supported for elliptic curve cryptography encryption and decryption.
Each chip also has three accelerators to handle Advanced Encryption Standard (AES) encryption with key lengths of 128, 192, and 256 bits, and to do Secure Hash Algorithm processing with SHA-1, SHA-256, SHA-512, and MD5 variants supported.
The chip also has a "true hardware entropy generator" – or random number generator – that Taylor says cannot be algorithmically reverse-engineered. This, of course, will be particularly useful for any simulation or security code that requires random numbers.
Each chip also has a special circuit, called an MCD (not sure what that's short for – Mighty Confusing Doohickey, perhaps?) that predicts if memory accesses will be on-node or off-node when they are done on a multiple socket machine.
Finally, the Power7+ chip has two special accelerators called 842 units that implement a proprietary compression algorithm that is used in the Active Memory Expansion main-memory compression that debuted with Power7 systems running AIX and that could often double the effective main memory of an AIX box.
Now that this 842 accelerator, which can do 8 bytes of compression or decompression per bus cycle, is on the iron, maybe IBM can transparently offer support for IBM i and Linux as well as AIX – Taylor told no secrets, however. The 842 refers to the 8-byte, 4-byte, and 2-byte parsings that the algorithm supports to do memory compression.
One interesting thing in the way IBM has implemented the accelerators is that the AES/SHA and AMF units are fronted by their own I/O buffers, so that if a result that comes out of an accelerator is an input for another accelerator, it can be passed over. For example, you might encrypt data and then compress it, or uncompress data and then unencrypt it – this way, you don't have to bother the CPU scheduler until the data is ready to be shipped to the core for processing. Smart.
Fight the power
With the Power7 chips running pretty hot – at least compared to x86 chips and thanks to those high clock speeds mostly – IBM has to do everything it can to save juice in its Power Systems.
With the Power7+ chips, IBM has created new power states that make it run more efficiently than its predecessors while also delivering that higher performance.
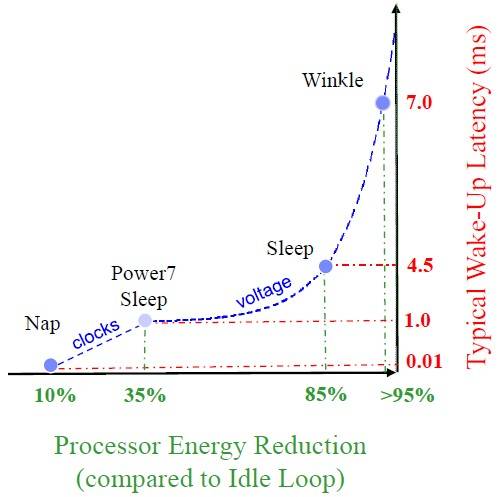
The Power7 chip had a nap mode, which allowed IBM to stop the clocks on one processor core's execution engines and leave all of the L2 and L3 cache segments associated with that core running. This nap mode was optimized so a core could be awakened quickly, with its cache states preserved and remaining coherent with the other caches in the system. This cut the core's power draw by around 10 per cent with around a 10 microsecond latency to wake it back up, according to Taylor. The Power7 chip also had a sleep mode, which cut power draw by about 35 per cent for a core module with a one millisecond wake-up time.
Idle states in the Power7+ processor
With Power7+ chips, IBM has a new-and-improved sleep mode and a new deep-sleep mode called "winkle" – as in Rip van Winkle, the fictional character from the Catskills region of New York where IBM is headquartered who missed the American Revolution because he slept for 20 years. Slacker.
The new sleep mode with the Power7+ chips purges the cores and their L2 caches, but leaves the shared L3 cache running in its current state. This mode cuts the power draw from the core module by 85 per cent, but takes 4.5 milliseconds to wake up. The winkle mode purges the L3 cache segment most closely associated with the chiplet, and powers off the whole core module, including core, L2 cache, and L3 cache segment. This reduces the power draw by 95 per cent, but it takes 7 milliseconds to wake the Power7+ core module back up.
Milliseconds seems like a lot of time to wake up from a low power state, so maybe the Power7+ is like the rest of us and is a little groggy after days in Hot Chips meetings.
Taylor was hassled about the long time de-winkling takes, but said this was IBM's first stab at it and that he believes the power-saving modes will be improved. ®