Original URL: https://www.theregister.com/2012/06/12/hortonworks_data_platform_one/
Yahoo! spinout rolls up first Hadoop stack
Hortonworks hears a $
Posted in SaaS, 12th June 2012 17:12 GMT
Hadoop Summit 2012 Hortonworks, the company created a year ago from the spinout of the Yahoo! engineering team behind the open source MapReduce method of data munching known as Hadoop, is leading its first release to market by the nose.
The Hortonworks Data Platform, as the company's distribution is known, is completely open source and is based on the Apache Hadoop v1.0 stack, which debuted back in January from the core Hadoop 0.020.205.0 implementation that came out last October.
Hortonworks has been contributing to the core Hadoop 0.23 release and the follow-on Apache Hadoop v2.0 stack, the latter of which is in alpha code now. John Kreisa, vice president of marketing at Hortonworks tells El Reg that rather than get out there on the bleeding edge of Apache Hadoop and related projects and doing proprietary extensions for management or file systems, as rivals Cloudera and MapR Technologies do, Hortonworks is sticking to its Apache guns and creating a 100 per cent open source Hadoop distro and supporting that.
"There are no proprietary bits in the Hortonworks Data Platform, no lock in, and we doing this because we believe that it will greatly facilitate Hadoop adoption," explains Kreisa.
Like other Hadoop distributions, the HDP 1.0 distribution includes the Hadoop Distributed File System (HDFS) that spreads data in triplicates around a cluster and the core MapReduce algorithm, which dispatches data munching jobs to those copies of data to sift for useful bits in unstructured data and to make connections between bits of data.
The two key elements of a Hadoop stack are the NameNode, which is akin to the file allocation table in a physical disk drive in that it keeps track of where all of the data chunks are distributed around the Hadoop cluster, and the JobTracker, which is what submits MapReduce jobs to particular chunks of data residing on particular nodes within the Hadoop cluster. Losing scheduled jobs is a bad thing, and Hadoop shops are suitably paranoid about that, but losing the NameNode is a very big deal in that should this happen, you essentially crash HDFS because it loses track of where its data is.
Everyone in the Hadoop community has been focused on how to eliminate this single point of failure in the NameNode, which incidentally is also the performance bottleneck in Hadoop clusters, keeping their scalability topped out at around 4,000 nodes using the open source distribution of Apache Hadoop.
Both Cloudera and MapR have their own ways of dealing with providing high availability and scalability for the NameNode. Cloudera simply jumped ahead and grabbed the alpha Apache Hadoop 2.0 distribution and hardened it to create its CDH4 distribution, announced last week.
MapR's M5 Hadoop distribution shards the NameNode data and spreads it across the main memory in multiple nodes in the cluster as well as backing up the HDFS configuration data to disk drives for an extra measure of protection. Those using open source Apache Hadoop tend to put the NameNode code on a beefy server with RAID 5 disks and redundant networks and power supplies and hope for the best.
Hortonworks, while being a staunch supporter of open source software, is also practical about how skittish enterprises are about getting out on the bleeding edge (such as depending on the new NameNode HA features in the Apache Hadoop 1.0 stack). So it has partnered up with VMware to create versions of the NameNode and JobTracker server instances that run atop the ESXi hypervisor and use the failover and replication features of the vSphere stack and its vCenter management console to allow for these two key components of Hadoop to be protected. And, if you want to, other key components of the Hadoop stack can be virtualized and replicated atop vSphere.
Kreisa says that virtual NameNodes and HA using VMware is meant to be complimentary to the work that is being done in Apache Hadoop 2.0 to bring native HA to the NameNode and is just what Hortonworks thinks is the best and most comfortable way for enterprises to ensure better uptime for their NameNode and JobTracker nodes using proven software.
Hortonworks and VMware have run the implementation through a series of benchmarks to show that the virtual NameNode and virtual JobTracker provide the same overall cluster throughput as on clusters where the two key aspects of the system are running on bare metal. They did not say that it would take slightly more robust iron to do this, but the odds favor it. Moreover, considering that a large Hadoop cluster costs millions of dollars and that companies were already buying beefier servers for NameNodes anyway, the impact on the overall cost of a Hadoop cluster will be minimal. Obviously, the HDP 1.0 stack from Hortonworks does not include any VMware software licenses, so you will have to shell out extra dough for these.
The way the HA features are implemented, the NameNode failover and failback are completely automated, and the MapReduce module can detect and respond to an HDFS NameNode or JobTracker failover without crashing.
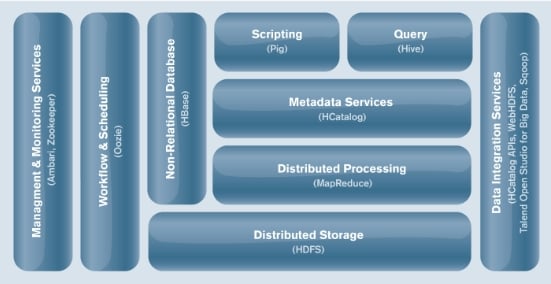
Block diagram of the Hortonworks Data Platform (click to enlarge)
The HDP 1.0 stack includes the core MapReduce distributed processing layer, the HDFS data store, and the collection of utilities for them known as Hadoop Common. The HDP 1.0 stack also includes a number of other open source add-ons, such as the Pig high-level data flow language and execution framework for MapReduce jobs and the Hive data warehousing and ad hoc querying layer for HDFS.
The stack also has the HCatalog, a metadata service that is a table and storage management service that allows MapReduce, Pig, Hive, and Streaming (a kind of uber-scripter for MapReduce jobs) to share data across those modules even though it is stored in different formats. The non-relational HBase database is also part of the core HDP 1.0 stack. All of these features are Apache projects, with either full project or incubator status.
Hadoop doesn't just sit there in the data center, chunking and chewing away on data on its own. It has to integrate with other applications and tools in the data center.
So Hortonworks has a set of data integration services that are based on the HCatalog APIs and the open source version of Talend's Open Studio for Big Data and the Sqoop, the latter being an Apache tool for moving data in bulk from Hadoop to relational databases and other structured data stores and the former being a data extraction tool that snaps into Eclipse integrated development environments.
The Talend Open Studio actually writes the metadata into HCatalog as information is moved in and out of HDFS, according to Kreisa. The integration tools for HDP 1.0 also includes WebHDFS, an add-on that gives REST APIs to the Hadoop file system.
"The ecosystem can now much more natively integrate with Hadoop," says Kreisa, "and that will just open up the platform."
On the other side of the stack, where admins have to train the Hadoop elephant to behave itself, Hortonworks has rolled up the Oozie workflow and scheduler to keep MapReduce jobs in line, the Zookeeper for keeping track of configuration and naming conventions used in the cluster, and Ambari, an installation, configuration, and management tool for the entire Apache Hadoop stack.
While Cloudera and MapR are charging $4,000 per node for their enterprise-class Hadoop distributions (including their proprietary extensions and tech support), Hortonworks doesn't have any proprietary extensions and is living off of the support contracts for the HDP 1.0 stack.
Hortonworks is offering three different support contracts (PDF), ranging from a three-month starter pack to a basic enablement contract that runs a year with some phone and Web support to standard contract with only Web support during normal business hours to an enterprise contract with the everything all in, 24 hours a day.
One other interesting twist: Hortonworks has 25 engineers who worked on Hadoop at Yahoo! and it is going for the volume with its support contracts, charging per cluster instead of per node.
Hortonworks is not providing its full list price, but for a starter ten-node cluster, you can get a standard support contract for $12,000 per year. That's significantly cheaper than what Cloudera and MapR are charging, but arguably, those two distributions are older, more established, and packed with more stuff, too. For now. ®