Original URL: https://www.theregister.com/2012/06/04/ibm_platform_computing_intelligent_cluster/
IBM rejigs Platform control freakery for supers
Hadoop MapReduce clone, new HPC stacks ship this month
Posted in HPC, 4th June 2012 22:14 GMT
Big Blue wants everything to be about Smarter Planet, but its acquisition of grid computing pioneer Platform Computing back in October 2011 was about giving IBM a place in the cloudy, gridded, and automated cluster management space and some necessary tools to maintain some sort of control – both literally and financially – in the modern data center.
It has been eight months since IBM did the Platform Computing deal for an undisclosed sum, and it was done in the wake of some interesting product development at the smaller Canadian software company. IBM is itself a very large Canadian software company, with its database and development tool labs located in Toronto.
As soon as IBM bought Platform Computing, not much was heard from it, and that is because it has taken IBM time to figure out how to best package up the smaller firm's various grid management, cloud fabric, and workload scheduling programs. Platform Computing is now a unit of IBM's Systems and Technology Group, which makes and sells chips, servers, storage, and networking; the Platform tools sit next to operating systems and high availability clustering tools that are sold on IBM systems.
You might be wondering what took so long. When IBM bought Platform Computing, explains Jay Muelhoefer, global marketing leader for the Platform unit, the control freak peddler had over 800 SKUs in its product catalog, aimed at specific use cases, industries, and partnerships. While this gave Platform Computing lots of different things to pitch to customers, this was not the best way to push pump revenues out of a direct sales force or a large reseller channel, as IBM has.
It has taken some time to streamline the products and retool the sales force to go after big deals and assist IBM's channel in chasing many smaller deals. With that work done, and IBM tucking Platform underneath Systems and Technology Group (instead of inside of Software Group as expected), IBM is now re-launching the flagship Load Sharing Facility (LSF) grid workload scheduler and Symphony Java messaging grid software, and is previewing updates that are due shortly for its Platform HPC and Platform Cluster Manager tools.
In case you don't know, Platform Computing was founded in 1992 and its workload scheduler is derived from the work done by Songnian Zhou in his PhD thesis at the University of California at Berkeley in 1987, as well as with the independent work on load sharing in distributed systems from Platform co-founder Jingwen Wang.
The company shipped LSF 1.0 in 1992, and it was quickly adopted to scheduler jobs on big clusters at Nortel, Pratt & Whitney, and the Los Alamos National Laboratory. Two years later, chip makers Advanced Micro Devices and Texas Instruments added LSF to their electronic design clusters.
HP partnered with Platform Computing in 1995, Silicon Graphics in 1998, and IBM and Compaq in 2001. Dell and NEC jumped on board in 2002, Microsoft and Oracle a year later, Red Hat partnered with the company in 2007, and Fujitsu got around to it in June of last year.
Everybody used to help peddle platform tools, and for their own revenue streams. Now, IBM wants that business for itself and for its channel partners and wants Platform's software to give it differentiation in an IT world that will be dominated in many ways by pools of distributed computing that will need some orchestration.
LSF is basically a version of Tetris that a cluster plays on itself, matching distributed number-crunching work with available resource. The Platform Symphony Java messaging grid is similarly designed to allow distributed Java workloads to be spread over a grid of servers and executed in parallel and very quickly, which is important for the financial services customers who use Symphony, by scheduling the appropriate work to be move to an available spot on the cluster.
As part of the re-organization of Platform products, IBM is creating developer, express, standard, and advanced editions of the various Platform grid and management tools, which will have increasing numbers of features and higher prices as you move up the editions. This is consistent with how IBM sells its operating systems, databases, middleware, and other systems software.
With LSF V8.3, IBM is creating two editions of the classic workload scheduling tool. The Standard Edition is what Platform has been selling all along, which is designed for throughput workloads (something on the order of 6,000 nodes, 60,000 or so cores, and 60,000 or so concurrent jobs in the queue) or for parallel HPC workloads (maybe 10,000 nodes, 100,000 cores, and 10,000 concurrent jobs in the queue).
This is overkill for some of the smaller shops that are setting up clusters, particularly in life sciences and other medical-related fields where researchers are not Linux and clustering experts and have no desire to be. To reach these customers, and give the IBM channel something to push to the volume customer, IBM has created LSF Express Edition, which has a less sophisticated workload manager and which is targeted at 100 nodes or less.
The way IBM is carving up the LSF stack is as follows. You get the Standard or Express Editions, and then you add other modules to them. The new LSF Standard Edition replaces the prior LSF, LSF Client, SLF MultiCluster, and Make modules that Platform peddled when it was independent. IBM doesn't say so, but the Express Edition is probably based on the old LSF Workgroup version.
The add-on modules for LSF include Process Manager (workflow automation), License Scheduler (software license management), Analytics (a visual tool for seeing what is going on inside a cluster), and RTM (short for report, track, and monitor and including dashboards and reporting functions). Two other modules in development for release in December as add-ons to LSF include Dynamic Cluster and Session Scheduler; the Application Center Web-based portal for interfacing with LSF is also a separate product, and it includes pre-baked templates for popular HPC applications.
The new LSF V8.3 stack is certified to run on and control various x86 machinery as well as on IBM's own Power Systems servers running either AIX or Linux.
IBM is also rolling out a new V8.3 update to Platform's messaging passing interface (MPI) stack for HPC clusters. The new release has a bunch of nips and tucks to boost the performance of applications running on parallel supercomputer clusters, and it is not tied in any way with the LSF scheduler.
It works fine with Altair's PBS Pro, Grid Engine (in its many variants), the open source SLURM scheduler, or other schedulers and resource managers. Platform MPI V8.3 supports Ethernet, InfiniBand, and Myrinet interconnects on clusters, and supports remote direct memory access (RDMA) acceleration on InfiniBand and Ethernet as well as the new GPUDirect RDMA extensions that Nvidia has added with its latest Tesla K10 and K20 GPUs.
The MPI stack runs on server nodes equipped with Red Hat Enterprise Linux 4, 5, and 6; SUSE Linux Enterprise Server 10 and 11; CentOS 5, or Windows Server 2003 or 2008 (including the HPC Edition). GNU, Intel, PathScale, and Portland Group compilers all know how to speak Platform MPI.
In addition to the reworked LSF and MPI software, IBM is previewing new versions of Platform HPC 3.2, the cluster management bundle that it is aiming at smaller clusters and will bundle with its own System x and BladeCenter servers.
IBM is also cooking up a new release of Platform Cluster Manager, the open source entry cluster management stack that is presumably based on LSF Standard Edition. (IBM has not said.) It also didn't say very much about these forthcoming releases, but apparently there will be a Platform Cluster Manager Advanced Edition aimed at helping companies create multi-tenant HPC "clouds," and by cloud IBM means grid, not virtualized server instances.
If you are having a hard time keep track of what is what in the Platform lineup, here's a cheat sheet:
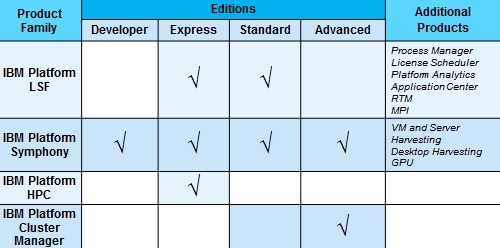
IBM's Platform Computing HPC editions
Presumably over time, IBM will flesh this grid out, as it has done with its Symphony grid middleware for Java applications. It is not clear what IBM did with Infrastructure Sharing Facility (ISF), which is a variant of LSF that was created explicitly for managing virtual server instances in clouds. IBM's own site makes no mention of it in its search engine.
Dances with elephants
Speaking of Symphony, Platform was just getting ready to shim a Hadoop-compatible MapReduce stack on top of Symphony, which it said was far better and more efficient than the open source Hadoop and its Hadoop Distributed File System, when Big Blue bought the company.
The batch-oriented LSF was built for scale, not for speed and certainly not for running Java messaging applications that are the backbone of financial services organizations, doing Monte Carlo simulations, risk analytics, and pricing algorithms for financial instruments. That's what Symphony was created for.
Back in May 2011, the then-independent Platform had embiggened the grid size with the Symphony 5.1 release and had previewed a variant of Symphony called Platform Workload Manager for MapReduce, which supported all of the MapReduce APIs in the Hadoop stack, but ran the actual Mapping and Reducing on top of Symphony, which is wickedly faster than the real Hadoop, according to Platform.
With Symphony 5.2, IBM is rolling this MapReduce support into the core product instead of making it a standalone product as Platform was going to do, Muelhoefer tells El Reg. Symphony is also being broken into a bunch of different editions, thus:
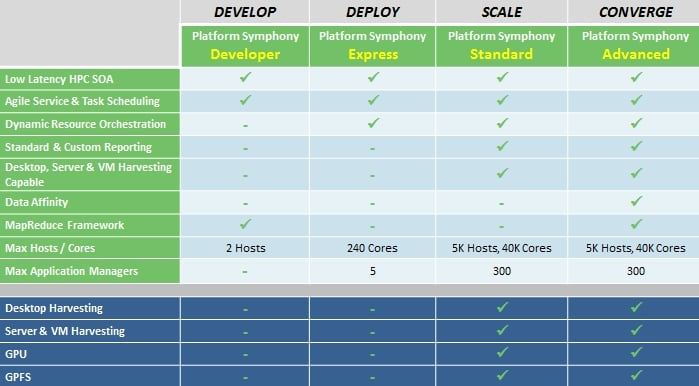
Editions of IBM's Symphony Java grid software (click to enlarge)
The MapReduce functions are only going to be available in the Developer and Advanced Editions. The Advanced Edition also includes the data affinity function that Platform had previously added to the Synphony stack, which moved computational work to where the data is rather than moving the data to where the free compute cycles are in a cluster. (MapReduce has a similar protocol, by the way.) This is a dot release of the Symphony code, and the software still scales to 10,000 cores per application and 40,000 cores per cluster, as the Symphony 5.1 release did.
Symphony schedules jobs to run on cores in milliseconds, compared to the seconds or minutes it takes with LSF, and can handle as many as 400 million tasks per day. The kind of performance that NASDAQ could have used on the day Facebook went public. (Hopefully, NASDAQ is not a Symphony reference account.)
The rejiggered LSF V8.3, Platform MPI V8.3, and Symphony 5.2 software will all be available on June 15. Pricing information was not available at press time.
Stack it up and cluster it
In a related announcement, IBM's supercomputer whizzes have also updated the Intelligent Cluster pre-fabbed HPC cluster stacks with a slew of new hardware, including the rejigged Platform Computing software and new servers, storage, and switches from IBM and its partners.
The stacks, known as the Intelligent Cluster 12B release, are not hard bundles so much as a la carte menus that customers can pick from and have IBM use to build a prefabbed cluster and drop it onto your loading dock. The latest bundles include IBM's own iDataPlex dx360 M4 servers, which have been refreshed with Intel's latest Xeon E5-2600 processors and Nvidia's latest Tesla K10 GPU coprocessors. The clusters can also be made from the System x3750 (four-socket Xeon E5-2600) or x3630 (two-socket Xeon E5-2400) servers, or the BladeCenter HS23 blade server (two-socket Xeon E5-2600).
IBM is bundling in its own RackSwitch G8316 (40GE), G8264 (10GE), and G8124E (Gigabit) switches and its forthcoming Platform HPC 3.2 for System x Express Edition and Platform Cluster Manager Advanced Edition to the stack, as well as its Global Parallel File System 3.5A. Ethernet switches from Brocade Communications and InfiniBand switches and adapters from Mellanox Technologies are options in the 12B HPC stacks, as is DataDomain Networks' SFA12K InfiniBand storage controller.
The Intelligent Cluster 12B stacks also can be the heart of finished stacks that IBM's factory can slap together to run pre-integrated application software such as IBM's own SmartCloud stack or SAP's Business Warehouse or HANA in-memory appliance.
There are also solution reference architectures (cookbooks instead of ready to eat) for the 12B iron, including IBM's own BigInsights variant of Hadoop, Schlumberger Eclipse (for petroleum exploration) mpiBLAST (for life sciences), ANSYS Fluent (for auto and aerospace manufacturing), Autodesk Vault (CAD/CAE), and OpenStack private and public clouds.
The Intelligent Cluster 12B stacks will be ready to roll on June 20. ®