Original URL: https://www.theregister.com/2011/10/03/oracle_big_data_appliance/
Oracle rolls its own NoSQL and Hadoop
A supremely confident Ellison mounts the Big Data elephant
Posted in SaaS, 3rd October 2011 20:22 GMT
OpenWorld There's no shortage of ego at Oracle, as evidenced by the effusion of confidence behind the company's OpenWorld announcement of the not-so-humbly named Big Data Appliance.
And then there were the o'erweening keynote presentations by some of the software giant and systems player's top brass on Monday, which included a montage of what Oracle has done so far this year, and hints at things ahead, and which ended with co-president and CFO Safra Catz intoning: "We are big data. And we're also the cloud."
Well, with Oracle owning big chunks of the database, middleware, application, and operating system markets, Catz's pronouncement settles any doubt about the future of information technology and Oracle's place in it. Just send your checks and surrender terms to Larry Ellison care of Oracle, 500 Oracle Parkway, Redwood Shores, CA 94065.
But before Oracle swallows the entire IT market, it has to prove that it actually is big data. Or, more precisely, that its engineered systems can do the kind of MapReduce work that enterprises are increasingly using to cope with their unstructured data.
And so Oracle is creating yet another engineered system to put in its arsenal of things for its direct sales force to sell: the Big Data Appliance.
Although Thomas Kurian, executive vice president of product development, announced the Big Data Appliance as part of his keynote in the wake of some brief peppy talk by co-president Mark Hurd, details are a little sparse. Conceptually, here's what the Big Data Appliance looks like:
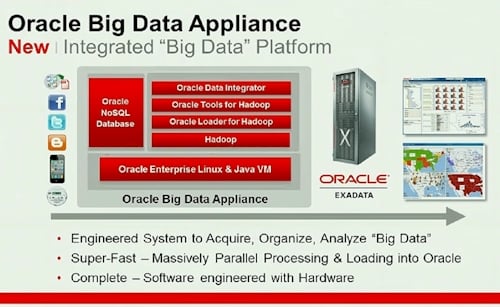
Block diagram of Oracle's Big Daddy, er Data, Appliance
The underlying hardware for the Big Data Appliance is Oracle's Exadata x86 clusters, which support a parallel implementation of the Oracle 11g R2 database running on top of Oracle's RHEL-ish clone of Linux. Oracle Enterprise Linux and Oracle's twist on the open source Xen hypervisor are the appliance's underlying layer.
Oracle is grabbing the open source Hadoop MapReduce tool from the Apache Software Foundation and doing its own distribution for this specific machine; Hadoop is a Java program and runs atop Oracle's own JVMs in the Exadata.
Kurian did not say if Oracle was using the HDFS file system that is normally paired with Hadoop. He had very little to say about the Oracle NoSQL Database, which is a distributed key-value store, although Oracle's announcement predictably says that it is "easy to install, configure and manage, supports a broad set of workloads, and delivers enterprise-class reliability backed by enterprise-class Oracle support."
The announcement, however, neglects to explain, as did Kurian, exactly what Oracle's NoSQL Database is. The company's sparse page outlining the NoSQL Database says that it "scales horizontally to hundreds of nodes with high availability and transparent load balancing."
Only two weeks ago, in a conference call with Wall Street analysts going over Oracle's first quarter financial results for fiscal 2012, Ellison, the company's cofounder and CEO, didn't seem to think that Oracle needed any other kind of database for dealing with unstructured data.
"Oracle has always stored both structured and unstructured data. This is really nothing new. We are constantly adding features to our database to support the storage and searching of unstructured as well as structured data. Autonomy was a shock to us," he said at the time, referring to the company that HP is in the process of buying for $10.3bn for its expertise in coping with unstructured data.
"We looked at the price and thought it was absurdly high," Ellison continued. "We had no interest in making the Autonomy acquisition. We think we're much better off with a couple of smaller acquisitions and continuing to innovate in that area so that the unstructured data and the structured data both find their way into an Oracle database, where it's secure, it's scalable, it runs on Exadata. We think we really don't want to have two separate databases."
Listen, my children, and you shall hear...
Ellison then gave a brief history of the database business, explaining that first there were relational databases, then object relational databases, and now we need to cope with unstructured data.
He neglected to point out, however, that Oracle has a collection of databases that rivals those from IBM (in number, if not in functionality), including the Essbase and TimesTen databases that are now at the heart of its new Exalytics BI appliance, announced yesterday, plus MySQL, Berkeley DB, and rdb from the Alphas and VAXes.
Oracle is not adverse to adding a NoSQL database to the collection, but Ellison sure gave the impression that what the company wanted to do was keep everything inside of the Oracle database – by which he meant 11g R2. As it turns out, Oracle's NoSQL is based on the Berkeley DB key/value database, Oracle confirmed separately today.
The Big Data Appliance stack also includes the Oracle Data Integrator Application Adapter for Hadoop, which links the NoSQL database and the Oracle database to applications, and Oracle Loader for Hadoop, which transforms datasets created by MapReduce-crunching into formats that are native to Oracle databases so they can be sucked into 11g R2.
Although the chart above doesn't show it, the Big Data Appliance also includes the R programming language, a popular open source statistical-analysis tool. This R engine will integrate with 11g R2, so presumably if you want to do statistical analysis on unstructured data stored in and chewed by Hadoop, you will have to move it to Oracle after the chewing has subsided.
This approach to R-Hadoop integration is different from that announced last week between Revolution Analytics, the so-called Red Hat for stats that is extending and commercializing the R language and its engine, and Cloudera, which sells a commercial Hadoop setup called CDH3 and which was one of the early companies to offer support for Hadoop. Both Revolution Analytics and Cloudera now have Oracle as their competitor, which was no doubt no surprise to either.
In any event, the way they do it, the R engine is put on each node in the Hadoop cluster, and those R engines just see the Hadoop data as a native format that they can do analysis on individually. As statisticians do analyses on data sets, the summary data from all the nodes in the Hadoop cluster is sent back to their R workstations; they have no idea that they are using MapReduce on unstructured data.
Oracle did not supply configuration and pricing information for the Big Data Appliance, and also did not say when it would be for sale or shipping to customers. The company did say that it would sell the individual software components in the appliance separately, as it does for other elements of its engineered systems. ®