Original URL: https://www.theregister.com/2011/06/30/seamicro_hadoop_benchmark_test/
Atom smasher claims Hadoop cloud migration victory
Big-data love in the datacenter
Posted in Channel, 30th June 2011 00:36 GMT
Commodity servers running big CPUs with fat cores are not necessarily the best at running the Hadoop. Just ask the bunch of customers who have bought Atom-smasher micro servers from SeaMicro to crunch their big-data workloads.
SeaMicro has been peddling its SM10000-64 micro server, based on Intel's dual-core, 64-bit Atom N570 processor and cramming 256 of these chips into a 10U chassis.
The machine includes an integrated load balancer, an internal network switch that links the server nodes into a 3D torus (like supercomputers use), a slew of Gigabit Ethernet or 10 Gigabit Ethernet uplinks to the outside world, and 64 disk drives for the server nodes to store data upon. The SM10000-64 is not so much a micro server as a complete data center in a box, designed for low power consumption and loosely coupled parallel processing, such as Hadoop or Memcached, or small monolithic workloads, like Web servers.
SeaMicro is beating its chest about the fact that online match-maker eHarmony has recently switched from running its people-matching algorithms out there on a service provider's cloud to SM10000-64 machines running in its own data centers. eHarmony didn't say what cloud provider it used, but according to SeaMicro co-founder and chief executive Andrew Feldman, running the matching algorithms against the 29 different criteria in an eHarmony account against the combined user base of over 33 million lonely people looking for love in the right place, took too long and never ran at the same speed on the cloud.

SM10000-64 plus eHarmony: Love at first byte.
The matching job done in Hadoop could take three to five hours, with the time varying depending on how busy the cloud was at any given time. And that unpredictability caused a logjam in the rest of eHarmony's applications, which are dependent on the results of these matching algorithms. Feldman was not at liberty to say how much faster the eHarmony matching algorithms run on the SM10000-64 machines, but tells El Reg that SeaMicro was able to "dramatically reduce the time it took to do the job". And by moving off the cloud, eHarmony has been able to cut its processing costs compared to what it was paying on the cloud by 74 per cent. Those cloud data upload charges sure do mount up, eh?
Sounds to us like it is time for someone to start a Hadoop cloud based on SeaMicro machines and with guaranteed service levels.
Feldman jokes that the eHarmony deal is the largest Hadoop implementation that SeaMicro is able to talk about, which suggests there are some government agencies with three-letter acronyms that are messing around with the micro servers.
On another Hadoop-related deal that SeaMicro won, the company can't talk about who the customer was but can talk about the benchmarking process it used to win the deal and what the results were.
At this customer site, the Hadoop job had to complete in 10 minutes and 50 seconds or less. The SeaMicro Atom-smasher was positioned against racks of Intel Xeon servers; both sets of machines ran the CentOS 5.4 clone of Red Hat Enterprise Linux and the Cloudera Hadoop distribution (CDH3 to be precise).
SeaMicro set up an SM10000-64 configuration that could do the Hadoop chew job in the allotted time and then kept adding Xeon boxes to the Xeon cluster until it got in under the allotted time. This benchmark ran the customer's applications using real customer data.
Power consumption was measured using Xitron 2801 power meters and aggregating the power consumption from the servers using National Instruments' LabView 7.1 graphical tool. Here's how the machines stacked up:
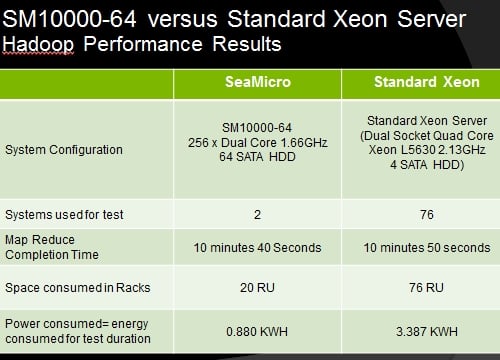
SeaMicro Atom vs Xeon cluster on Hadoop data chewing
To get the job done in the customer's Hadoop calculation batch window, it took two whole SM10000-64 servers, each with 64 SATA disks and 512 cores running at 1.66GHz. Actually, the SeaMicro setup did it with 10 seconds to spare. This occupied 20U of space, or a little less than a half of a standard server rack, and consumed 880 watt-hours of juice during the run. Each chassis costs $140,000 at list price, so you are looking at $280,000 for this setup.
It took 76 1U rack servers, each equipped with two quad-core Xeon L5630 low-voltage processors running at 2.13GHz to do the Hadoop job. Each server had four SATA disks, for a total of 304 disk drives, a lot more than the 128 required for the SeaMicro machine.
Hadoop servers generally have at least six drives to avoid I/O contention and customers are increasingly moving to even higher disk drive counts these days. In any event, the Xeon setup running the customer workload filled nearly two racks and consumed 3,387 watt-hours of electricity during its 10 minute and 50 second run.
The SeaMicro machine did the job in one quarter of the rack space and burning one quarter of the juice.
To get a sense of what the Xeon solution would cost, I configured a ProLiant DL160 G6 server with two Xeon L5630 processors, 8GB of memory, and four 500GB disks, and that works out to $4,270 each. Just for the bare servers, you are in for $324,520, and you need to buy a couple of switches to lash them together. The operational costs will also play into the favor of the SeaMicro setup.
Intel will be crowing that it doesn't care whether customers use Atoms or Xeons, but the funny thing about the SeaMicro architecture is that it doesn't care about what processors it uses, either. It could turn out to be ARM or Tilera chips if the Atom roadmap is not aggressive enough in the future. ®