Original URL: https://www.theregister.com/2011/03/29/platform_computer_symphony_mapreduce/
Platform wants to out-map, out-reduce Hadoop
Teaching financial grids to dance like stuffed elephants
Posted in Channel, 29th March 2011 12:06 GMT
Chewing on big data using the MapReduce protocol, and the open source Hadoop stack that implements it, is all the rage these days. But there is more than one way to stuff an elephant.
The Hadoop tool created by Yahoo! (and named after a stuffed elephant) is now managed by the Apache Software Foundation, and it is the tool of choice for running MapReduce algorithms against unstructured data. Platform Computing, the pioneer of grid computing that has been plying the HPC racket for two decades, says it has created a better way to run MapReduce algorithms against big data: Plunk it on Platform's Symphony financial grid software.
Platform has not ported Hadoop to the Symphony tool or somehow split open its code and shimmed chunks of Hadoop into Symphony, explains Ken Hertzler, vice president of product management at the company. Instead, Hertzler tells El Reg, Platform has grabbed the Hadoop MapReduce APIs, which are written in Java just like Hadoop and Symphony are, and embedded support for the MapReduce APIs into Symphony.
Ditto for the APIs for Pig, the programming language created for Hadoop and analogous to SQL for a relational database (but not SQL-like), and the APIs for Hive, which is a query language for Hadoop that actually offers commands similar to SQL for those who want to extract data out of their mapped and reduced unstructured data.
To support applications written for Hadoop, Platform is adding support for the Hadoop Distributed File System (HDFS) underneath Symphony, and is still allowing for IBM's General Parallel File System (GPFS) and Appistry's CloudIQ Storage clustered file system to plug into Symphony. The Platform MapReduce product is being rebranded as the Platform Workload Manager when it is tweaked to support MapReduce code. Here's what it looks like conceptually:
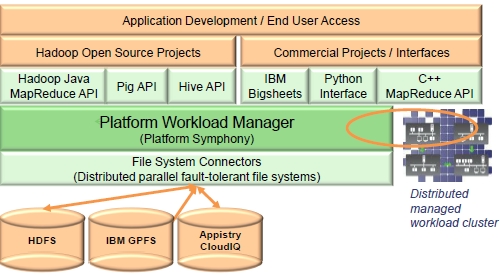
Platform runs MapReduce code on Symphony
Platform also wants to support commercial MapReduce projects and inferfaces, including IBM's Bigsheets and Python and C++ interfaces for the MapReduce APIs.
Symphony, if you are not acquainted with it, was created by Platform nine years ago because financial services firms that were trying to use its Load Sharing Facility (LSF) to run risk arbitrage applications were very unhappy with the sluggish performance and scale of that gridding software for running time-sensitive workloads. While LSF is good at managing the workflow of multiple HPC jobs on a supercomputing cluster, it was not designed to run one or a few jobs at low latency and high throughput. So Platform gutted LSF and created Symphony from scratch in the Java programming language. And over the years, it has ramped up the scalability of Symphony so it can span lots of cores.
There are a number of problems besides scalability that Platform is trying to address by support the Hadoop/Pig/Hive API stack on top of Symphony. The first is workload management for MapReduce applications.
"In the current Hadoop distro, it is one job at a time," Hertzler tells El Reg. "You need to add distributed cluster logic to manage multiple MapReduce jobs at the same time on the same cluster." Or, use multiple Hadoop clusters, as Yahoo! does. "But Symphony is already a distributed workload manager and knows how to distribute data and work around a cluster."
Platform is also pitching the fact that using Symphony to run MapReduce workloads gives customers a choice of file systems for their MapReduce workloads.
"We're not tied to any file system," says Hertzler. "We plan to open it up so customers can attach to any existing file system."
Why would Platform do that?
Why would Platform do that? Because companies are already generating and storing data in their file systems and they don't want to port their data from one file system to HDFS. Then they have a data porting problem every time they want to run a job. Platform says it makes much more sense to chew on the big data where it sits and in whatever format it is encoded in. That said, Hertzler concedes that this may not always yield the best performance for a MapReduce job even if it is the easiest way to do it.
If you have never heard of Platform Symphony, Version 5 of the tool was announced in November 2009 and it sported this neat feature called data affinity. Instead of moving data around of clusters in a machine to computing elements to perform calculations, the Symphony scheduler figured out where the data is and dispatches the much smaller program code to the node with the data on it and has it chew on the data. On certain calculations popularly used in the financial services space where Symphony is used, applications can speed up by an order of magnitude by moving code instead of data around the cluster.
Symphony 5 spans up to 20,000 cores in a single cluster running as many as 5,000 cores per application. Symphony has multicore optimizations to make jobs run more efficiently on modern processors, with all of their cores and threads, and has a feature called MultiCluster that allows multiple Symphony grids to be managed as a single resource pool. This last feature allows for work to be spread across multiple clusters. The kind of thing, says Hertzler, that Hadoop users are wrestling with right now as they have multiple clusters running multiple jobs, Symphony can already do.
Platform is not talking much about how well Symphony will run MapReduce applications using its implementation of the Hadoop, Pig, and Hive APIs, and that is because the Platform MapReduce Workload Manager is still being tweaked. In some cases, the Symphony MapReduce functionality is faster than Hadoop on the same iron, and it never performs slower, according to Hertzler.
"When it comes to the Java execution engine, we are really far ahead of Hadoop," he says, saying that financial institutions using Symphony for their risk analysis are running their programs in under 100 milliseconds ahead of trades. "Performance is important, but companies have service level agreements, and as they roll MapReduce workloads into production, they want a product that has been around for a while and that can deliver on them."
Platform has a few proof of concept customers testing MapReduce support for Symphony right now and will roll out the product later in the summer. The company says in its presentation for the MapReduce support that it will be able to put 40,000 cores in a single Symphony cluster and allocate as many as 10,000 cores to a single applications, and that is twice what Symphony 5 can do. (I guess we know what Symphony 6 will look like.) The future Symphony release will be able to process 17,000 tasks per second with what Platform says is "extremely low latency" of under 1 millisecond.
The company will not be open sourcing Symphony or the MapReduce support code it has created, just as it has kept the most recent versions of its LSF product closed source. (The company did open up an earlier release of its LSF tool to foment the Lava cluster management tool, however.)
The one thing that the Symphony MapReduce release will also have is a price tag that is significantly higher that the free and open source stack. Without the MapReduce functionality, Symphony 5 costs $250,000 for a 100-node cluster, and scales up to millions of dollars for licenses. ®