Original URL: https://www.theregister.com/2010/09/22/google_books_crowdsource/
Google crowdsources card index for 'humanity's last library'
Garbage in, garbage out
Posted in Legal, 22nd September 2010 12:15 GMT
Google has responded to criticism of the quality of its books metadata - by inviting anyone to write anything they want. Before you read on, remember that Google Books could become the world's digital library by default - it's been called "the last library" - since nobody is likely to do the scanning ever again.
However, for researchers and scholars, a collection is only as good as its metadata - and the quality of the metadata at Google Books falls far short of any library in history. Last year Stanford linguist and columnist Geoffrey Nunberg writing in the Chronicle of Higher Education described the errors as "disastrous".
Nunberg found that potentially hundreds of thousands of books were misdated, with titles credited to authors before they were born. Google Books showed books from Victorian era discussing Jimi Hendrix, or the microprocessor, for example.
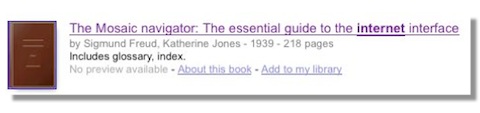
Freud had strong views on web browsers
Attribution errors commonly miscredited authors, with Madame Bovary credited to Henry James. And bizarre classification errors abound. A Mae West biography was filed under Religion, for example. Jane Eyre showed up under Love Stories, Architecture, and Antiques and Collectables. And on top of this mass of errors, was a superstructure of erroneous links. Google's "related books" rarely point to anything related.
In short, if this is humanity's last ever library, humanity's last ever scholars won't get very far with their research.
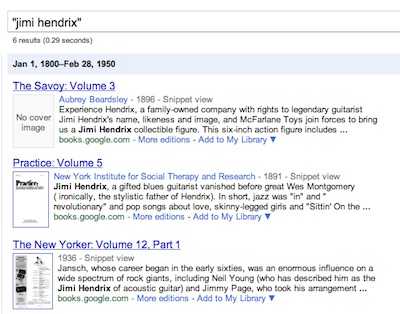
"Our reputation precedes us" - The Victorians discuss Jimi Hendrix
(We've also highlighted problems due to lack of care and attention at Google Books here.)
When Salon revisited Google Books earlier this month, things hadn't improved. And worse, the answer to 'garbage out' is 'more garbage in' - crowdsourcing.
A Google engineer called "SofiaF" now invites us to nominate books that are out of print. They're only suggestions, but given that none of us are as dumb as all of us, can we expect the quality of the metadata to improve? As with classification, knowing the copyright status of a work requires expertise, particularly the intricacies of territorial copyright. It's not something a helpful amateur with time on their hands can usefully do.
For Nunberg, Google's haste to complete the project is the problem - it prefers to get it finished, for competitive reasons, rather than devote expert resources to getting it right.
"People at Google are also saying, 'Let's crowdsource this,' but that is a stupid idea. You and I are both smart, knowledgeable people, but I wouldn't trust either of us to do the skilled work of cataloging a 1890 edition of Madame Bovary," Nunberg told Salon.
He suggests that Google devote more expert resources to the problem - which is expensive - and that librarians, who have up until now trusted Google Books to get it right, become more feisty and pro-active. ®
Related link
Google Book errors, illustrated [PDF, 1.6MB]