Original URL: https://www.theregister.com/2010/07/23/ibm_z196_mainframe_processor/
IBM's zEnterprise 196 CPU: Cache is king
'The fastest CPU in the world.' And more
Posted in HPC, 23rd July 2010 14:02 GMT
Analysis IBM is a funny technology company in that its top brass doesn't like to talk about feeds and speeds and seems to be allergic to hardware in particular. Which is particularly idiotic for a hardware company that sells servers, storage, and chips.
Thursday, in launching the new System zEnterprise 196 mainframe, IBM didn't say much about the feeds and speeds of the new quad core processor at the heart of the system. About the only tech talking point the company offered was that the new machine's processors ran at 5.2 GHz, making it "the fastest microprocessor in the world."
Well, yes, if you are looking at raw clock speed alone. But there is more to this z196 processor than fast clocks and more to any system than its cores.
The quad-core z196 processor bears some resemblance to the 4.4 GHz quad-core z10 processor it replaces in the System z lineup. The z196 processor is implemented in a 45 nanometer copper/silicon-on-insulator process (a shrink from the 65 nanometer processes used in the z10 chip), which means Big Blue could cram all kinds of things onto the chip, and it did just that. Much as it did with the eight-core Power7 chips announced in February.
The z196 processor has 1.4 billion transistors and weighs in with 512.3 square millimeters in real estate, making it a bit larger than the Power7 chip in both transistor count and area. The z196 chip uses IBM's land grid array packaging, which have golden bumps called C4 instead of pins. The z196 processor has a stunning 8,093 power bumps and 1,134 signal bumps.
Each core on the z196 chip has 64 KB of L1 instruction cache and 128 KB of L1 data cache, just like the z10. The cores are very similar, except that the z196 has 100 new instructions to play with and some tweaks to the superscalar pipeline allows for instructions to be reordered in ways that makes the pipeline more efficient than the z10 but in a way that is invisible to compiled code. Each core has 1.5 MB of its own L2 cache as well. Take a look at the chip below:
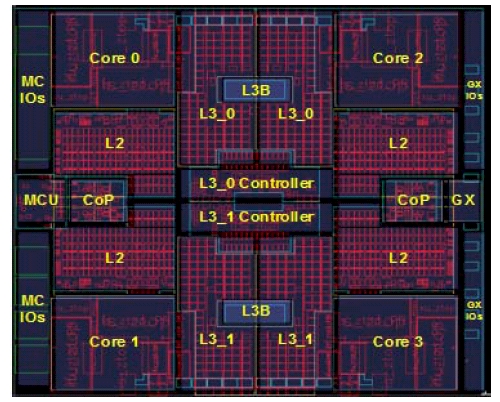
IBM's z196 mainframe processor
The z196 engine's superscalar pipeline can decode three z/Architecture CISC instructions per clock cycle and execute up to five operations per cycle. Each core has six execution units: two integer units, one floating point unit, two load/store units and one decimal (or money math) unit. IBM says that the floating point unit has a lot more oomph than the one used in the z10 chip, but did not say how many flops it could do per clock. Some of the prior z/Architecture CISC instructions have been busted into pieces, allowing for them to be spread across the pipeline more efficiently and making the z196 a bit more RISCy.
Like the Power7 chip, the z196 implements embedded DRAM (eDRAM) as L3 cache memory on the chip. Which this eDRAM memory is slower than static RAM (SRAM) normally used to implement cache memory, you can cram a lot of it onto a given area. For many workloads, having more memory closer to the chip is more important than having fast memory. The z196 processor has 24 MB of eDRAM L3 cache memory, which is split into two banks and managed by two on-chip L3 cache controllers.
Each z196 chip as a GX I/O bus controller - the same as is used on the Power family of chips to interface with host channel adapters and other peripherals - and a memory controller that interfaces with the RAID-protected DDR3 main memory allocated to each socket. Each z196 chip also has two cryptographic and compression co-processors, the third generation of such circuits to go into IBM's mainframes.
Two cores share one of these co-processors, which have 16 KB of their own cache memory. Finally, each z196 chip has an interface to a SMP Hub/shared cache chip. Two of these chips, which are shown below, are put onto each z196 multichip module (MCM), and they provide the cross-coupling that allows all six sockets on the MCM to be linked to each other with 40 GB/sec links.
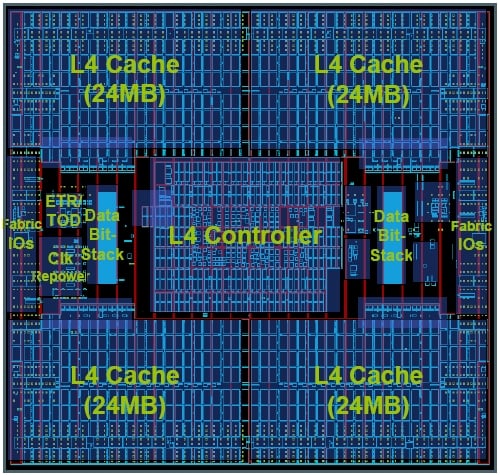
The zEnterprise 196 SMP hub/shared cache
In the IBM mainframe lingo, the z196 processing engine is a CP, or central processor, while the interconnect chip for the CPs is called the SC, short for shared cache. Each SC has six CP interfaces to link to each of the CPs and three fabric interfaces to link out to the three other MCMs in a fully loaded z196 system.
What's neat about this SMP hub is that it is loaded to the gills with L4 cache memory, which most servers do not have. (IBM added some L4 cache to its EXA chipsets for Xeon processors from Intel a few years back). This L4 cache is necessary for one key reason, I think: the clock speed on the mainframe engine is a lot higher than main memory speeds, and only by adding another cache layer can the z196 engines, which are terribly expensive, be kept fed. Anyway, this SMP Hub/shared cache chip is made in the same 45 nanometer processes as the CPs, and weighs in at 1.5 billion transistors and 478.8 square millimeters of real estate. It has 8,919 bumps in its package, so to speak.
Six CPs and two SCs are implemented on each MCM, which is a square that is 96 millimeters on a side, which dissipates 1,800 watts. Each processor book has one of these MCM puppies, and a fully connected system has 96 CPs, a dozen memory controllers able to access up to 3 TB of RAID memory, and up to 32 I/O hub ports with a maximum of 288 GB/sec of I/O bandwidth. Up to 80 of the CPs in the top-end zEnterprise 196 M80 machine can be used to run workloads; others are used for coupling systems together using Parallel Sysplex clustering, managing I/O, hot spares, and such. ®