Original URL: https://www.theregister.com/2010/05/25/cray_xe6_baker_gemini/
Cray launches Gemini super interconnect
Last Baker system component revealed
Posted in HPC, 25th May 2010 10:13 GMT
The final piece of Cray's "Baker" XE6 massively parallel supercomputers, on which the company's financial 2010 hinges, make its debut today.
The unveiling comes a week ahead of the International Super Computing conference in Hamburg, Germany, and at Cray's user group meeting in Edinburgh, Scotland.
Cray has not said much publicly about what is perhaps the key piece of technology in the Baker systems, which would be the "Gemini" XE system interconnect. That's because Cray can't afford to make promises it cannot deliver upon and electronic components are notoriously hard to bring to market on time and with the performance that high-end customers like the world's largest supercomputer labs expect.
Cray got burned for many quarters three years ago with delays by Advanced Micro Devices in bringing its quad-core "Budapest" Opteron 2000 processors to market for the XT4 systems. Then-new Cray chief executive officer, Peter Ungaro, had to cope with revenue declines in the wake of the delays, and he doesn't want to repeat that nightmare again.
But in recent months as Cray has reported its financial results, Ungaro has been sounding more and more optimistic about the Gemini interconnect while always couching everything he says with reminders that the ASIC that makes up the Gemini interconnect could still have bugs that won't be found until final testing, which could force tweaking of the chip design and another round of fabbing and testing. This would pushing out sales by one or two quarters, and basically doing a repeat of the Budapest fiasco.
The fact that Cray is talking about Gemini and has launched over $200m in deals so far that have Baker machines for at least part of the deal means that Gemini is coming along. But you won't hear Cray sounding cocky about that until it is in the field and systems using the interconnect have passed muster at the US super labs and generated revenues and profits.
According to Barry Bolding, vice president of scalable systems at Cray, the Baker supers were originally designed as an integrated system featuring a new style of cabinet featuring a phase-change liquid cooling exchanger to suck heat out of the racks; the use of AMD's G34-socket Opterons in a blade sporting four two-socket servers on a single blade; a new Linux environment that masked the proprietary system interconnect from Linux and the parallel applications that run atop it, and a new high-speed interconnect. The Baker systems had a kind of fluid delivery schedule, but were originally due around 2009.

The Cray XE6 blade: Two Gemini interconnects on the left (which is the back of the blade), with four two-socket server nodes and their related memory banks
After the Budapest fiasco (that's El Reg's words, not Bolding's), Cray decided to break the Baker system into bits and pieces and go modular, rolling out what it could when it could instead of doing a big bang system. So the funky Baker cabinets came out with the XT5 machines as the Ecophlex.
The Opteron G34-based blades were previewed last fall as the XT6 blades, sporting the SeaStar2+ interconnect instead of the Gemini interconnect, which conveniently slot into the same physical space on the blades. As soon as AMD had the 12-core "Magny-Cours" Opteron 6100s ready in March, Cray started shipping XT6 blades rather than waiting another six months or so for the Bakers to be whole and complete.
The third generation of the Cray Linux Environment, a goosed version of Novell's SUSE Linux Enterprise Server 11 that was originally expected only on Baker boxes and their Gemini interconnect, made its debut last month sporting a neat new feature called Cluster Compatibility Mode. With the CCM feature, the SeaStar interconnect (and now also the Gemini interconnect) has been equipped with drivers that make Linux think it is talking to an Ethernet networking instead of SeaStar or Gemini, which is a very different kind of animal.
Right now, the CCM feature of Cray Linux Environment 3.0 is supported on XT6 and XT6m mini variants and only emulating Ethernet, but will be backported to XT5 and XT5m machines later this year and to XT4 machines in early 2011; eventually, CCM will be able to emulate InfiniBand as well, if your HPC apps prefer that.
Which brings us all the way up to the Gemini interconnect that completes the Baker XE6 systems.
The Gemini interconnect is half-way between the current SeaStar family of interconnects (SeaStar in the XT3, SeaStar2 in the XT4, and SeaStar2+ in the XT5) that the US government footed the bill for through various projects and a future hybrid computing system code-named "Cascades." The Cascades interconnect will support Xeon, Opteron, and other computing architectures, including Cray's MTA-2 processors, FPGAs (which Cray has shipped for years but which is not currently standard products as they were with the XT5 and earlier OctigaBay boxes), and very likely graphics co-processors.
Cray is being vague on the details behind Cascades. But what Bolding can say is that DARPA is paying for the research and development for Cascades and that one of the key elements of these systems is a brand new interconnect code-named "Aries", which will use PCI-Express links to lash processors to the interconnect rather than the HyperTransport links used with SeaStar and Gemini.
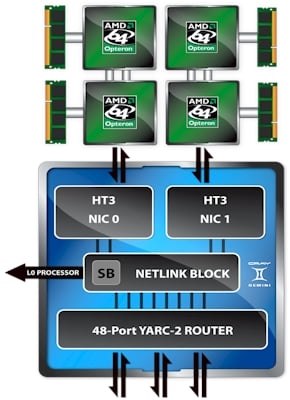
The architecture of the Cray Gemini interconnect
Why, you ask? Because Cray wants to be able to mix and match processors as it sees fit and not be screwed.
When the "Red Storm" Opteron-Linux massively parallel super was created for Sandia National Laboratories for delivery in late 2003, Intel's Xeon processors had the crappy frontside bus architecture and Opterons had that brand spanking new HyperTransport point-to-point interconnect. It took Intel until last year to get its equivalent of HyperTransport, called QuickPath Interconnect, to market in two-socket servers in the Xeon 5600s and only two months ago did larger server nodes (with more memory capacity) using the Xeon 7500s get QPI.
Opterons were the bomb in 2003, when they debuted, but Cray needs to keep its options open. So, says Bolding, the future Aries interconnect being put into Cascades systems will talk to PCI-Express instead of HT or QPI. (Which also seems to suggest that future Opteron and Xeon processors will have embedded PCI-Express circuits.)
But in the meantime, Cray needs to build and sell HPC iron today. So it took the high radix router that is being developed for DARPA under the Cascades contract and back-ported an early version of it to support HT3 links and the Opteron 6100 processors, thus creating the interconnect called Gemini. And so, Gemini is not getting its name from being two goosed SeaStar interconnects working side-by-side, as many have been speculating, including myself. It is a little more complex than that.
(By the way, DARPA is paying for the X64 portion of the Cascades system, and the initial machines will be based on Intel's Xeon processors. Bolding won't say whether Cray is or is not going to support Opterons with Cascades, but merely says Cray is "designing Cascades for flexibility" and that it "reserves the right to choose the best processor available at the time.")
The SeaStar interconnect took one HT link coming off a pair of Opteron processors and hooked it into a six-port router, with each port able to deliver 9.6 GB/sec of bandwidth. (The SeaStar is actually a bunch of chips, including the router, a blade control processor interface, a direct memory access engine, some memory, and the HT interface.) The HT2 links provided 25.6 GB/sec of bandwidth to memory on the two sockets of Opterons, 6.4 GB/sec of bandwidth from the processors out to the SeaStar2+ ASIC, and then six router ports running at 9.6 GB/sec each, implementing a 3D torus.
With Gemini, instead of one pair of Opteron chips linking into the Cray ASIC, there are two pairs and they link into the Gemini interconnect chip using HT3 links. And instead of having a dozen hard-coded pipes running at something north of 9.6 GB/sec, the Gemini chip has 48 skinnier ports that have an aggregate bandwidth of 168 GB/sec. Bolding says that four of these pipes, which are implemented using what is called a high radix YARC router with adaptive routing, can be used to make what amounts to a virtual network interface to talk to compute nodes.
The Gemini interconnect has one third or less the latency of the SeaStar2+ interconnect, taking just a hair above one microsecond to jump between computer nodes hooked to different Gemini chips, and less than one microsecond to jump from any of the four processors talking to the same Gemini. Perhaps more significantly, by ganging up many pipes using the high radix router, the Gemini chip can deliver about 100 times the message throughput of the SeaStar2+ interconnect - something on the order of 2 million packets per core per second, according to Bolding. (The amount will change depending on packet size and the protocol used, of course.)
That extra bandwidth means a lot more scalability. The Bakers, now formally known as the XE6 systems, will have at least four times the scalability of the current XT6 machines Cray is selling. "Because of this messaging rate, we think we can support a one million core system," says Bolding, which is about four times that of the current theoretical peak of the XT6/SeaStar2+ machines. And, Bolding adds, the theoretical scalability of the Baker machines is really on the order of around three million cores, assuming a 16-core "Interlagos" chip for next year. That's about 1,000 racks of server blades, which is about five times as many cabinets as in the 1.76 petaflops "Jaguar" massively parallel cluster running at Oak Ridge National Laboratory.
The XE6 is designed to scale from 100 teraflops up to multiple sustained petaflops, with a price tag starting at around $2m. There is not currently an XE6m midrange lineup, which will sport a 2D torus interconnect for smaller installations ranging from 10 teraflops to 100 or more teraflops, in a price range of $500,000 to $3m. But Bolding says there are plans to get an XE6m out the door eventually. Right now, the XT6m can do the job just fine.
Since the machines all implement the same 3D torus, you can swap out the SeaStar2+ interconnect on XT5 and XT6 machines and plug in the Gemini module and convert them into XE5 and XE6 machines. And, by choosing a 3D torus interconnect, that means the nodes in these upgrades systems do not have to be rewired, which is a requirement with many other supercomputer topologies.
In terms of power efficiency, the XT5 and XT5m machines delivered about 250 megaflops per watt, but the XT6 and XE6 machines will be 330 megaflops per watt or higher once they are put through the Linpack paces. Somewhere between 30 and 40 per cent improvement in energy efficiency is expected with the intial XT6 and XE6 boxes.
Another thing that Cray is adding back into its supers with the XE6 systems is global memory addressing, something that Cray machines have not had since the T3E super from 1995, which was based on the Digital Equipment Alpha 21164 processor. (Yes, DEC was a damned good engineering company.)
The T3E was the first machine to break the 1 teraflops barrier doing actual work. (I know about ASCI Red and its Linpack ratings.) The global address space in the XE6 is implemented in the Gemini chip and basically allows remote direct memory access (RDMA) from any node in the system to any other node in the system without having to go through the whole MPI stack to have nodes talk to each other.
This global address space is not as tight as the shared global memory that Silicon Graphics implements in NUMAlink 4 for its Itanium-based Altix 4700s or in NUMAlink 5 for its new Xeon 7500-based Altix UVs. Global shared memory in the SGI sense means there is only one copy of the Linux operating system and one address space for applications.
The global addressing based on RDMA that Cray is implementing in the XE6 provides a shared address space for applications, but each node in the cluster has its own copy of the Linux operating system. The "Blue Waters" massively parallel Power7-based super IBM is building for the University of Illinois has something akin to Cray's global addressing.
The global addressing means that applications running across a large number of nodes can be coded more easily than with MPI, but you have to use special languages like Unified Parallel C, Co-Array Fortran, Chapel (from Cray), or X10 (from IBM) to use it. The Cray X1 and X2 vector machines had global address spaces, and so too did the Quadrics interconnect, which is one reason why Duncan Roweth, one of the founders of the British HPC interconnect makers, took a job at Cray when Quadrics shut down a year ago. ®